
You are currently browsing the category archive for the ‘CM’ category.
 I am writing this post because one of my PLM peers recently asked me this question: “Is the BOM losing its position? He was in discussion with another colleague who told him:
I am writing this post because one of my PLM peers recently asked me this question: “Is the BOM losing its position? He was in discussion with another colleague who told him:
“If you own the BOM, you own the Product Lifecycle”.
This statement made me think of ä recent post from Jan Bosch recent post: Product Development fallacy #8: the bill of materials has the highest priority.
 Software becomes increasingly an essential part of the final product, and combined with Jan’s expertise in software development, he wrote this article. I recommend reading the full post (4 min read) and next browse through the comments.
Software becomes increasingly an essential part of the final product, and combined with Jan’s expertise in software development, he wrote this article. I recommend reading the full post (4 min read) and next browse through the comments.
If you cannot afford these 10 minutes, here is my favorite quote from the article:
An excessive focus on the bill of materials leads to significant challenges for companies that are undergoing a digital transformation and adopting continuous value delivery. The lack of headroom, high coupling and versioning hell may easily cause an explosion of R&D expenditure over time.
Where did the BOM focus come from? A historical overview related to the rise (and fall) of the BOM.
In the beginning, there was the drawing.
 Before the era of computers, there was “THE drawing”, describing assemblies, subassemblies or parts. And on the drawing, you can find the parts list if relevant. This parts list was the first Bill of Material, describing the parts/materials shown on the drawing.
Before the era of computers, there was “THE drawing”, describing assemblies, subassemblies or parts. And on the drawing, you can find the parts list if relevant. This parts list was the first Bill of Material, describing the parts/materials shown on the drawing.
Next came MRP/ERP
 With the introduction of the MRP system (Material Requirement Planning), it was the first step that by using computers, people could collect the material requirements for one system as data and process.
With the introduction of the MRP system (Material Requirement Planning), it was the first step that by using computers, people could collect the material requirements for one system as data and process.
Entering new materials/parts described on drawings was still a manual process, as well as referring to existing parts on the drawing. Reuse of parts was a manual process based on individual knowledge.
In the nineties, MRP evolved into ERP (Enterprise Resource Planning), which included the MRP part and added resource and manufacturing planning and financial reporting.
 The ERP system became the most significant IT system, the execution system of the company. As it was the first enterprise system implemented, it was the first moment we learned about implementation challenges – people change and budget overruns. However, as the ERP system brought visibility to the company’s execution, it became a “must-have” system for management.
The ERP system became the most significant IT system, the execution system of the company. As it was the first enterprise system implemented, it was the first moment we learned about implementation challenges – people change and budget overruns. However, as the ERP system brought visibility to the company’s execution, it became a “must-have” system for management.
The introduction of mainstream 2D CAD did not affect the company’s culture so much. Drawings became electronic drawings, and the methodology of the parts list on the drawing remained.
 Sometimes the interaction with the MRP/ERP system was enhanced by an interface – sending the drawing BOM to ERP. The advantage of the interface: no manual transfer of data reducing typos and BOM errors. The disadvantages at that time: relatively expensive (connectivity between systems was a challenge) and mostly one direction.
Sometimes the interaction with the MRP/ERP system was enhanced by an interface – sending the drawing BOM to ERP. The advantage of the interface: no manual transfer of data reducing typos and BOM errors. The disadvantages at that time: relatively expensive (connectivity between systems was a challenge) and mostly one direction.
And then there was PDM.
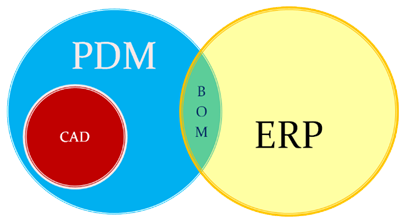 In parallel with the introduction of ERP systems, mainstream 3D CAD systems became affordable, particularly SolidWorks, Solid Edge and Inventor. These 3D CAD systems allow sharing of parts and assemblies in different products, and the PDM database was the first aid to support part reuse, versioning and standardization.
In parallel with the introduction of ERP systems, mainstream 3D CAD systems became affordable, particularly SolidWorks, Solid Edge and Inventor. These 3D CAD systems allow sharing of parts and assemblies in different products, and the PDM database was the first aid to support part reuse, versioning and standardization.
By extracting the parts from the assemblies and subassemblies, it was possible to generate a BOM structure in the PDM system to be transferred or typed into the ERP system. We did not talk about EBOM or MBOM then, as there was only one BOM in the ERP system, and the PDM system was a tool to feed the ERP system.
 Many companies still have based their processes on this approach. ERP (read SAP nowadays) is the central execution system, and PDM is an external system. You might remember the story and image from my previous post about people, processes and tools. The bad practice example: Asking the ERP system to provide a part number when starting to design a part.
Many companies still have based their processes on this approach. ERP (read SAP nowadays) is the central execution system, and PDM is an external system. You might remember the story and image from my previous post about people, processes and tools. The bad practice example: Asking the ERP system to provide a part number when starting to design a part.
And then products started to change.
 In the early 2000s, I worked with SmarTeam to define the E&E (Electronics and Electrical) template. One of the new concepts was to synchronize all design data coming from different disciplines to a single BOM structure.
In the early 2000s, I worked with SmarTeam to define the E&E (Electronics and Electrical) template. One of the new concepts was to synchronize all design data coming from different disciplines to a single BOM structure.
It was the time we started to talk about the EBOM. A type of BOM, as the structure to consolidate all the design data, was based on parts.
The EBOM, most of the time, reflects the design intent in logical groups and sending the relevant parts in the correct order to the ERP system was a favorite expensive customization for service providers. How to transfer an engineering BOM view to an ERP system that only understands the manufacturing view?
Note: not all ERP systems have the data model to differentiate between engineering parts and manufacturing parts
The image below illustrates the challenge and the customer’s perception. 
The automated link between the design side (EBOM) and manufacturing side (MBOM) was a mission impossible – too many exceptions for the (spaghetti) code.
And then came the MBOM.
The identified issues connecting PDM and ERP led to the concept of implementing the MBOM in the PLM system. The MBOM in PLM is one of the characteristics of a PLM implementation compared to a PDM implementation. In a traditional PLM system, there is an interaction and connection between the EBOM and MBOM. EBOM parts should end up as MBOM parts. This interaction can be supported by automation, however, as it is in the same system, still leaving manual changes possible.
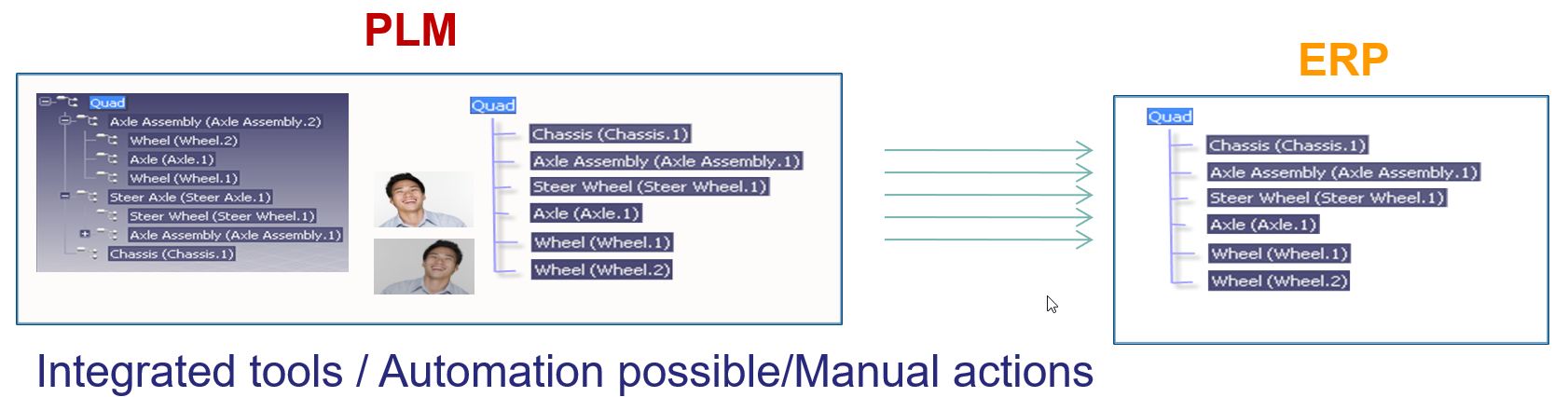
 The MBOM structure in PLM could then be the information structure to transfer to the ERP system; however, there is more, as Jörg W. Fischer wrote in his provoking post-Die MBOM muss weg (The MBOM must go). He rightly points out (in German) that the MBOM is not a structure on its own but a combination of different views based on Assembly Drawings, Process Planning and Material Requirements.
The MBOM structure in PLM could then be the information structure to transfer to the ERP system; however, there is more, as Jörg W. Fischer wrote in his provoking post-Die MBOM muss weg (The MBOM must go). He rightly points out (in German) that the MBOM is not a structure on its own but a combination of different views based on Assembly Drawings, Process Planning and Material Requirements.
His conclusion:
Calling these structures, MBOM is trying to squeeze all three structures into one. That usually doesn’t work and then leads to much more emotional discussions in the project. It also costs a lot of money. It is, therefore, better not to use the term MBOM at all.
And indeed, just having an MBOM in your PLM system might help you to prepare some of the manufacturing steps, the needed resources and parts. The MBOM result still has to be localized at the local plant where the manufacturing takes place. And here, the systems used are the ERP system and the MES system.
The main advantage of having the MBOM in the PLM system is the direct relation between specification and manufacturing intent, allowing manufacturing engineering to work collaboratively with engineering in the same environment.
- The first benefit is fewer iterations and a shorter time to production, thanks to early interaction and manufacturing involvement in the engineering process.
- The second benefit is: product knowledge is centralized in a single system. Consolidating your Product Knowledge in ERP does not make sense due to global localization and the missing capabilities to manage the iterative engineering processes on non-existing parts.
And then came the SBOM, the xBOM
 Traditional PLM vendors and implementations kept using xBOM structures as placeholders for related specification data (mechanical designs, electrical, software deliverables, serialized products). Most of the time, related files.
Traditional PLM vendors and implementations kept using xBOM structures as placeholders for related specification data (mechanical designs, electrical, software deliverables, serialized products). Most of the time, related files.
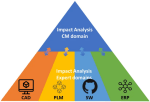 And with this approach, talking about digital thread, PLM systems also touch on the concepts of Configuration Management.
And with this approach, talking about digital thread, PLM systems also touch on the concepts of Configuration Management.
I will not go into the details here but look at the two images by clicking on them and see a similar mindset.
It is about the traceability of information in structures and systems. These structures work well in a relatively static and linear product development and delivery environment, as illustrated below:

Engineering change and release processes are based on managing the changes in different structures from the left to the right.
And then came software!
 Modern connected products are no longer mechanical products. The product’s functionality no longer depends on the mechanical properties but mainly on embedded electronics and software used. For example, look at the mechanical design of a telecom transmission tower – its behavior merely comes from non-mechanical components, and they can change over time. Still, the Bill of Material contains a lot of concrete and steel parts.
Modern connected products are no longer mechanical products. The product’s functionality no longer depends on the mechanical properties but mainly on embedded electronics and software used. For example, look at the mechanical design of a telecom transmission tower – its behavior merely comes from non-mechanical components, and they can change over time. Still, the Bill of Material contains a lot of concrete and steel parts.
The ultimate example is comparing a Tesla (software on wheels) with a traditional car. For modern connected products, electronics and software need to be part of the solution. Software and electronics allow the product to be upgraded over time. Managing these products in the same manner as mechanical products is impossible, inefficient and therefore threatening your company’s future business.
I requote Jan Bosch:
An excessive focus on the bill of materials leads to significant challenges for companies that are undergoing a digital transformation and adopting continuous value delivery. The lack of headroom, high coupling and versioning hell may easily cause an explosion of R&D expenditure over time.
The model-based, connected enterprise
I will not solve the puzzle of the future in this post. You can read my observations in my series: The road to model-based and connected PLM. We need a new infrastructure with at least two modes. One that still serves as a System of Record, storing information in a traditional manner, like a Bill of Materials for the static parts, as not everyone and everything can be connected.
 In addition, we need various Systems of Engagement that enable close to real-time interaction between products (systems) and relevant stakeholders for the engagement scope(multidisciplinary / consumers).
In addition, we need various Systems of Engagement that enable close to real-time interaction between products (systems) and relevant stakeholders for the engagement scope(multidisciplinary / consumers).
Digital twins are examples of such environments. Currently, these Systems of Engagement often work disconnected from the System of Record due to the lack of understanding of how to connect. (standard connectors? / OSLC?)
Our mission is to explore, as I wrote in my post Time to split PLM and drop our mechanical mindset.
 And while I was finalizing this post, I read a motivating post from Jan Bosch again for all of you working on understanding and pushing the digital transformation in your eco-system.
And while I was finalizing this post, I read a motivating post from Jan Bosch again for all of you working on understanding and pushing the digital transformation in your eco-system.
The title: Be the protagonist of your life: 15 rules A starting point for more to come.
Conclusion
The BOM is no longer the master of the product lifecycle when it comes to managing connected products, where functionality mainly depends on software. BOM structures with related documents are just one of the extracted baselines from a data-driven, connected enterprise. This traditional PLM infrastructure requires other, non-BOM-driven structures to represent the actual status of a virtual or physical product.
The BOM is not dead, but there is more ………
Your thoughts?

 This week there was an interesting discussion on LinkedIn initiated by Alex Bruskin from Senticore Technologies. I have known Alex for over 20 years, starting from the SmarTeam days and later through encounters in the PLM space. Alex is a real techie on the outside but also a person with a very creative mind to connect technology to business.
This week there was an interesting discussion on LinkedIn initiated by Alex Bruskin from Senticore Technologies. I have known Alex for over 20 years, starting from the SmarTeam days and later through encounters in the PLM space. Alex is a real techie on the outside but also a person with a very creative mind to connect technology to business.
You can see his LinkedIn featured posts here to get an impression.
Where is PLM @ Startups?
 This time Alex shared an observation from an event organized by the Pittsburgh Robotics Network, where he spoke with several startups.
This time Alex shared an observation from an event organized by the Pittsburgh Robotics Network, where he spoke with several startups.
His point, and I quote Alex:
Then, I spoke to a number of presenters there, explaining Senticore capabilities and listening to their situation around engineering/ manufacturing.
– many startups offered an add-on to other platforms => an autonomous module for UAV/helicopter/Vehicle. Some offered robotic components or entire robots (robot-dog).
– all startups use #solidworks , and none use #catia or #nx
– none of them have a PLM system nor an MES. I am 90% certain none of them have ERP, either. They all are apparently using #excel for all these purposes.
– only a handful of them are considering getting a PLM system in the near future.
Read the full post here and the comments below to get a broader insight into the topic.
The PLM Doctor knows it all.
The point reminded me of an episode I did together with Helena Gutierrez from Share PLM last year. She asked the same question to the PLM Doctor.
Do you think PLM is only for big corporations or can startups also benefit from it?
You can see the conversation here:
Meanwhile, the PLM Doctor is unemployed due to the lack of incoming questions.
When looking at startups, I could see two paths. One is the traditional path based on historical mechanical PLM, and a second (potential) approach which is based on understanding the future complexity of the startup offering.
There are two paths – path #1
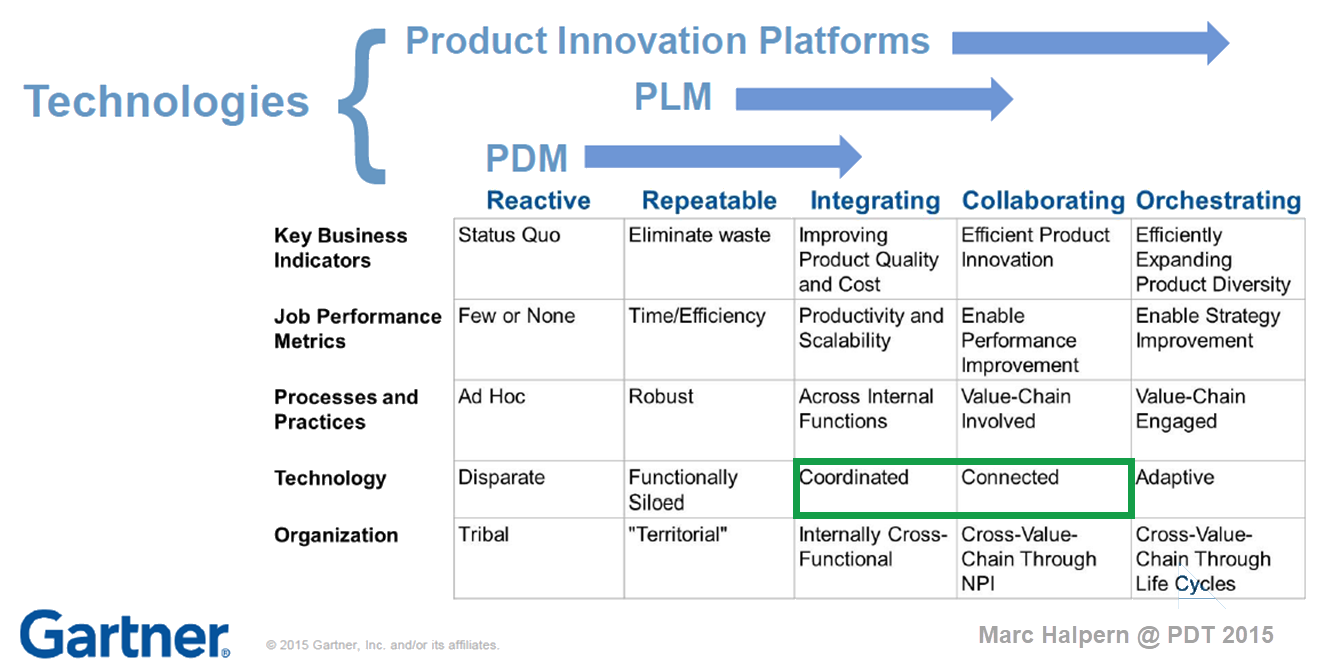
The first evolutionary path you might have seen a few times before in my blog post is the one depicted by Marc Halpern from Gartner in 2015. At that time, we started discussing Product Innovation Platforms and the new generation of PLM. You can see Marc’s slide below, which is still valid for most situations.
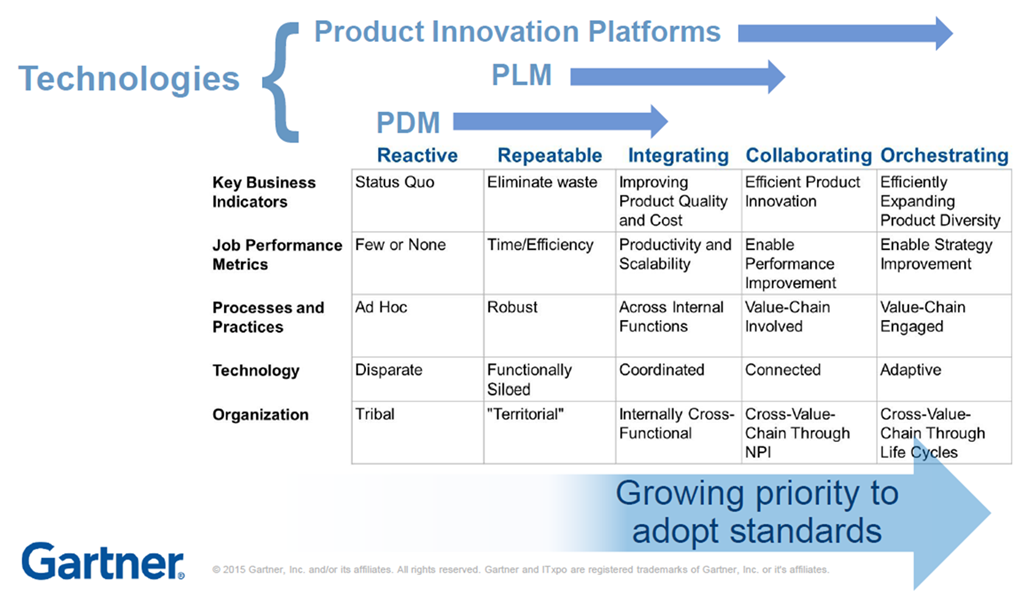
In the slide above, you see the startup company on the left side.
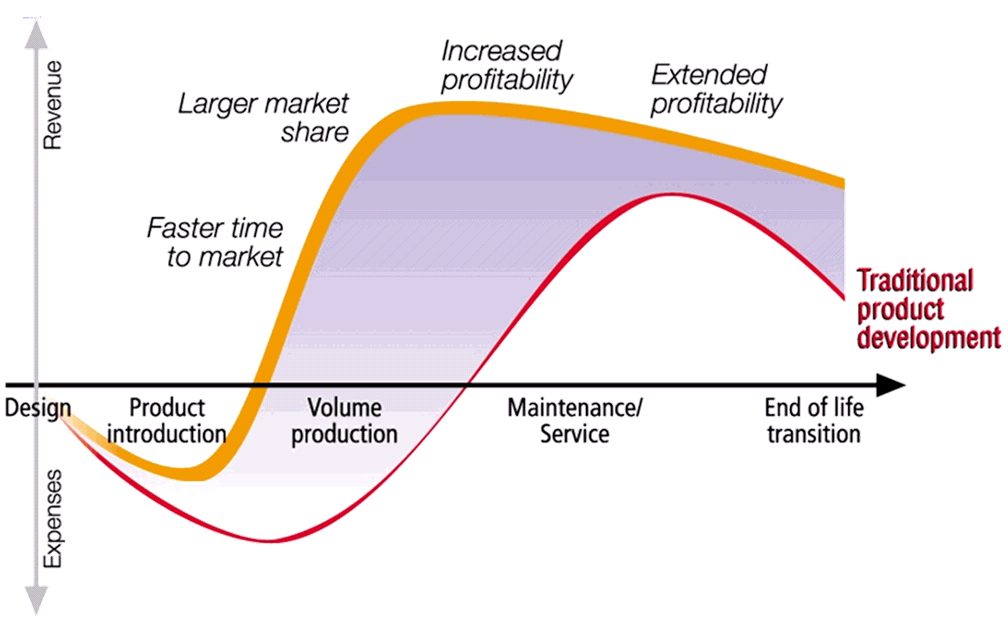 Often the main purpose of a startup company is to be visible on the market with their concept as fast as possible. Startups are often driven by a small group of multifunctional people developing a solution. In this approach, there is no place for people and reflection on processes as they are considered overhead.
Often the main purpose of a startup company is to be visible on the market with their concept as fast as possible. Startups are often driven by a small group of multifunctional people developing a solution. In this approach, there is no place for people and reflection on processes as they are considered overhead.
Only when you target your solution in a strongly regulated environment, e.g., medical devices and aerospace, you need to focus on the process too.
Therefore it is logical that most startup companies focus on the tools to develop their solution. A logical path, as what could you do without tools? Next, the choice of the tools will be, most of the time, driven by the team’s experience and available skills in the market.
 Again statistics show it is not likely that advanced tools like NX or CATIA will be chosen for the design part. More likely mid-market products like SolidWorks or Autodesk products. And for data management and reporting, the logical tools are the office tools, Excel, Word and Visio.
Again statistics show it is not likely that advanced tools like NX or CATIA will be chosen for the design part. More likely mid-market products like SolidWorks or Autodesk products. And for data management and reporting, the logical tools are the office tools, Excel, Word and Visio.
And don’t forget PowerPoint to sell the solution.
The role of investors is often also here to question investments that are not clearly understood or relevant at that time.
How a startup scales up very much depends on the choices they make for Repeatable business. This is the moment that a company starts to create its legacy. Processes and best practices need to be established and why you often see is that seasoned people join the company. These people have proven their skills in the past, and most likely, they are willing to repeat this.

And here comes the risk – experienced people come with a much better holistic overview of the product lifecycle aspects. They know what critical steps are needed to move the company to an Integrated business. These experiences are crucial; however, they should not become the new single standard.
Implementing the past is not a guarantee for success in a digital and connected future.
Implementing their past experiences would focus too much on creating a System of Record (PLM 1.0), which is crucial for configuration management, change management and compliance. However, it would also create a productivity dip for those developing the product or solution.
 This is the same dilemma that very small and medium enterprises face. They function reasonably well in a Repeatable business. How much should they invest in an Integrated or Collaborating business approach?
This is the same dilemma that very small and medium enterprises face. They function reasonably well in a Repeatable business. How much should they invest in an Integrated or Collaborating business approach?
Following the evolution path described by Marc Halpern always brings you to the point where technology changes from Coordinated to Connected. This is a challenging and immature topic, which I have discussed in my blog posts and during conferences.
See: The Challenges of a connected ecosystem for PLM or this full series of posts: The road to model-based and connected PLM.
There are two paths – path #2
Another path that startups could follow is a more forward-looking path, understanding that you need a coordinated and connected approach in the long term. For the fastest execution, you would like to work in a multidisciplinary mode in real time, exactly the characteristic of a startup.
 However, in path #2, the startup should have a longer-term vision. Instead of choosing the obvious tools, they should focus on their company’s most important value streams. They have the opportunity to select integrated domains that are based on a connected, often model-based approach. Some examples of these integrated domains:
However, in path #2, the startup should have a longer-term vision. Instead of choosing the obvious tools, they should focus on their company’s most important value streams. They have the opportunity to select integrated domains that are based on a connected, often model-based approach. Some examples of these integrated domains:
- An MBSE environment focusing on real-time interaction related to product architecture and solution components(RFLP)
- A connected product design environment, where in real-time a virtual product can be created, analyzed, and optimized – connected software might be relevant here.
- A connected product realization environment where product engineering and suppliers work together in real time.
All three examples are typical Systems of Engagement. The big difference with individual tools is that they already focus on multidisciplinary collaboration on a data-driven, model-based approach.
In addition, having these systems in place allows the startup company to invest separately in a System of Record(s) environment when scaling up. This could be a traditional PLM system combined with a Configuration Management System or an Asset Management System.

System of Record choices, of course, depends on the industry needs and the usage of the product in the field. We should not consider one system that serves all; it is an infrastructure.
In the image below, you see the concept of this approach described by Erik Herzog from SAAB Aeronautics during the recent PLM Roadmap / PDT Europe conference. You can read more details of this approach in this post: The Week after PLM Roadmap PDT Europe.
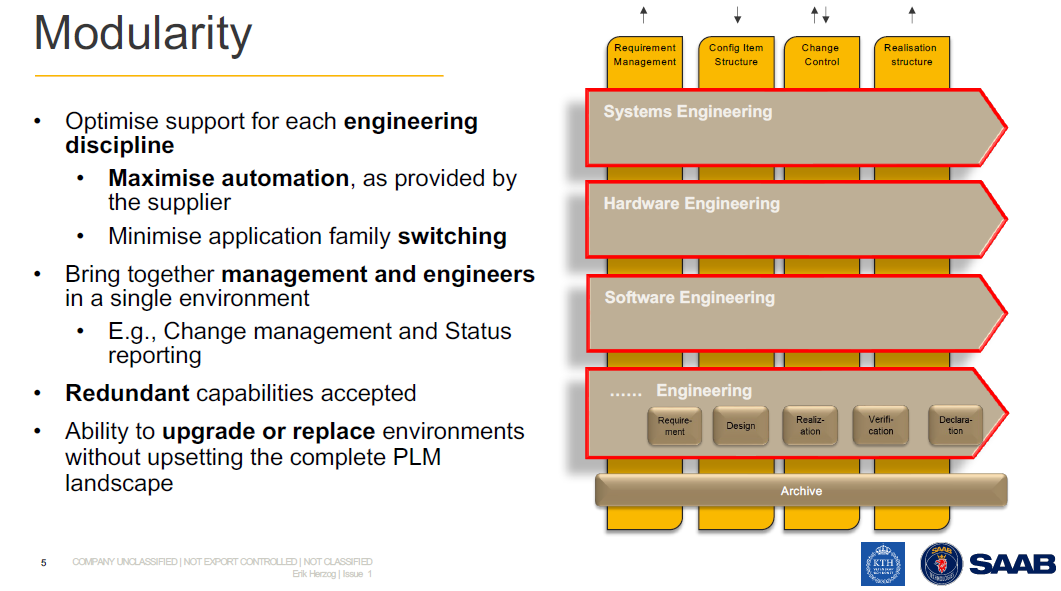
![]() Note: SAAB is not a startup; therefore, they must deal with their legacy. They are now working on business sustainable concepts for the future: Heterogeneous and federated PLM.
Note: SAAB is not a startup; therefore, they must deal with their legacy. They are now working on business sustainable concepts for the future: Heterogeneous and federated PLM.
My opinion: The heterogeneous and federated approach is the ultimate target for any enterprise. I already mentioned the importance of connected environments regarding digital twins and sustainability. Material properties, process environmental impacts and product behavior coming from the field will all work only efficiently if dealt with in a connected and federated manner.
Conclusion
The challenge for startups is that they often start without the knowledge and experience that multidisciplinary collaboration within a value stream is crucial for a connected future. This a topic that I would like to explore further with startups and peers in my ecosystem. What do you think? What are your questions? Join the conversation.

 After two quiet weeks of spending time with my family in slow motion, it is time to start the year.
After two quiet weeks of spending time with my family in slow motion, it is time to start the year.
First of all, I wish you all a happy, healthy, and positive outcome for 2022, as we need energy and positivism together. Then, of course, a good start is always cleaning up your desk and only leaving the relevant things for work on the desk.
Still, I have some books at arm’s length, either physical or on my e-reader, that I want to share with you – first, the non-obvious ones:
The Innovators Dilemma
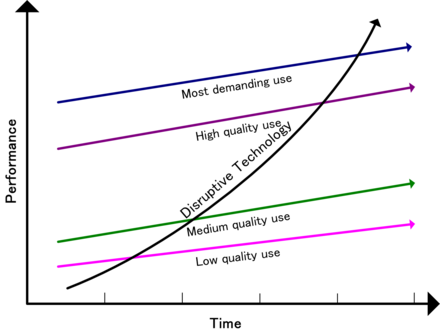
 A must-read book was written by Clayton Christensen explaining how new technologies can overthrow established big companies within a very short period. The term Disruptive Innovation comes up here. Companies need to remain aware of what is happening outside and ready to adapt to your business. There are many examples even recently where big established brands are gone or diminished in a short period.
A must-read book was written by Clayton Christensen explaining how new technologies can overthrow established big companies within a very short period. The term Disruptive Innovation comes up here. Companies need to remain aware of what is happening outside and ready to adapt to your business. There are many examples even recently where big established brands are gone or diminished in a short period.
In his book, he wrote about DEC (Digital Equipment Company) market leader in minicomputers, not having seen the threat of the PC. Or later Blockbuster (from video rental to streaming), Kodak (from analog photography to digital imaging) or as a double example NOKIA (from paper to market leader in mobile phones killed by the smartphone).
The book always inspired me to be alert for new technologies, how simple they might look like, as simplicity is the answer at the end. I wrote about in 2012: The Innovator’s Dilemma and PLM, where I believed cloud, search-based applications and Facebook-like environments could disrupt the PLM world. None of this happened as a disruption; these technologies are now, most of the time, integrated by the major vendors whose businesses are not really disrupted. Newcomers still have a hard time to concur marketspace.

In 2015 I wrote again about this book, The Innovator’s dilemma and Generation change. – image above. At that time, understanding disruption will not happen in the PLM domain. Instead, I predict there will be a more evolutionary process, which I would later call: From Coordinated to Connected.
The future ways of working address the new skills needed for the future. You need to become a digital native, as COVID-19 pushed many organizations to do so. But digital native alone does not bring success. We need new ways of working which are more difficult to implement.
Sapiens
 The book Sapiens by Yuval Harari made me realize the importance of storytelling in the domain of PLM and business transformation. In short, Yuval Harari explains why the human race became so dominant because we were able to align large groups around an abstract theme. The abstract theme can be related to religion, the power of a race or nation, the value of money, or even a brand’s image.
The book Sapiens by Yuval Harari made me realize the importance of storytelling in the domain of PLM and business transformation. In short, Yuval Harari explains why the human race became so dominant because we were able to align large groups around an abstract theme. The abstract theme can be related to religion, the power of a race or nation, the value of money, or even a brand’s image.
The myth (read: simplified and abstract story) hides complexity and inconsistencies. It allows everyone to get motivated to work towards one common goal. A Yuval says: “Fiction is far more powerful because reality is too complex”.
Too often, I have seen well-analyzed PLM projects that were “killed” by management because it was considered too complex. I wrote about this in 2019 PLM – measurable or a myth? claiming that the real benefits of PLM are hard to predict, and we should not look isolated only to PLM.

My 2020 follow-up post The PLM ROI Myth, eludes to that topic. However, even if you have a soundproof business case at the management level, still the myth might be decisive to justify the investment.
That’s why PLM vendors are always working on their myths: the most cost-effective solution, the most visionary solution, the solution most used by your peers and many other messages to influence your emotions, not your factual thinking. So just read the myths on their websites.
If you have no time to read the book, look at the above 2015 Ted to grasp the concept and use it with a PLM -twisted mind.
Re-use your CAD
 In 2015, I read this book during a summer holiday (meanwhile, there is a second edition). Although it was not a PLM book, it was helping me to understand the transition effort from a classical document-driven enterprise towards a model-based enterprise.
In 2015, I read this book during a summer holiday (meanwhile, there is a second edition). Although it was not a PLM book, it was helping me to understand the transition effort from a classical document-driven enterprise towards a model-based enterprise.
Jennifer Herron‘s book helps companies to understand how to break down the (information) wall between engineering and manufacturing.
At that time, I contacted Jennifer to see if others like her and Action Engineering could explain Model-Based Definition comprehensively, for example, in Europe- with no success.
As the Model-Based Enterprise becomes more and more the apparent future for companies that want to be competitive or benefit from the various Digital Twin concepts. For that reason, I contacted Jennifer again last year in my post: PLM and Model-Based Definition.
As you can read, the world has improved, there is a new version of the book, and there is more and more information to share about the benefits of a model-based approach.
![]() I am still referencing Action Engineering and their OSCAR learning environment for my customers. Unfortunately, many small and medium enterprises do not have the resources and skills to implement a model-based environment.
I am still referencing Action Engineering and their OSCAR learning environment for my customers. Unfortunately, many small and medium enterprises do not have the resources and skills to implement a model-based environment.
Instead, these companies stay on their customers’ lowest denominator: the 2D Drawing. For me, a model-based definition is one of the first steps to master if your company wants to provide digital continuity of design and engineering information towards manufacturing and operations. Digital twins do not run on documents; they require model-based environments.
The book is still on my desk, and all the time, I am working on finding the best PLM practices related to a Model-Based enterprise.
 It is a learning journey to deal with a data-driven, model-based environment, not only for PLM but also for CM experts, as you might have seen from my recent dialogue with CM experts: The future of Configuration Management.
It is a learning journey to deal with a data-driven, model-based environment, not only for PLM but also for CM experts, as you might have seen from my recent dialogue with CM experts: The future of Configuration Management.
Products2019
 This book was an interesting novelty published by John Stark in 2020. John is known for his academic and educational books related to PLM. However, during the early days of the COVID-pandemic, John decided to write a novel. The novel describes the learning journey of Jane from Somerset, who, as part of her MBA studies, is performing a research project for the Josef Mayer Maschinenfabrik. Her mission is to report to the newly appointed CEO what happens with the company’s products all along the lifecycle.
This book was an interesting novelty published by John Stark in 2020. John is known for his academic and educational books related to PLM. However, during the early days of the COVID-pandemic, John decided to write a novel. The novel describes the learning journey of Jane from Somerset, who, as part of her MBA studies, is performing a research project for the Josef Mayer Maschinenfabrik. Her mission is to report to the newly appointed CEO what happens with the company’s products all along the lifecycle.
Although it is not directly a PLM book, the book illustrates the complexity of PLM. It Is about people and culture; many different processes, often disconnected. Everyone has their focus on their particular discipline in the center of importance. If you believe PLM is all about the best technology only, read this book and learn how many other aspects are also relevant.

I wrote about the book in 2020: Products2019 – a must-read if you are new to PLM if you want to read more details. An important point to pick up from this book is that it is not about PLM but about doing business.
PLM is not a magical product. Instead, it is a strategy to support and improve your business.
System Lifecycle Management
 Another book, published a little later and motivated by the extra time we all got during the COVID-19 pandemic, was Martin Eigner‘s book System Lifecycle Management.
Another book, published a little later and motivated by the extra time we all got during the COVID-19 pandemic, was Martin Eigner‘s book System Lifecycle Management.
A 281-page journey from the early days of data management towards what Martin calls System Lifecycle Management (SysLM). He was one of the first to talk about System Lifecycle Management instead of PLM.
I always enjoyed Martin’s presentations at various PLM conferences where we met. In many ways, we share similar ideas. However, during his time as a professor at the University of Kaiserslautern (2003-2017), he explored new concepts with his students.
 I briefly mentioned the book in my series The road to model-based and connected PLM (Part 5) when discussing SLM or SysLM. His academic research and analysis make this book very valuable. It takes you in a very structured way through the times that mechatronics becomes important, next the time that systems (hardware and software) become important.
I briefly mentioned the book in my series The road to model-based and connected PLM (Part 5) when discussing SLM or SysLM. His academic research and analysis make this book very valuable. It takes you in a very structured way through the times that mechatronics becomes important, next the time that systems (hardware and software) become important.
We discussed in 2015 the applicability of the bimodal approach for PLM. However, as many enterprises are locked in their highly customized PDM/PLM environments, their legacy blocks the introduction of modern model-based and connected approaches.
 Where John Stark’s book might miss the PLM details, Martin’s book brings you everything in detail and with all its references.
Where John Stark’s book might miss the PLM details, Martin’s book brings you everything in detail and with all its references.
It is an interesting book if you want to catch up with what has happened in the past 20 years.
More Books …..
More books on my desk have helped me understand the past or that helped me shape the future. As this is a blog post, I will not discuss more books this time reaching my 1500 words.
Still books worthwhile to read – click on their images to learn more:
 I discussed this book two times last year. An introduction in PLM and Modularity and a discussion with the authors and some readers of the book: The Modular Way – a follow-up discussion
I discussed this book two times last year. An introduction in PLM and Modularity and a discussion with the authors and some readers of the book: The Modular Way – a follow-up discussion
x
x
 A book I read this summer contributed to a better understanding of sustainability. I mentioned this book in my presentation for the Swedish CATIA Forum in October last year – slide 29 of
A book I read this summer contributed to a better understanding of sustainability. I mentioned this book in my presentation for the Swedish CATIA Forum in October last year – slide 29 of
 System Thinking becomes crucial for a sustainable future, as I addressed in my post PLM and Sustainability.
System Thinking becomes crucial for a sustainable future, as I addressed in my post PLM and Sustainability.
Sustainability is my area of interest at the PLM Green Global Alliance, an international community of professionals working with Product Lifecycle Management (PLM) enabling technologies and collaborating for a more sustainable decarbonized circular economy.
Conclusion
There is a lot to learn. Tell us something about your PLM bookshelf – which books would you recommend. In the upcoming posts, I will further focus on PLM education. So stay tuned and keep on learning.

Image http://www.mdux.net
As promised in my early November post – The road to model-based and connected PLM (part 9 – CM), I come back with more thoughts and ideas related to the future of configuration management. Moving from document-driven ways of working to a data-driven and model-based approach fundamentally changes how you can communicate and work efficiently.
Let’s be clear: configuration management’s target is first of all about risk management. Ensuring your company’s business remains sustainable, efficient, and profitable.
 By providing the appropriate change processes and guidance, configuration management either avoids costly mistakes and iterations during all phases of a product lifecycle or guarantees the quality of the product and information to ensure safety.
By providing the appropriate change processes and guidance, configuration management either avoids costly mistakes and iterations during all phases of a product lifecycle or guarantees the quality of the product and information to ensure safety.
Companies that have not implemented CM practices probably have not observed these issues. Or they have not realized that the root cause of these issues is a lack of CM.
 Similar to what is said in smaller companies related to PLM, CM is often seen as an overhead, as employees believe they thoroughly understand their products. In addition, CM is seen as a hurdle to innovation because of the standardization of practices. So yes, they think it is normal that there are sometimes problems. That’s life.
Similar to what is said in smaller companies related to PLM, CM is often seen as an overhead, as employees believe they thoroughly understand their products. In addition, CM is seen as a hurdle to innovation because of the standardization of practices. So yes, they think it is normal that there are sometimes problems. That’s life.
I already wrote about this topic in 2010 PLM, CM and ALM – not sexy 😦 – where ALM means Asset Lifecycle Management – my focus at that time.
Hear it from the experts
To shape the discussion related to the future of Configuration Management, I had a vivid discussion with three thought leaders in this field: Lisa Fenwick, Martijn Dullaart and Maxime Gravel. A short introduction of the three of them:
 Lisa Fenwick, VP Product Development at CMstat, a leading company in Configuration Management and Data Management software solutions and consulting services for aviation, aerospace & defense, marine, and other high-tech industries. She has over 25 years of experience with CM and Deliverables Management, including both government and commercial environments.
Lisa Fenwick, VP Product Development at CMstat, a leading company in Configuration Management and Data Management software solutions and consulting services for aviation, aerospace & defense, marine, and other high-tech industries. She has over 25 years of experience with CM and Deliverables Management, including both government and commercial environments.
Ms. Fenwick has achieved CMPIC SME, CMPIC CM Assessor, and CMII-C certifications. Her experience includes implementing CM software products, CM-related consulting and training, and participation in the SAE and IEEE standards development groups
 Martijn Dullaart is the Lead Architect for Enterprise Configuration Management at ASML (Our Dutch national pride) and chairperson of the Industry 4.0 committee of the Institute Process Excellence (IPX) Congress. Martijn has his own blog mdux.net, and you might have seen him recently during the PLM Roadmap & PDT Fall conference in November – his thoughts about the CM future can be found on his blog here
Martijn Dullaart is the Lead Architect for Enterprise Configuration Management at ASML (Our Dutch national pride) and chairperson of the Industry 4.0 committee of the Institute Process Excellence (IPX) Congress. Martijn has his own blog mdux.net, and you might have seen him recently during the PLM Roadmap & PDT Fall conference in November – his thoughts about the CM future can be found on his blog here
 Maxime Gravel, Manager Model-Based Engineering at Moog Inc., a worldwide designer, manufacturer, and integrator of advanced motion control products. Max has been the director of the model-based enterprise at the Institute for Process Excellence (IPX) and Head of Configuration and Change Management at Gulfstream Aerospace which certified the first aircraft in a 3D Model-Based Environment.
Maxime Gravel, Manager Model-Based Engineering at Moog Inc., a worldwide designer, manufacturer, and integrator of advanced motion control products. Max has been the director of the model-based enterprise at the Institute for Process Excellence (IPX) and Head of Configuration and Change Management at Gulfstream Aerospace which certified the first aircraft in a 3D Model-Based Environment.
What we discussed:
We had an almost one-hour discussion related to the following points:
- The need for Enterprise Configuration Management – why and how
- The needed change from document-driven to model-based – the impact on methodology and tools
- The “neural network” of data – connecting CM to all other business domains, a similar view as from the PLM domain,
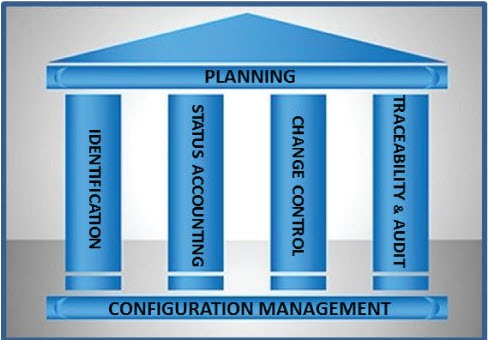 I kept from our discussion the importance of planning – as seen in the CMstat image on the left.
I kept from our discussion the importance of planning – as seen in the CMstat image on the left.
To plan which data you need to manage and how you will manage the data. How often are you doing this in your company’s projects?
Next, all participants stressed the importance of education and training on this topic – get educated. Configuration Management is not a topic that is taught at schools. Early next year, I will come back on education as the benefits of education are often underestimated. Not everything can be learned by “googling.”
Conclusion
The journey towards a model-based and data-driven future is not a quick one to be realized by new technologies. However, it is interesting to learn that the future of connected data (the “neural network”) allows organizations to implement both CM and PLM in a similar manner, using graph databases and automation. When executed at the enterprise level, the result will be that CM and PLM become natural practices instead of other siloed system-related disciplines.
Most of the methodology is there; the implementation to make it smooth and embedded in organizations will be the topics to learn. Join us in discussing and learning!
 This week I attended the PLM Roadmap & PDT Fall 2021 with great expectations based on my enthusiasm last year. Unfortunately, the excitement was less this time, and I will explain in my conclusions why. This time it was unfortunate again a virtual event which makes it hard to be interactive, something I realize I am missing a lot.
This week I attended the PLM Roadmap & PDT Fall 2021 with great expectations based on my enthusiasm last year. Unfortunately, the excitement was less this time, and I will explain in my conclusions why. This time it was unfortunate again a virtual event which makes it hard to be interactive, something I realize I am missing a lot.
 Over two hundred attendees connected for the two days, and you can find the agenda here. Typically I would discuss the relevant sessions; now, I want to group some of them related to a theme, as there was complementary information in these sessions.
Over two hundred attendees connected for the two days, and you can find the agenda here. Typically I would discuss the relevant sessions; now, I want to group some of them related to a theme, as there was complementary information in these sessions.
Disruption
 Again like in the spring, the theme was focusing on DISRUPTION. The word disruption can give you an uncomfortable feeling when you are not in power. It is more fun to disrupt than to be disrupted, as I mentioned in my spring presentation. Read The week after PLM Roadmap & PDT Spring 2021
Again like in the spring, the theme was focusing on DISRUPTION. The word disruption can give you an uncomfortable feeling when you are not in power. It is more fun to disrupt than to be disrupted, as I mentioned in my spring presentation. Read The week after PLM Roadmap & PDT Spring 2021
In his keynote speech Peter Bilello (CIMdata) kicked off with: The Critical Dozen: 12 familiar, evolving trends and enablers of digital transformation that you cannot or should not live without.
You can see them on the slide below:

 I believe many of them should be familiar to you as these themes have been “in the air” already for quite some time. Vendors first and slowly companies start to investigate them when relevant. You will find many of them back in my recent series: The road to model-based and connected PLM, where I explored the topics that would cross your path on that journey.
I believe many of them should be familiar to you as these themes have been “in the air” already for quite some time. Vendors first and slowly companies start to investigate them when relevant. You will find many of them back in my recent series: The road to model-based and connected PLM, where I explored the topics that would cross your path on that journey.
Like Peter said: “For most of the topics you cannot pick and choose as they are all connected.”
Another interesting observation was that we are more and more moving away from the concept of related structures (digital thread) but more to connected datasets (digital web). Marc Halpern first introduced this topic last year at the 2020 conference and has become an excellent image to frame what we should imagine in a connected world.

Digital web also has to do with the uprise of the graph database mentioned by Peter Bilello as a potentially disruptive technology during the fireside chat. Relational databases can be seen as rigid, associated with PLM structures. On the other hand, graph databases can be associated with flexible relations between different types of data – the image of the digital web.
Where Peter was mainly telling WHAT was happening, two presentations caught my attention because of the HOW.
 First of all, Dr. Rodney Ewing (Cummins) ‘s session: A Balanced Strategy to Reap Continuous Business Value from Digital PLM was a great story of a transformational project. It contained both having a continuous delivery of business value in mind while moving to the connected enterprise.
First of all, Dr. Rodney Ewing (Cummins) ‘s session: A Balanced Strategy to Reap Continuous Business Value from Digital PLM was a great story of a transformational project. It contained both having a continuous delivery of business value in mind while moving to the connected enterprise.
As Rodney mentioned, the contribution of TCS was crucial here, which I can imagine. It is hard for a company to understand what is happening in the outside (PLM) world when applying it to your company. Their transformation roadmap is an excellent example of having the long-term vision in mind, meanwhile delivering value during the transformation.

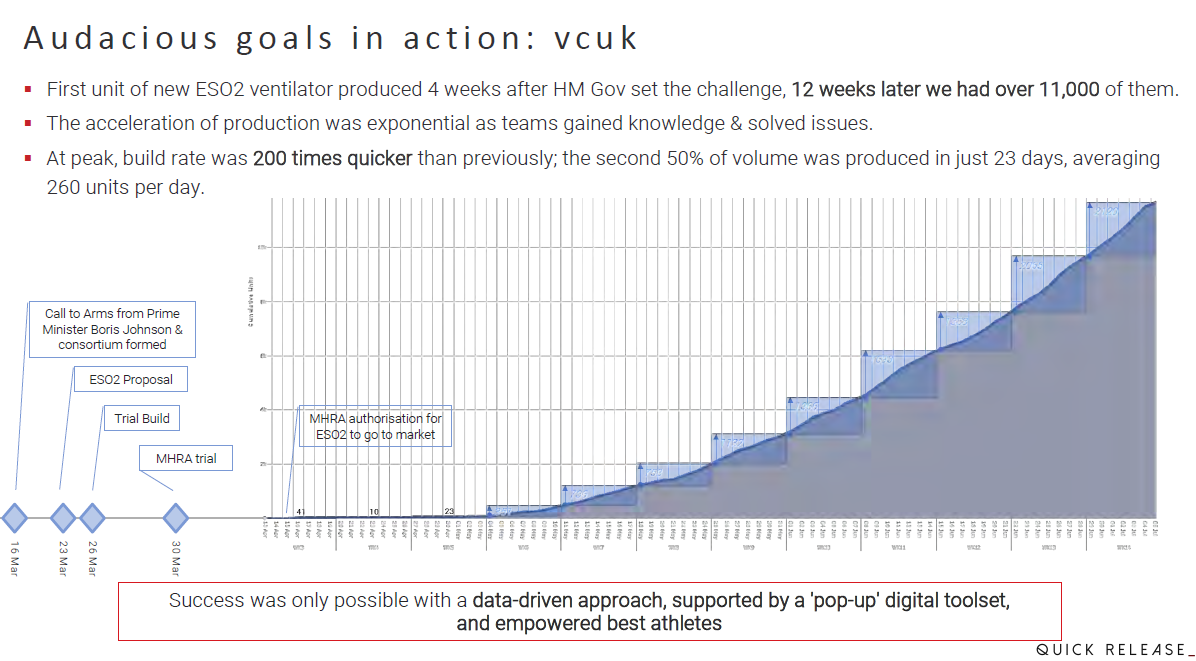
Talking about the right partner and synergy, the second presentation I liked in this context of disruption was Ian Quest’s presentation (Quick Release): Open-source Disruption in Support of Audacious Goals. As a sponsor of the conference, they had ten minutes to pitch their area of expertise.
 After Ian’s presentation, focused on audacious goals (for non-English natives translated as “brave” goals), there was only one word that stuck to my mind: pragmatic.
After Ian’s presentation, focused on audacious goals (for non-English natives translated as “brave” goals), there was only one word that stuck to my mind: pragmatic.
Instead of discussions about the complexity, Ian gave examples of where a pragmatic data-centric approach could lead to great benefits, as you can see from one of the illustrated benefits below:
Standards
A characteristic topic of this conference is that we always talk about standards. Torbjörn Holm (Eurostep) gave an excellent overview of where standards have led to significant benefits. For example, the containerization of goods has dramatically improved transportation of goods (we all benefit) while killing proprietary means of transport (trains, type of ships, type of unloading). See the image below:

Torbjörn rightfully expanded this story to the current situation in the construction industry or the challenges for asset operators. Unfortunately, in these practices, many content suppliers remain focusing on their unique capabilities, reluctantly neglecting the demand for interoperability among the whole value chain.
 It is a topic Marc Halpern also mentioned last year as an outcome of their Gartner PLM benefits survey. Gartner’s findings:
It is a topic Marc Halpern also mentioned last year as an outcome of their Gartner PLM benefits survey. Gartner’s findings:
Time to Market is not so much improved by using PLM as the inefficient interaction with suppliers is the impediment.
 Like transport before containerization, the exchange of information is not standardized and designed for digital exchange. Torbjorn believes that more and more companies will insist on exchange standards – like CHIFOS – an ISO1596-derived exchange standard in the process industry. It is a user-driven standard, the best standard.
Like transport before containerization, the exchange of information is not standardized and designed for digital exchange. Torbjorn believes that more and more companies will insist on exchange standards – like CHIFOS – an ISO1596-derived exchange standard in the process industry. It is a user-driven standard, the best standard.
 In this context, the presentation from Kenny Swope (Boeing) and Jean Yves Delaunay (Airbus) The Business Value of Standards-based Information Interoperability for Aerospace & Defense illustrated this fact.
In this context, the presentation from Kenny Swope (Boeing) and Jean Yves Delaunay (Airbus) The Business Value of Standards-based Information Interoperability for Aerospace & Defense illustrated this fact.
While working for competitors, the Aerospace industry understands the criticality of standards to become more efficient and less vendor-dependent. In the aerospace & defense group, they discuss these themes. The last year’s 2020 Fall sessions showed the results. You can read their publications here
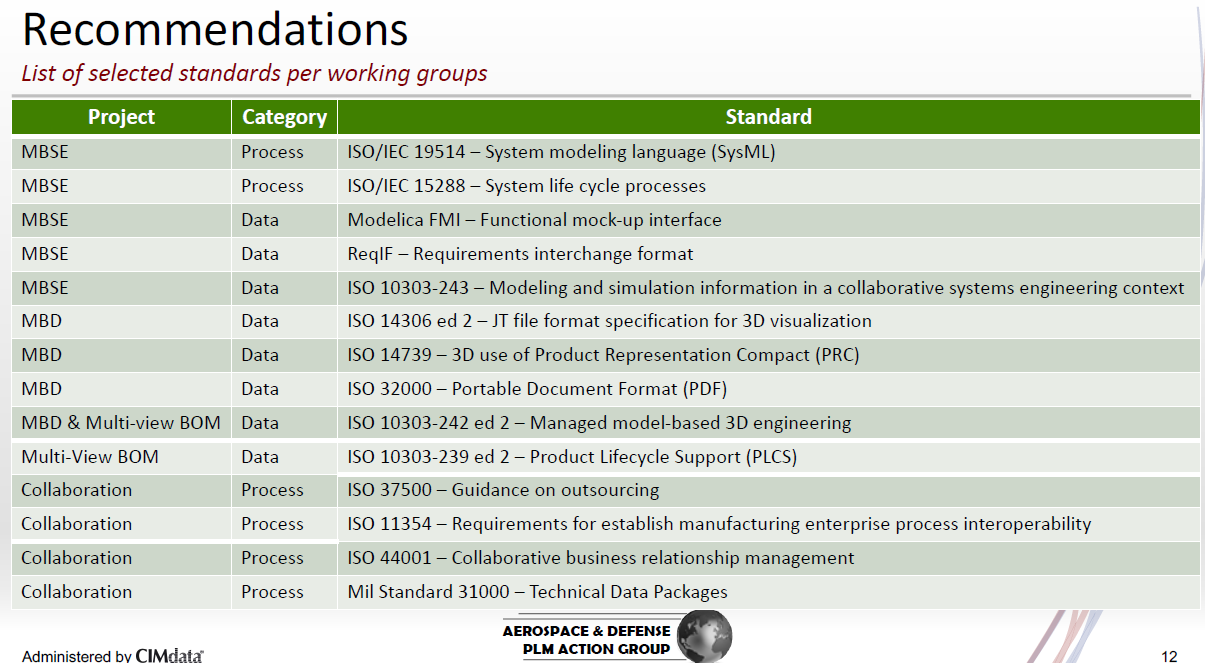
The A&D PLM action group uses the following framework when evaluating standards – as you can see on the image below:

The result – and this is a combined exercise of many participating experts from the field; this is their recommendation:
To conclude:
People often complain about standards, framed by proprietary data format vendors, that they lead to a rigid environment, blocking agility.
In reality, standards allow companies to be more agile as the (proprietary) data flow is less an issue. Remember the containerization example.
Sustainability and System Thinking
 This conference has always been known for its attention to the circular economy and green thinking. In the past, these topics might have been considered disconnected from our PLM practices; now, they have become a part of everyone’s mission.
This conference has always been known for its attention to the circular economy and green thinking. In the past, these topics might have been considered disconnected from our PLM practices; now, they have become a part of everyone’s mission.
Two presentations stood out on this topic for me. First, Ken Webster, with his keynote speech: In the future, you will own nothing and you will be happy was a significant oversight of how we as consumers currently are disconnected from the circular economy. His plea, as shown below, for making manufacturers responsible for the legal ownership of the materials in the products they deliver would impact consumer behavior.
Product as a Service (PaaS) and new ways to provide a service is becoming essential. For example, buildings as power stations, as they are a place to collect solar or wind energy?
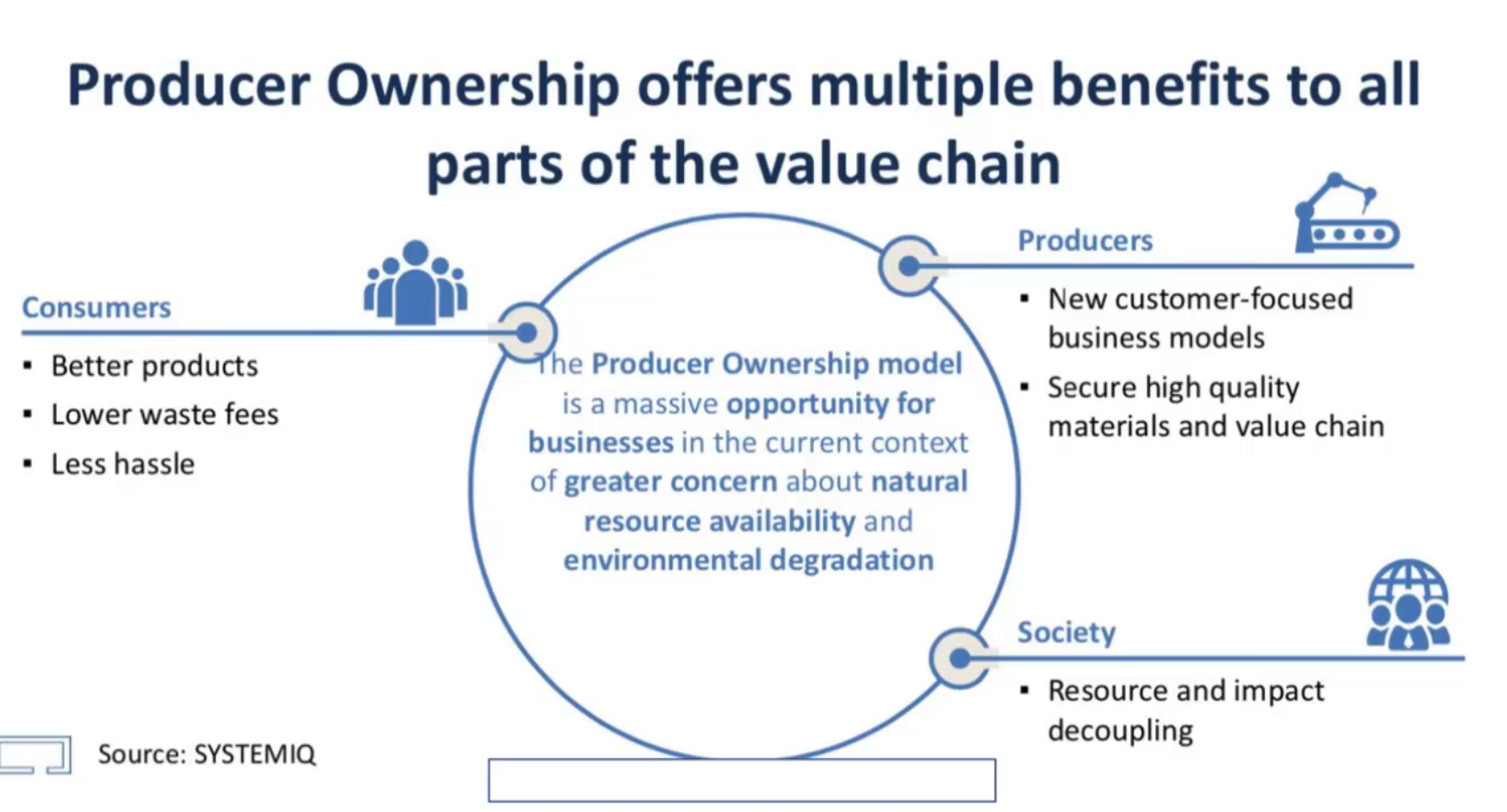
 His thoughts are aligned with what is happening in Europe related to the European Green Deal (not in his presentation). There is a push for a PaaS model for all products as this would be an excellent stimulant for the circular economy. PaaS combined with a Digital Product Passport – more on that next year.
His thoughts are aligned with what is happening in Europe related to the European Green Deal (not in his presentation). There is a push for a PaaS model for all products as this would be an excellent stimulant for the circular economy. PaaS combined with a Digital Product Passport – more on that next year.
Making upgrades to your products has less impact on the environment than creating new products to sell (and creating waste of the old product). Ken Webster was an interesting statement about changing the economy – do we want to own products or do we want to benefit from the product and leave the legal ownership to the manufacturer.
A topic I discussed in the PLM Roadmap & PDT Conference Spring 2021 – look here at slide 11
Patrick Hillberg‘s presentation Rising to the challenge of engineering and optimizing . . . what? was the one closest to my heart. We discussed Sustainability and Systems Thinking with Patrick in our PLM Global Green Alliance, being pretty aligned on this topic. Patrick started by explaining the difference between Systems Engineering and Systems Thinking. Looking at the product go-to-market of an organization is more than the traditional V-model. Economic pressure and culture will push people to deviate from the ideal technological plan due to other priorities.
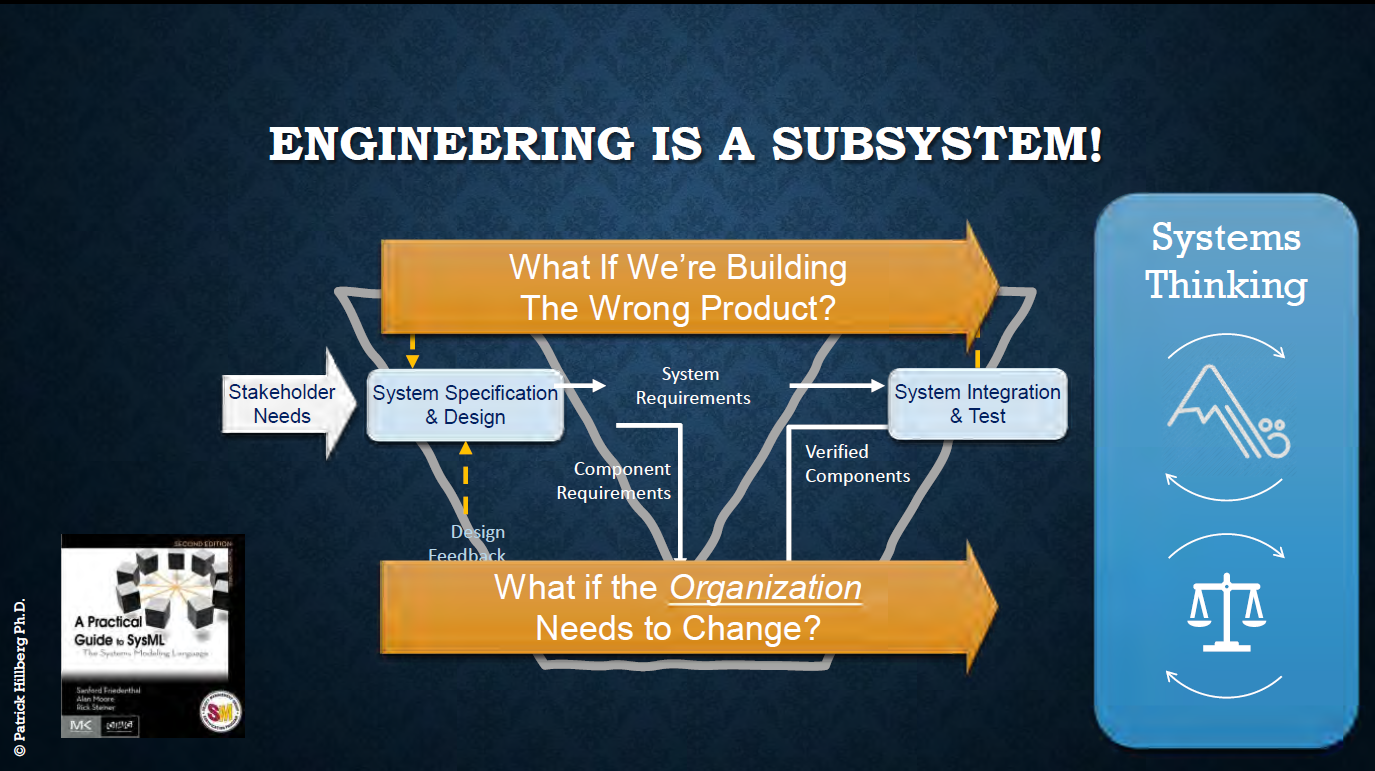
Expanding on this observation, Partick stated that there are limits to growth, a topic discussed by many people involved in the sustainable economy. Economic growth is impossible on a limited planet, and we have to take more dimensions into account. Patrick gave some examples of that, including issues related to the infamous Boeing 737 Max example.
For Patrick, the COVID-pandemic is the end of the old 2nd Industrial Revolution and a push for a new Fourth Industrial Revolution, which is not only technical, as the slide below indicates.

With Patrick, I believe we are at a decisive moment to disrupt ourselves, reconsider many things we do and are used to doing. Even for PLM practitioners, this is a new path to go.
Data
There were two presentations related to digitization and the shift from document-based to a data-driven approach.
 First, there was Greg Weaver (Gulfstream) with his presentation Indexing Content – Finding Your Needle in the Haystack. Greg explained that by using indexation of existing document-based information combined with a specific dashboard, they could provide fast access to information that otherwise would have been hidden in so many document or even paper archives.
First, there was Greg Weaver (Gulfstream) with his presentation Indexing Content – Finding Your Needle in the Haystack. Greg explained that by using indexation of existing document-based information combined with a specific dashboard, they could provide fast access to information that otherwise would have been hidden in so many document or even paper archives.
It was a pragmatic solution, making me feel nostalgic seeing the SmarTeam profile cards. It was an excellent example of moving to a digital enterprise, and Gulfstream has always been a front runner on this topic.
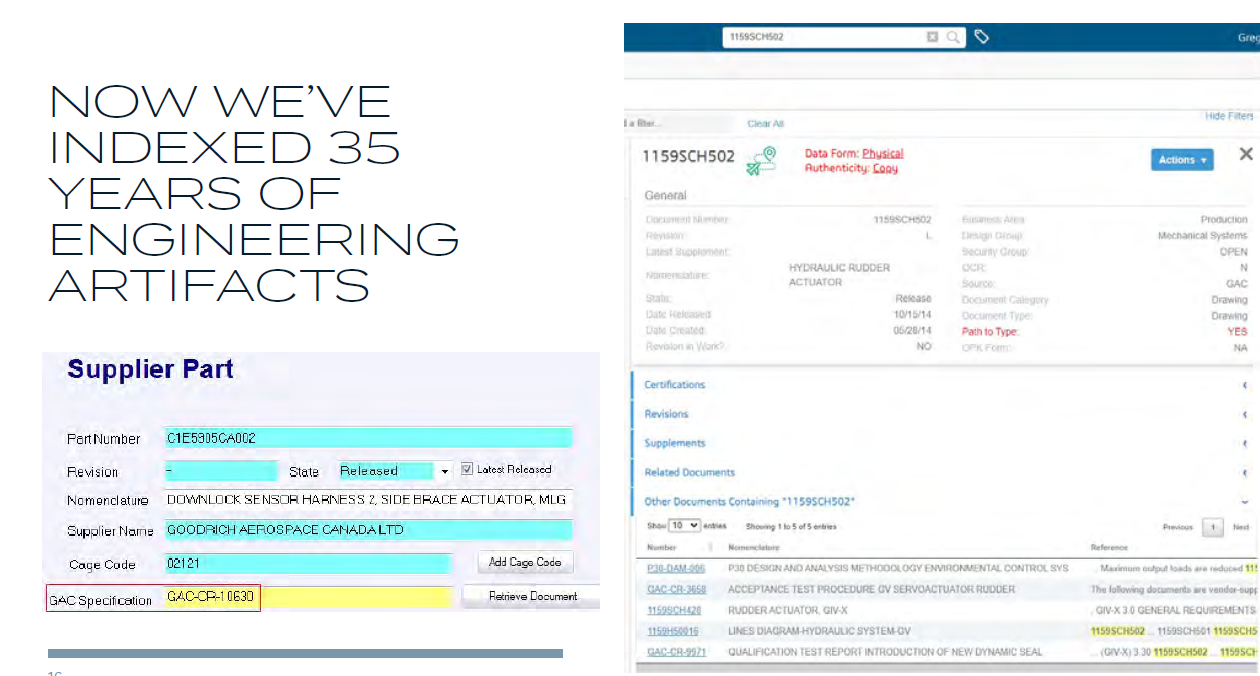
 Warning: Don’t use this by default at home (your company). The data in a regulated industry like Aerospace is expected to be of high quality due to the configuration management processes in place. If your company does not have a strong CM practice, the retrieved data might be inaccurate.
Warning: Don’t use this by default at home (your company). The data in a regulated industry like Aerospace is expected to be of high quality due to the configuration management processes in place. If your company does not have a strong CM practice, the retrieved data might be inaccurate.
Martijn Dullaart (ASML)’s presentation The Next disruption, please….. was the next step into the future. With his statement “No CM = No Trust,” he made an essential point for data-driven environments.
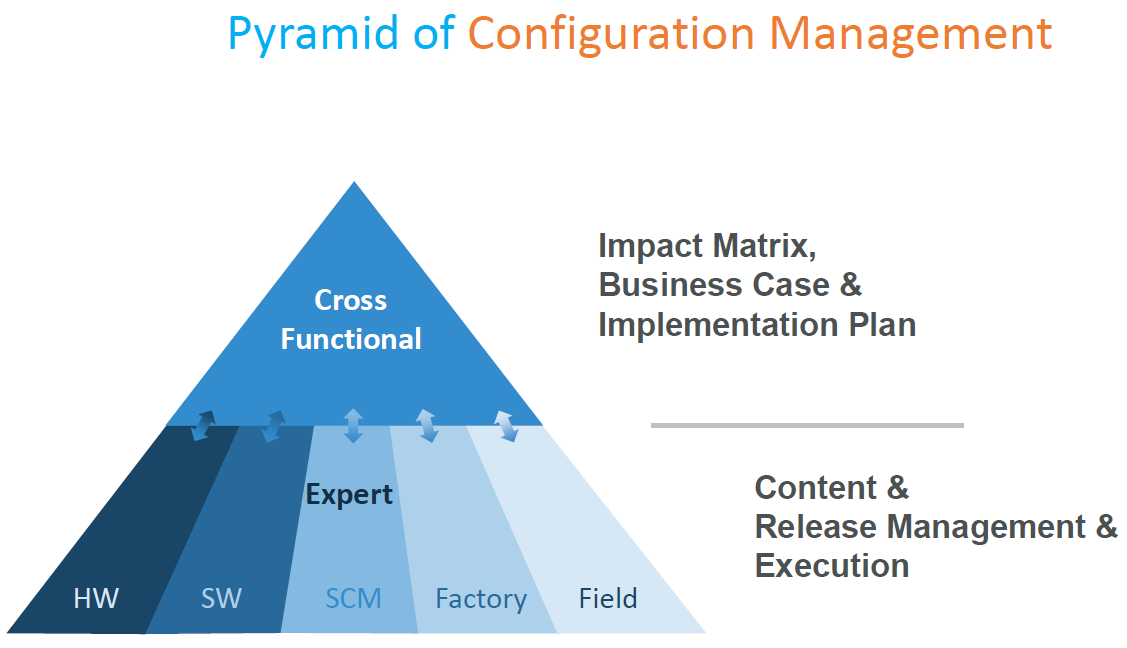 There is a need for Configuration Management, and I touched on this topic in my last post: The road to model-based and connected PLM (part 9 – CM).
There is a need for Configuration Management, and I touched on this topic in my last post: The road to model-based and connected PLM (part 9 – CM).
Martijn’s presentation can also be found on his blog here, and I encourage you to read it (saving me copy & paste text). It was interesting to see that Martijn improved his CM pyramid, as you can see, more discipline and activity-oriented instead of a system view. With Martijn and others, I will elaborate on this topic soon.
Conclusion
This has been an extremely long post, and thanks for reading until the end. Many interesting topics were presented at the conference. I was less excited this time because many of these topics are triggers for a discussion. Innovation comes from meeting people with different backgrounds. In a live conference, you would meet during the break or during the famous dinner. How can we ensure we follow up on all this interesting information.
Your thoughts? Contact me for a Corona Friday discussion.
 When I started this series in July, I expected to talk mostly about new ways of working, enabled through a data-driven and model-based approach. However, when analyzing what is needed for such a future (part 3), it became apparent that many of these new ways of working are dependent on technology.
When I started this series in July, I expected to talk mostly about new ways of working, enabled through a data-driven and model-based approach. However, when analyzing what is needed for such a future (part 3), it became apparent that many of these new ways of working are dependent on technology.
From coordinated to connected sounds like a business change;
however, it all depends on technology. And here I have to thank Marc Halpern (Gartner’s Research VP, Engineering and Design Technologies) again, who came with this brilliant scheme below:
So now it is time to address the last point from my starting post:
Configuration Management requires a new approach. The current methodology is very much based on hardware products with labor-intensive change management. However, the world of software products has different configuration management and change procedures. Therefore, we need to merge them into a single framework. Unfortunately, this cannot be the BOM framework due to the dynamics in software changes.
Configuration management at this moment
PLM and CM are often considered overlapping. My March 2019 post: PLM and Configuration Management – a happy marriage? shares some thoughts related to this point
 Does having PLM or PDM installed mean you have implemented CM? There is this confusion because revision management is considered the same as configuration management. Read my March 2020 post: What the FFF is happening? Based on a vivid discussion launched by Yoann Maingon, CEO and founder of Ganister, an example of a modern, graph database-based, flexible PLM solution.
Does having PLM or PDM installed mean you have implemented CM? There is this confusion because revision management is considered the same as configuration management. Read my March 2020 post: What the FFF is happening? Based on a vivid discussion launched by Yoann Maingon, CEO and founder of Ganister, an example of a modern, graph database-based, flexible PLM solution.
To hear it from a CM-side, I discussed it with Martijn Dullaart in my February 2021 post: PLM and Configuration Management. We also zoomed in on CM2 in this post as a methodology.
post: PLM and Configuration Management. We also zoomed in on CM2 in this post as a methodology.
Martijn is the Lead Architect for Enterprise Configuration Management at ASML (Our Dutch national pride) and chairperson of the Industry 4.0 committee of the Integrated Process Excellence (IPX) Congress.
As mentioned before in a previous post (part 6), he will be speaking at the PLM Roadmap & PDT Fall conference starting this upcoming week.

In this post, I want to talk about the CM future. For understanding the current situation, you can find a broad explanation here on Wikipedia. Have a look at CM in the context of the product lifecycle, ensuring that the product As-Specified and As-Designed information matches the As-Built and As-Operated product information.
A mismatch or inconsistency between these artifacts can lead to costly errors, particularly in later lifecycle stages. CM originated from the Aerospace and Defense industry for that reason.  However, companies in other industries might have implemented CM practices too. Either due to regulations or thanks to the understanding that configuration mistakes can cause significant damage to the company.
However, companies in other industries might have implemented CM practices too. Either due to regulations or thanks to the understanding that configuration mistakes can cause significant damage to the company.
Historically configuration management addresses the needs of “slow-moving” products. For example, the design of an airplane could take years before manufacturing started. Tracking changes and ensuring consistency of all referenced datasets was often a manual process.
On purpose, I wrote “referenced datasets,” as the information was not connected in a single environment most of the time. The identifier of a dataset ( an item or a document) was the primary information carrier used for mentally connecting other artifacts to keep consistency.
 The Institute of Process Excellence (IPX) has been one of the significant contributors to configuration management methodology. They have been providing (and still offer) CM2 training and certification.
The Institute of Process Excellence (IPX) has been one of the significant contributors to configuration management methodology. They have been providing (and still offer) CM2 training and certification.
As mentioned before, PLM vendors or implementers suggest that a PLM system could fully support Configuration Management. However, CM is more than change management, release management and revision management.

As the diagram from Martijn Dullaart shows, PLM is one facet of configuration management.
 Of course, there are also (a few) separate CM tools focusing on the configuration management process. CMstat’s EPOCH CM tool is an example of such software. In addition, on their website, you can find excellent articles explaining the history and their future thoughts related to CM.
Of course, there are also (a few) separate CM tools focusing on the configuration management process. CMstat’s EPOCH CM tool is an example of such software. In addition, on their website, you can find excellent articles explaining the history and their future thoughts related to CM.
The future will undoubtedly be a connected, model-based, software-driven environment. Naturally, therefore, configuration management processes will have to change. (Impressive buzz word sentence, still I hope you get the message).
From coordinated to connected has a severe impact on CM. Let’s have a look at the issues.
Configuration Management – the future
![]() The transition to a data-driven and model-based infrastructure has raised the following questions:
The transition to a data-driven and model-based infrastructure has raised the following questions:
- How to deal with the granularity of data – each dataset needs to be validated. For example, a document (a collection of datasets) needs to be validated in the document-based approach. How to do this efficiently?
- The behavior of a product (or system) will more and more dependent on software. Product CM practices have been designed for the hardware domain; now, we need a mix of hardware and software CM practices.
- Due to the increased complexity of products (or systems) and the rapid changes due to software versions, how do we guarantee the As-Operated product is still matching the As-Designed / As-Certified definitions.
![]() I don’t have answers to these questions. I only share observations and trends I see in my actual world.
I don’t have answers to these questions. I only share observations and trends I see in my actual world.
Granularity of data
The concept of datasets has been discussed in my post (part 6). Now it is about how to manage the right sets of connected data.
 The image on the left, borrowed from Erik Herzog’s presentation at the PDM Roadmap & PDT Fall conference in 2020, is a good illustration of the challenge.
The image on the left, borrowed from Erik Herzog’s presentation at the PDM Roadmap & PDT Fall conference in 2020, is a good illustration of the challenge.
At that time, Erik suggested that OSLC could be the enabler of a digital CM backbone for an enterprise. Therefore, it was a pleasure to see Erik providing an update at the yearly OSLC Fest conference this week.

You can find the agenda and Erik’s presentation here on day 2.
OSLC as a framework seems to be a good candidate for supporting modern CM scenarios. It allows a company to build full traceability between all relevant artifacts (if digital available). I can see the beauty of the technical infrastructure.
Still, it is about people and processes first. Therefore, I am curious to learn from my readers who believe and experiment with such a federated infrastructure.
More software
 Traditional working companies might believe that software should be treated as part of the Bill of Materials. In this theory, you treat software code as a part, with a part number and revision. In this way, you might believe configuration management practices do not have to change. However, there are some fundamental differences in why we should decouple hardware and software.
Traditional working companies might believe that software should be treated as part of the Bill of Materials. In this theory, you treat software code as a part, with a part number and revision. In this way, you might believe configuration management practices do not have to change. However, there are some fundamental differences in why we should decouple hardware and software.
First, for the same hardware solution, there might be a whole collection of valid software codes. Just like your computer. How many valid software codes, even from the same application, can you run on this hardware? Managing a computer system and its software through a Bill of Materials is unimaginable.
A computer, of course, is designed for running all kinds of software versions. However, modern products in the field, like cars, machines, electrical devices, all will have a similar type of software-driven flexibility.
 For that reason, I believe that companies that deliver software-driven products should design a mechanism to check if the combination of hardware and software is valid. For a computer system, a software mismatch might not be costly or painful; for an industrial system, it might be crucial to ensure invalid combinations can exist. Click on the image to learn more.
For that reason, I believe that companies that deliver software-driven products should design a mechanism to check if the combination of hardware and software is valid. For a computer system, a software mismatch might not be costly or painful; for an industrial system, it might be crucial to ensure invalid combinations can exist. Click on the image to learn more.
 Solutions like Configit or pure::variants might lead to a solution. In Feb 2021, I discussed in PLM and Configuration Lifecycle Management with Henrik Hulgaard, the CTO from Configit, the unique features of their solution.
Solutions like Configit or pure::variants might lead to a solution. In Feb 2021, I discussed in PLM and Configuration Lifecycle Management with Henrik Hulgaard, the CTO from Configit, the unique features of their solution.
I hope to have a similar post shortly with Pure Systems to understand their added value to configuration management.
Software change management is entirely different from hardware change management. The challenge is to have two different change management approaches under one consistent umbrella without creating needless overhead.
Increased complexity – the digital twin?
With the increased complexity of products and many potential variants of a solution, how can you validate a configuration? Perhaps we should investigate the digital twin concept, with a twin for each instance we want to validate.
 Having a complete virtual representation of a product, including the possibility to validate the software behavior on the virtual product, would allow you to run (automated) validation tests to certify and later understand a product in the field.
Having a complete virtual representation of a product, including the possibility to validate the software behavior on the virtual product, would allow you to run (automated) validation tests to certify and later understand a product in the field.
No need for inspection on-site or test and fix upgrades in the physical world. Needed for space systems for sure, but why not for every system in the long term. When we are able to define and maintain a virtual twin of our physical product (on-demand), we can validate.
 I learned about this concept at the 2020 Digital Twin conference in the Netherlands. Bart Theelen from Canon Production Printing explained that they could feed their simulation models with actual customer data to simulate and analyze the physical situation. In some cases, it is even impossible to observe the physical behavior. By tuning the virtual environment, you might understand what happens in the physical world.
I learned about this concept at the 2020 Digital Twin conference in the Netherlands. Bart Theelen from Canon Production Printing explained that they could feed their simulation models with actual customer data to simulate and analyze the physical situation. In some cases, it is even impossible to observe the physical behavior. By tuning the virtual environment, you might understand what happens in the physical world.
An eye-opener and an advocate for the model-based approach. Therefore, I am looking forward to the upcoming PLM Roadmap & PDT Fall conference. Hopefully, Martijn Dullaart will share his thoughts on combining CM and working in a model-based environment. See you there?
Conclusion
Finally, we have reached in this series the methodology part, particularly the one related to configuration management and traceability in a very granular, digital environment.
After the PLM Roadmap & PDT fall conference, I plan to follow up with three thought leaders on this topic: Martijn Dullaart (ASML), Maxime Gravel (Moog) and Lisa Fenwick (CMstat). What would you ask them?
 In my last post in this series, The road to model-based and connected PLM, I mentioned that perhaps it is time to talk about SLM instead of PLM when discussing popular TLA’s for our domain of expertise. There were not so many encouraging statements for SLM so far.
In my last post in this series, The road to model-based and connected PLM, I mentioned that perhaps it is time to talk about SLM instead of PLM when discussing popular TLA’s for our domain of expertise. There were not so many encouraging statements for SLM so far.
SLM could mean for me, Solution Lifecycle Management, considering that the company’s offering more and more is a mix of products and services. Or SLM could mean System Lifecycle Management, in that case pushing the idea that more and more products are interacting with the outside world and therefore could be considered systems. Products are (almost) dead.
In addition, I mentioned that the typical product lifecycle and related configuration management concepts need to change as in the SLM domain. There is hardware and software with different lifecycles and change processes.
It is a topic I want to explore further. I am curious to learn more from Martijn Dullaart, who will be lecturing at the PLM Road map and PDT 2021 fall conference in November. I hope my expectations are not too high, knowing it is a topic of interest for Martijn. Feel free to join this discussion
In this post, it is time to follow up on my third statement related to what data-driven implies:
Data-driven means that we need to manage data in a much more granular manner. We have to look different at data ownership. It becomes more about data accountability per role as the data can be used and consumed throughout the product lifecycle
On this topic, I have a list of points to consider; let’s go through them.
The dataset
In this post, I will often use the term dataset (you are also allowed to write the data set I understood).
 A dataset means a predefined number of attributes and values that belong logically to each other. Datasets should be defined based on the purpose and, if possible, designated for a single goal. In this way, they can be stored in a database.
A dataset means a predefined number of attributes and values that belong logically to each other. Datasets should be defined based on the purpose and, if possible, designated for a single goal. In this way, they can be stored in a database.
Combined with other datasets, a combination can result in relevant business information. Note a dataset is not only transactional data; a dataset could also describe geometry.
Identify the dataset
 In the document-based world, a lot of information could be stored in a single file. In a data-driven world, we should define a dataset that contains a specific piece of information, logically belonging together. If we are more precise, a part would have various related datasets that make up the definition of a part. These definitions could be:
In the document-based world, a lot of information could be stored in a single file. In a data-driven world, we should define a dataset that contains a specific piece of information, logically belonging together. If we are more precise, a part would have various related datasets that make up the definition of a part. These definitions could be:
- Core identification attributes like ID, Name, Type and Status
- The Type could define a set of linked information. For example, a valve would have different characteristics as a resistor. Through classification, we can link data sets to the core definition of a part.
- The part can have engineering-specific data (CAD and metadata), manufacturing-specific data, supplier-specific data, and service-specific data. Each of these datasets needs to be defined as a unique element in a data-driven environment
- CAD is a particular case as most current CAD systems don’t treat geometry as a single dataset. In a file-based world, many other datasets are stored in the file (e.g., engineering or manufacturing details). In a data-driven environment, we want to have the CAD definition to be treated like a dataset. Dassault Systèmes with their CATIA V6 and 3DEXPERIENCE platform or PTC with OnShape are examples of this approach.Having CAD as separate datasets makes sharing and collaboration so much easier, as we can see from these solutions. The concept for CAD stored in a database is not new, and this approach has been used in various disciplines. Mechanical CAD was always a challenge.
![]() Thanks to Moore’s Law (approximate every 2 years, processor power doubled – click on the image for the details) and higher network connection speed, it starts to make sense to have mechanical CAD also stored in a database instead of a file
Thanks to Moore’s Law (approximate every 2 years, processor power doubled – click on the image for the details) and higher network connection speed, it starts to make sense to have mechanical CAD also stored in a database instead of a file
An important point to consider is a kind of standardization of datasets. In theory, there should be a kind of minimum agreed collection of datasets. Industry standards provide these collections in their dictionary. Whenever you optimize your data model for a connected enterprise, make sure you look first into the standards that apply to your industry.
 They might not be perfect or complete, but inventing your own new standard is a guarantee for legacy issues in the future. This remark is also valid for the software vendors in this domain. A proprietary data model might give you a competitive advantage.
They might not be perfect or complete, but inventing your own new standard is a guarantee for legacy issues in the future. This remark is also valid for the software vendors in this domain. A proprietary data model might give you a competitive advantage.
Still, in the long term, there is always the need to connect with outside stakeholders.
Identify the RACI
To ensure a dataset is complete and well maintained, the concept of RACI could be used. RACI is the abbreviation for Responsible Accountable Consulted and Informed and a simplification of the RASCI Model, see also a responsibility assignment matrix.
In a data-driven environment, there is no data ownership anymore like you have for documents. The main reason that data ownership can no longer be used is that datasets can be consumed by anyone in the ecosystem. No longer only your department or the manufacturing or service department.
Data sets in a data-driven environment bring value when connected with other datasets in applications or dashboards.
A dataset describing the specification attributes of a part could be used in a spare part app and a service app. Of course, the dataset will be used in a different context – still, we need to ensure we can trust the data.
Therefore, per identified dataset, there should be governed by a kind of RACI concept. The RACI concept is a way to break the siloes in an organization.
Identify Inside / outside
There is a lot of fear that a connected, data-driven environment will expose Intellectual Property (IP). It came up in recent discussions. If you like storytelling and technology, read my old SmarTeam colleague Alex Bruskin’s post: The Bilbo Baggins Threat to PLM Assets. Alex has written some “poetry” with a deep technical message behind it.
 It is true that if your data set is too big, you have the challenge of exposing IP when connecting this dataset with others. Therefore, when building a data model, you should make it possible to have datasets pure for internal usage and datasets for sharing.
It is true that if your data set is too big, you have the challenge of exposing IP when connecting this dataset with others. Therefore, when building a data model, you should make it possible to have datasets pure for internal usage and datasets for sharing.
When you use the concept of RACI, the difference should be defined by the I(informed) – is it PLM-data or PIM-data for example?
Tracking relations
Suppose we follow up on the concept of datasets. In that case, it becomes clear that relations between the datasets are as crucial as the dataset. In traditional PLM applications, these relations are often predefined as part of the core data model/
 For example, the EBOM parts have relationships between themselves and specification data – see image.
For example, the EBOM parts have relationships between themselves and specification data – see image.
The MBOM parts have links with the supplier data or the manufacturing process.
The prepared relations in a PLM system allow people to implement the system relatively quickly to map their approaches to this taxonomy.
 However, traditional PLM systems are based on a document-based (or file-based) taxonomy combined with related metadata. In a model-based and connected environment, we have to get rid of the document-based type of data.
However, traditional PLM systems are based on a document-based (or file-based) taxonomy combined with related metadata. In a model-based and connected environment, we have to get rid of the document-based type of data.
Therefore, the datasets will be more granular, and there is a need to manage exponential more relations between datasets.
 This is why you see the graph database coming up as a needed infrastructure for modern connected applications. If you haven’t heard of a graph database yet, you are probably far from technology hypes. To understand the principles of a graph database you can read this article from neo4j: Graph Databases for Beginners: Why graph technology is the future
This is why you see the graph database coming up as a needed infrastructure for modern connected applications. If you haven’t heard of a graph database yet, you are probably far from technology hypes. To understand the principles of a graph database you can read this article from neo4j: Graph Databases for Beginners: Why graph technology is the future
As you can see from the 2020 Gartner Hype Cycle for Artificial Intelligence this technology is at the top of the hype and conceptually the way to manage a connected enterprise. The discussion in this post also demonstrates that besides technology there is a lot of additional conceptual thinking needed before it can be implemented.
Although software vendors might handle the relations and datasets within their platform, the ultimate challenge will be sharing datasets with other platforms to get a connected ecosystem.
For example, the digital web picture shown above and introduced by Marc Halpern at the 2018 PDT conference shows this concept. Recently CIMdata discussed this topic in a similar manner: The Digital Thread is Really a Web, with the Engineering Bill of Materials at Its Center
(Note I am not sure if CIMdata has published a recording of this webinar – if so I will update the link)
Anyway, these are signs that we started to find the right visuals to imagine new concepts. The traditional digital thread pictures, like the one below, are, for me, impressions of the past as they are too rigid and focusing on some particular value streams.
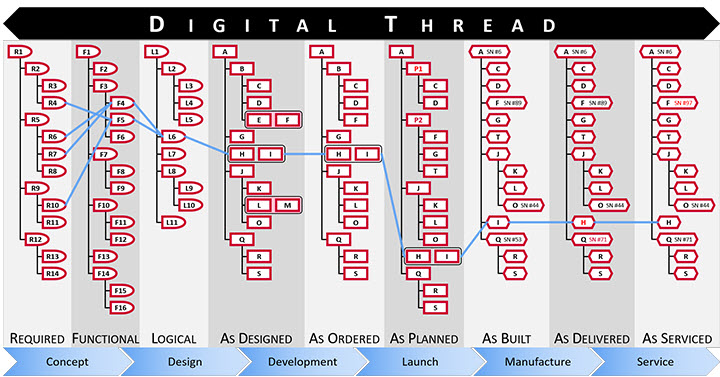
From a distance, it looks like a connected enterprise should work like our brain. We story information on different abstraction levels. We keep incredibly many relations between information elements. As the brain is a biological organ, connections degrade or get lost. Or the opposite other relationships become so strong that we cannot change them anymore. (“I know I am always right”)
 Interestingly, the brain does not use the “single source of truth”-concept – there can be various “truths” inside a brain. This makes us human beings with all the good and the harmful effects of that.
Interestingly, the brain does not use the “single source of truth”-concept – there can be various “truths” inside a brain. This makes us human beings with all the good and the harmful effects of that.
As long as we realize there is no single source of truth.
In business and our technological world, we need sometimes the undisputed truth. Blockchain could be the basis for securing the right connections between datasets to guarantee the result is valid. I am curious if blockchain can scale to complex connected situations, although Moore’s Law might ultimately help us here too(if still valid).
 The topic is not new – in 2014 I wrote a post with the title: PLM is doomed unless …. Where I introduced the topic of owning and sharing in the context of the human brain. In the post, I refer to the book On Intelligence by Jeff Hawkins how tries to analyze what is human-based intelligence and how could we apply it to our technology concepts. Still a fascinating book worth reading if you have the time and opportunity.
The topic is not new – in 2014 I wrote a post with the title: PLM is doomed unless …. Where I introduced the topic of owning and sharing in the context of the human brain. In the post, I refer to the book On Intelligence by Jeff Hawkins how tries to analyze what is human-based intelligence and how could we apply it to our technology concepts. Still a fascinating book worth reading if you have the time and opportunity.
Conclusion
A data-driven approach requires a more granular definition of information, leading to the concepts of datasets and managing relations between datasets. This is a fundamental difference compared to the past, where we were operating systems with information. Now we are heading towards connected platforms that provide a filtered set of real-time data to act upon.
I am curious to learn more about how people have solved the connected challenges and in what kind of granularity. Let us know!
 My previous post introducing the concept of connected platforms created some positive feedback and some interesting questions. For example, the question from Maxime Gravel:
My previous post introducing the concept of connected platforms created some positive feedback and some interesting questions. For example, the question from Maxime Gravel:
Thank you, Jos, for the great blog. Where do you see Change Management tool fit in this new Platform ecosystem?
is one of the questions I try to understand too. You can see my short comment in the comments here. However, while discussing with other experts in the CM-domain, we should paint the path forward. Because if we cannot solve this type of question, the value of connected platforms will be disputable.
 It is essential to realize that a digital transformation in the PLM domain is challenging. No company or vendor has the perfect blueprint available to provide an end-to-end answer for a connected enterprise. In addition, I assume it will take 10 – 20 years till we will be familiar with the concepts.
It is essential to realize that a digital transformation in the PLM domain is challenging. No company or vendor has the perfect blueprint available to provide an end-to-end answer for a connected enterprise. In addition, I assume it will take 10 – 20 years till we will be familiar with the concepts.
It takes a generation to move from drawings to 3D CAD. It will take another generation to move from a document-driven, linear process to data-driven, real-time collaboration in an iterative manner. Perhaps we can move faster, as the Automotive, Aerospace & Defense, and Industrial Equipment industries are not the most innovative industries at this time. Other industries or startups might lead us faster into the future.
![]() Although I prefer discussing methodology, I believe before moving into that area, I need to clarify some more technical points before moving forward. My apologies for writing it in such a simple manner. This information should be accessible for the majority of readers.
Although I prefer discussing methodology, I believe before moving into that area, I need to clarify some more technical points before moving forward. My apologies for writing it in such a simple manner. This information should be accessible for the majority of readers.
What means data-driven?
 I often mention a data-driven environment, but what do I mean precisely by that. For me, a data-driven environment means that all information is stored in a dataset that contains a single aspect of information in a standardized manner, so it becomes accessible by outside tools.
I often mention a data-driven environment, but what do I mean precisely by that. For me, a data-driven environment means that all information is stored in a dataset that contains a single aspect of information in a standardized manner, so it becomes accessible by outside tools.
A document is not a dataset, as often it includes a collection of datasets. Most of the time, the information it is exposed to is not standardized in such a manner a tool can read and interpret the exact content. We will see that a dataset needs an identifier, a classification, and a status.
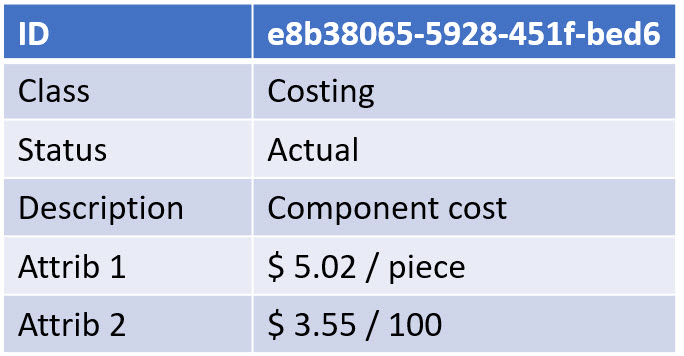 An identifier to be able to create a connection between other datasets – traceability or, in modern words, a digital thread.
An identifier to be able to create a connection between other datasets – traceability or, in modern words, a digital thread.
A classification as the classification identifier will determine the type of information the dataset contains and potential a set of mandatory attributes
A status to understand if the dataset is stable or still in work.
Examples of a data-driven approach – the item
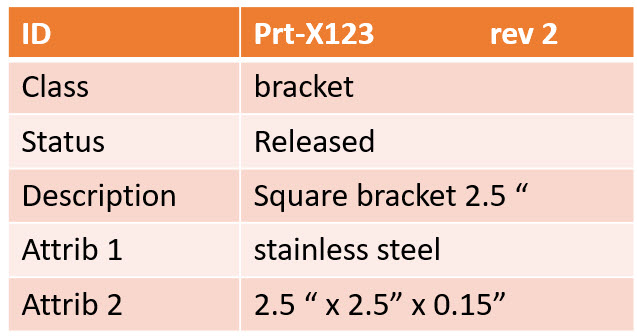 The most common dataset in the PLM world is probably the item (or part) in a Bill of Material. The identifier is the item number (ID + revision if revisions are used). Next, the classification will tell you the type of part it is.
The most common dataset in the PLM world is probably the item (or part) in a Bill of Material. The identifier is the item number (ID + revision if revisions are used). Next, the classification will tell you the type of part it is.
Part classification can be a topic on its own, and every industry has its taxonomy.
Finally, the status is used to identify if the dataset is shareable in the context of other information (released, in work, obsolete), allowing tools to expose only relevant information.
 In a data-driven manner, a part can occur in several Bill of Materials – an example of a single definition consumed in other places.
In a data-driven manner, a part can occur in several Bill of Materials – an example of a single definition consumed in other places.
When the part information changes, the accountable person has to analyze the relations to the part, which is easy in a data-driven environment. It is normal to find this functionality in a PDM or ERP system.
 When the part would change in a document-driven environment, the effort is much higher.
When the part would change in a document-driven environment, the effort is much higher.
First, all documents need to be identified where this part occurs. Then the impact of change needs to be managed in document versions, which will lead to other related changes if you want to keep the information correct.
Examples of a data-driven approach – the requirement
 Another example illustrating the benefits of a data-driven approach is implementing requirements management, where requirements become individual datasets. Often a product specification can contain hundreds of requirements, addressing the needs of different stakeholders.
Another example illustrating the benefits of a data-driven approach is implementing requirements management, where requirements become individual datasets. Often a product specification can contain hundreds of requirements, addressing the needs of different stakeholders.
In addition, several combinations of requirements need to be handled by other disciplines, mechanical, electrical, software, quality and legal, for example.
 As requirements need to be analyzed and ranked, a specification document would never be frozen. Trade-off analysis might lead to dropping or changing a single requirement. It is almost impossible to manage this all in a document, although many companies use Excel. The disadvantages of Excel are known, in particular in a dynamic environment.
As requirements need to be analyzed and ranked, a specification document would never be frozen. Trade-off analysis might lead to dropping or changing a single requirement. It is almost impossible to manage this all in a document, although many companies use Excel. The disadvantages of Excel are known, in particular in a dynamic environment.
The advantage of managing requirements as datasets is that they can be grouped. So, for example, they can be pushed to a supplier (as a specification).
Or requirements could be linked to test criteria and test cases, without the need to manage documents and make sure you work with them last updated document.
![]() As you will see, also requirements need to have an Identifier (to manage digital relations), a classification (to allow grouping) and a status (in work / released /dropped)
As you will see, also requirements need to have an Identifier (to manage digital relations), a classification (to allow grouping) and a status (in work / released /dropped)
Data-driven and Models – the 3D CAD model

3D PDF Model
When I launched my series related to the model-based approach in 2018, the first comments I got came from people who believed that model-based equals the usage of 3D CAD models – see Model-based – the confusion. 3D Models are indeed an essential part of a model-based infrastructure, as the 3D model provides an unambiguous definition of the physical product. Just look at how most vendors depict the aspects of a virtual product using 3D (wireframe) models.
Although we use a 3D representation at each product lifecycle stage, most companies do not have a digital continuity for the 3D representation. Design models are often too heavy for visualization and field services support. The connection between engineering and manufacturing is usually based on drawings instead of annotated models.
I wrote about modern PLM and Model-Based Definition, supported by Jennifer Herron from Action Engineering – read the post PLM and Model-Based Definition here.

If your company wants to master a data-driven approach, this is one of the most accessible learning areas. You will discover that connecting engineering and manufacturing requires new technology, new ways of working and much more coordination between stakeholders.
Implementing Model-Based Definition is not an easy process. However, it is probably one of the best steps to get your digital transformation moving. The benefits of connected information between engineering and manufacturing have been discussed in the blog post PLM and Model-Based Definition
 Essential to realize all these exciting capabilities linked to Industry 4.0 require a data-driven, model-based connection between engineering and manufacturing.
Essential to realize all these exciting capabilities linked to Industry 4.0 require a data-driven, model-based connection between engineering and manufacturing.
If this is not the case, the projected game-changers will not occur as they become too costly.
Data-driven and mathematical models
To manage complexity, we have learned that we have to describe the behavior in models to make logical decisions. This can be done in an abstract model, purely based on mathematical equations and relations. For example, suppose you look at climate models, weather models or COVID infections models.
In that case, we see they all lead to discussions from so-called experts that believe a model should be 100 % correct and any exception shows the model is wrong.
It is not that the model is wrong; the expectations are false.
For less complex systems and products, we also use models in the engineering domain. For example, logical models and behavior models are all descriptive models that allow people to analyze the behavior of a product.
 For example, how software code impacts the product’s behavior. Usually, we speak about systems when software is involved, as the software will interact with the outside world.
For example, how software code impacts the product’s behavior. Usually, we speak about systems when software is involved, as the software will interact with the outside world.
There can be many models related to a product, and if you want to get an impression, look at this page from the SEBoK wiki: Types of Models. The current challenge is to keep the relations between these models by sharing parameters.
 The sharable parameters then again should be datasets in a data-driven environment. Using standardized diagrams, like SysML or UML, enables the used objects in the diagram to become datasets.
The sharable parameters then again should be datasets in a data-driven environment. Using standardized diagrams, like SysML or UML, enables the used objects in the diagram to become datasets.
I will not dive further into the modeling details as I want to remain at a high level.
Essential to realize digital models should connect to a data-driven infrastructure by sharing relevant datasets.
What does data-driven imply?
I want to conclude this time with some statements to elaborate on further in upcoming posts and discussions
- Data-driven does not imply there needs to be a single environment, a single database that contains all information. Like I mentioned in my previous post, it will be about managing connected datasets in a federated manner. It is not anymore about owned the data; it is about access to reliable data.
- Data-driven does not mean we do not need any documents anymore. Read electronic files for documents. Likely, document sets will still be the interface to non-connected entities, suppliers, and regulatory bodies. These document sets can be considered a configuration baseline.
- Data-driven means that we need to manage data in a much more granular manner. We have to look different at data ownership. It becomes more data accountability per role as the data can be used and consumed throughout the product lifecycle.
- Data-driven means that you need to have an enterprise architecture, data governance and a master data management (MDM) approach. So far, the traditional PLM vendors have not been active in the MDM domain as they believe their proprietary data model is leading. Read also this interesting McKinsey article: How enterprise architects need to evolve to survive in a digital world
- A model-based approach with connected datasets seems to be the way forward. Managing data in documents will become inefficient as they cannot contribute to any digital accelerator, like applying algorithms. Artificial Intelligence relies on direct access to qualified data.
- I don’t believe in Low-Code platforms that provide ad-hoc solutions on demand. The ultimate result after several years might be again a new type of spaghetti. On the other hand, standardized interfaces and protocols will probably deliver higher, long-term benefits. Remember: Low code: A promising trend or a Pandora’s Box?
- Configuration Management requires a new approach. The current methodology is very much based on hardware products with labor-intensive change management. However, the world of software products has different configuration management and change procedure. Therefore, we need to merge them in a single framework. Unfortunately, this cannot be the BOM framework due to the dynamics in software changes. An interesting starting point for discussion can be found here: Configuration management of industrial products in PDM/PLM
Conclusion
Again, a long post, slowly moving into the future with many questions and points to discuss. Each of the seven points above could be a topic for another blog post, a further discussion and debate.
After my summer holiday break in August, I will follow up. I hope you will join me in this journey by commenting and contributing with your experiences and knowledge.

I believe we are almost at the end of learning from the past. We have seen how, from an initial serial CAD-driven approach with PDM, we evolved to PLM-managed structures, the EBOM and the MBOM. Or to illustrate this statement, look at the image below, where I use a Tech-Clarity image from Jim Brown.
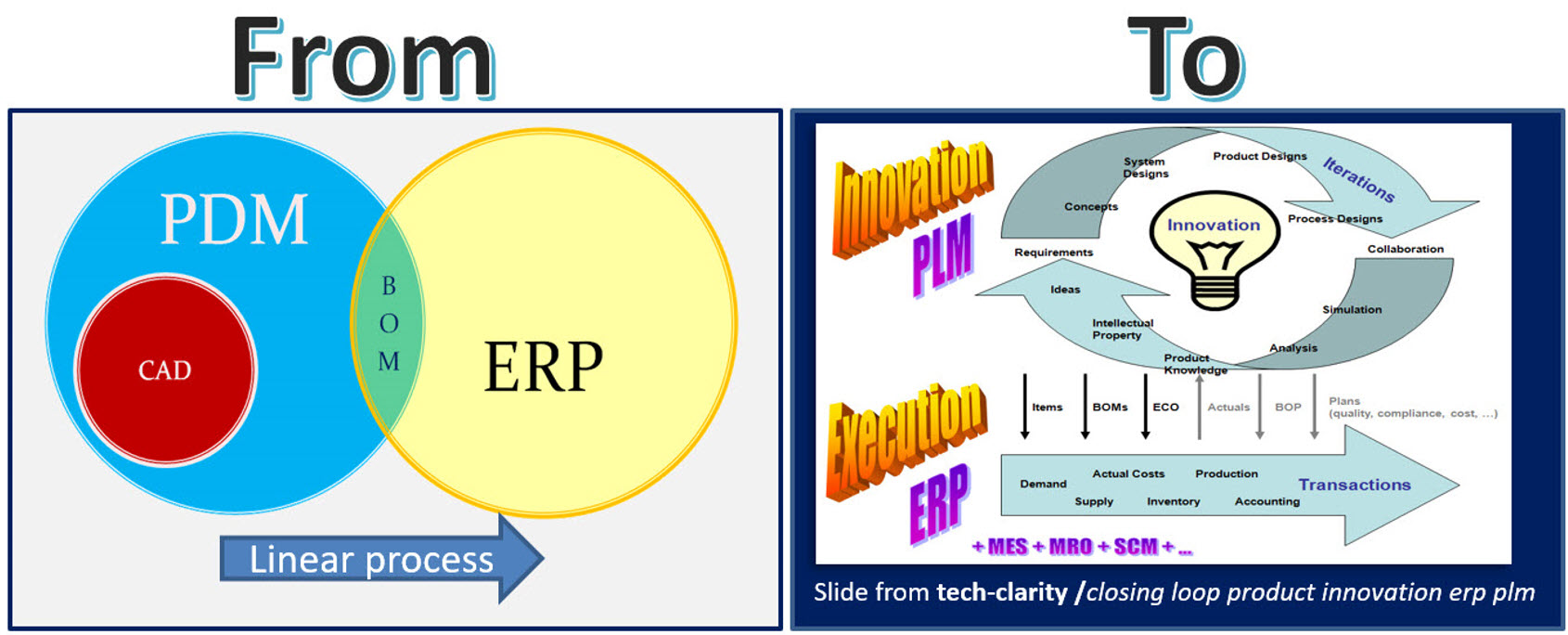
The image on the right describes perfectly the complementary roles of PLM and ERP. The image on the left shows the typical PDM-approach. PDM feeding ERP in a linear process. The image on the right, I believe it is from 2004, shows the best practice before digital transformation. PLM is supporting product innovation in an iterative approach, pushing released information to ERP for execution.
 As I think in images, I like the concept of a circle for PLM and an arrow for ERP. I am always using those two images in discussions with my customers when we want to understand if a particular activity should be in the PLM or ERP-domain.
As I think in images, I like the concept of a circle for PLM and an arrow for ERP. I am always using those two images in discussions with my customers when we want to understand if a particular activity should be in the PLM or ERP-domain.
Ten years ago, the PLM-domain was conceptually further extended by introducing support for products in operations and service. Similar to the EBOM (engineering) and the MBOM (manufacturing), the SBOM (service) was introduced to support product information for products in operation. In theory a full connected cicle.
Asset Lifecycle Management
At the same time, I was promoting PLM-practices for owners/operators to enhance Asset Lifecycle Management. My first post from June 2010 was called: PLM for Asset Lifecycle Management and Asset Development introduces this approach.
 Conceptually the SBOM and Asset Lifecycle Management have a lot in common. There is a design product, in this case, an asset (plant, machine) running in the field, and we need to make sure operators have the latest information about the asset. And in case of asset changes, which can be a maintenance operation, a repair or complete overall, we need to be sure the changes are based on the correct information from the as-built environment. This requires full configuration management.
Conceptually the SBOM and Asset Lifecycle Management have a lot in common. There is a design product, in this case, an asset (plant, machine) running in the field, and we need to make sure operators have the latest information about the asset. And in case of asset changes, which can be a maintenance operation, a repair or complete overall, we need to be sure the changes are based on the correct information from the as-built environment. This requires full configuration management.
Asset changes can be based on extensive projects that need to be treated like new product development projects, with a staged approach that can take weeks, months, sometimes years. These activities are typical activities performed in PLM-systems, not in MRO-systems that are designed to manage the actual operation. Again here we see the complementary roles of PLM (iterative) and MRO (execution).
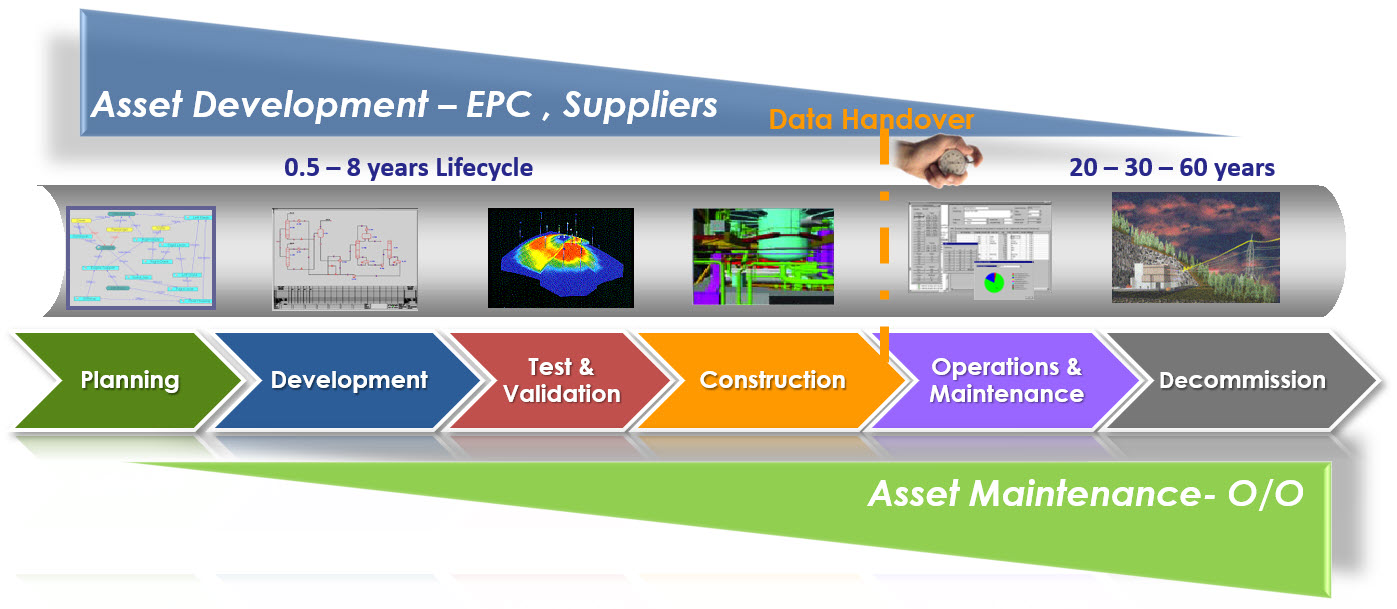
Since 2008, I have worked a lot in this environment, mainly in the nuclear and process industry. If you want to learn more about this aspect of PLM, I recommend looking at the PLMpartner website, where Bjørn Fidjeland, in cooperation with SharePLM, published a course on Plant Information Management. We worked together in several projects and Bjørn has done a great effort to describe the logical model to be used instead of a function-feature story.
Ten years ago, we were not calling this concept the “Digital Twin,” as the aim was to provide end-to-end support of asset information from engineering, procurement, and construction towards operation in a coordinated manner. The breaking point in the relation between the EPCs and Owner/Operators is the data-handover – how much of your IP can/do you expose and what is needed. Nowadays, we would call striving for end-to-end data continuity the Digital Thread.
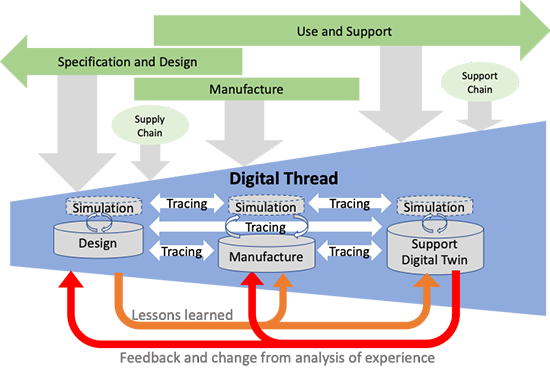
Hot from the press in this context, CIMdata just published a commentary Managing the Digital Thread in Global Value Chains describing Eurostep’s ShareAspace capabilities and experiences in managing an end-to-end information flow (Digital Thread) in a heterogeneous environment based on exchange standards like ISO 10303-239 PLCS. Their solution is based on what I consider a more modern approach for managing digital continuity compared to the traditional approach I described before. Compare the two images in this paragraph. The first image represents the old/current way with a disconnected handover, the second represents ShareAspace connected approach based on a real digital thread.
The Service BOM
As discussed with Asset Lifecycle Management, there is a disconnect between the engineering disciplines and operations in the field, looking from the point of view of an Asset owner/operator.
Now when we look from the perspective of a manufacturing company that produces assets to be serviced, we can identify a different dataflow and a new structure, the Service BOM (SBOM).
 The SBOM provides information on how a product needs to be serviced. What are the parts that require service, and what are the service kits that are possible for that product? For that reason, service engineering should be done in parallel to product engineering. When designing a product, the engineer needs to identify which the wearing parts (always require service in time) and which parts might be serviceable.
The SBOM provides information on how a product needs to be serviced. What are the parts that require service, and what are the service kits that are possible for that product? For that reason, service engineering should be done in parallel to product engineering. When designing a product, the engineer needs to identify which the wearing parts (always require service in time) and which parts might be serviceable.
There are different ways to look at the SBOM. Conceptually, the SBOM could be created in close relation with the EBOM. At the moment you define your product, you also should specify how the product will be serviced. See the image below

From this example, it is clear that part standardization and modularization have a considerable benefit for services downstream. What if you have only one serviceable part that applies to many products? The number of parts to have in stock will be strongly reduced instead of having many similar parts that only fit in a single product?
 Depending on the type of product, the SBOM can be generic, serving many products in the field. In that case, the company has to deal with catalogs, to be defined in PLM. Or the SBOM can be aligned with the As-Built of a capital product in the field. In that case, the concepts of Asset Lifecycle Management apply. Click on the image to see a clear picture.
Depending on the type of product, the SBOM can be generic, serving many products in the field. In that case, the company has to deal with catalogs, to be defined in PLM. Or the SBOM can be aligned with the As-Built of a capital product in the field. In that case, the concepts of Asset Lifecycle Management apply. Click on the image to see a clear picture.
![]() The SBOM on its own, in such an environment, will have links to specific documents, service instructions, operating manuals.
The SBOM on its own, in such an environment, will have links to specific documents, service instructions, operating manuals.
If your PLM-system allows it, extending the EBOM and MBOM with an SBOM is not a complex effort. What is crucial to understand is that the SBOM has its own lifecycle, which can even last longer than the active product sold. So sometimes, manufacturing specifications, related to service parts need to be maintained too, creating a link between the SBOM and potential MBOM(s).
ECM = Enterprise Change Management
When I discussed ECM in my previous post in the context of Engineering Change Management, I got the feedback that nowadays, everyone talks about Enterprise Change Management. Engineering Change Management is old school.

In the past, and even in a 2014 benchmark, a customer had two change management systems. One in PLM and one in ERP, and companies were looking into connecting these two processes. Like the BOM-interaction between PLM and ERP, this is technology-wise, never a real problem.
 The real problem in such situations was to come to a logical flow of events. Many times the company insisted that every change should start from the ERP-system as we like to standardize. This means that even an engineering change had to be registered first in the ERP-system
The real problem in such situations was to come to a logical flow of events. Many times the company insisted that every change should start from the ERP-system as we like to standardize. This means that even an engineering change had to be registered first in the ERP-system
Luckily the reach of PLM has grown. PLM is no longer the engineering tool (IT-system thinking). PLM has become the information backbone for product information all along the product lifecycle. Having the MBOM and SBOM available through a PLM-infrastructure allows organizations to streamline their processes.
Aras – digital thread through connected structures
And in this modern environment, enterprise change management might take place mostly in a PLM-infrastructure. The PLM-infrastructure providing a digital thread, as the Aras picture above illustrates, provides the full traceability to support configuration management.
 However, we still have to remember that configuration management and engineering change management, first of all, are based on methodology and processes. Next, the combination of tools to be used will vary.
However, we still have to remember that configuration management and engineering change management, first of all, are based on methodology and processes. Next, the combination of tools to be used will vary.
I like to conclude this topic with a quote from Lee Perrin’s comment on my previous blog post
I would add that aerospace companies implemented CM, to avoid fatal consequences to their companies, but also to their flying customers.
PLM provides the framework within which to carry out Configuration Management. CM can indeed be carried out without PLM, as was done in the old paper-based days. As you have stated, PLM makes the whole CM process much more efficient. I think more transparent too.
Conclusion
After nine posts around the theme Learning from the past to understand the future, I walked through the history of CAD, PDM and PLM in a fast mode, pointing to practices and friction points. In the blogging space, it is hard to find this information as most blog posts are coming from software vendors explaining why their tool is needed. Hopefully, these series have helped many of you to understand a broader context. Now I want to focus on the future again in my upcoming blog posts.
Still, feel free to contact me and discuss methodology topics.
 In the previous seven posts, learning from the past to understand the future, we have seen the evolution from manual 2D drawing handling. Next, the emerge of ERP and CAD followed by data management systems (PDM/PLM) and methodology (EBOM/MBOM) to create an infrastructure for product data from concept towards manufacturing.
In the previous seven posts, learning from the past to understand the future, we have seen the evolution from manual 2D drawing handling. Next, the emerge of ERP and CAD followed by data management systems (PDM/PLM) and methodology (EBOM/MBOM) to create an infrastructure for product data from concept towards manufacturing.
Before discussing the extension to the SBOM-concept, I first want to discuss Engineering Change Management and Configuration Management.
ECM and CM – are they the same?
Often when you talk with people in my PLM bubble, the terms Change Management and Configuration Management are mixed or not well understood.
![]() When talking about Change Management, we should clearly distinguish between OCM (Organizational Change Management) and ECM (Engineering Change Management). In this post, I will focus on Engineering Change Management (ECM).
When talking about Change Management, we should clearly distinguish between OCM (Organizational Change Management) and ECM (Engineering Change Management). In this post, I will focus on Engineering Change Management (ECM).
When talking about Configuration Management also here we find two interpretations of it.
![]() The first one is a methodology describing technically how, in your PLM/CAD-environment, you can build the most efficient way connected data structures, representing all product variations. This technology varies per PLM/CAD-vendor, and therefore I will not discuss it here. The other interpretation of Configuration Management is described on Wiki as follows:
The first one is a methodology describing technically how, in your PLM/CAD-environment, you can build the most efficient way connected data structures, representing all product variations. This technology varies per PLM/CAD-vendor, and therefore I will not discuss it here. The other interpretation of Configuration Management is described on Wiki as follows:
Configuration management (CM) is a systems engineering process for establishing and maintaining consistency of a product’s performance, functional, and physical attributes with its requirements, design, and operational information throughout its life.
This is also the area where I will focus on this time.
And as-if great minds think alike and are synchronized, I was happy to see Martijn Dullaart’s recent blog post, referring to a poll and follow-up article on CM.

Here Martijn precisely touches the topic I address in this post. I recommend you to read his post: Configuration Management done right = Product-Centric first and then follow with the rest of this article.
Engineering Change Management
 Initially, engineering change management was a departmental activity performed by engineering to manage the changes in a product’s definition. Other stakeholders are often consulted when preparing a change, which can be minor (affecting, for example, only engineering) or major (affecting engineering and manufacturing).
Initially, engineering change management was a departmental activity performed by engineering to manage the changes in a product’s definition. Other stakeholders are often consulted when preparing a change, which can be minor (affecting, for example, only engineering) or major (affecting engineering and manufacturing).
The way engineering change management has been implemented varies a lot. Over time companies all around the world have defined their change methodology, and there is a lot of commonality between these approaches. However, terminology as revision, version, major change, minor change all might vary.

I described the generic approach for engineering change processes in my blog post: ECR / ECO for Dummies from 2010.
The fact that companies have defined their own engineering change processes is not an issue when it works and is done manually. The real challenge came with PDM/PLM-systems that need to provide support for engineering change management.
Do you leave the methodology 100 % open, or do you provide business logic?
 I have seen implementations where an engineer with a right-click could release an assembly without any constraints. Related drawings might not exist, parts in the assembly are not released, and more. To obtain a reliable engineering change management process, the company had to customize the PLM-system to its desired behavior.
I have seen implementations where an engineer with a right-click could release an assembly without any constraints. Related drawings might not exist, parts in the assembly are not released, and more. To obtain a reliable engineering change management process, the company had to customize the PLM-system to its desired behavior.
An exercise excellent for a system integrator as there was always a discussion with end-users that do not want to be restricted in case of an emergency (“we will complete the definition later” / “too many clicks” / “do I have to approve 100 parts ?”). In many cases, the system integrator kept on customizing the system to adapt to all wishes. Often the engineering change methodology on paper was not complete or contained contradictions when trying to digitize the processes.
 For that reason, the PLM-vendors that aim to provide Out-Of-The-Box solutions have been trying to predefine certain behaviors in their system. For example, you cannot release a part, when its specifications (drawings/documents) are not released. Or, you cannot update a released assembly without creating a new revision.
For that reason, the PLM-vendors that aim to provide Out-Of-The-Box solutions have been trying to predefine certain behaviors in their system. For example, you cannot release a part, when its specifications (drawings/documents) are not released. Or, you cannot update a released assembly without creating a new revision.
These rules speed-up the implementation; however, they require more OCM (Organizational Change Management) as probably naming and methodology has to change within the company. This is the continuous battle in PLM-implementations. In particular where the company has a strong legacy or lack of business understanding, when implementing PLM.

There is an excellent webcast in this context on Minerva PLM TV – How to Increase IT Project Success with Organizational Change Management.
Click on the image or link to watch this recording.
Configuration Management
When we talk about configuration management, we have to think about managing the consistency of product data along the whole product lifecycle, as we have seen from the Wiki-definition before.

Wiki – the configuration Activity Model
Configuration management existed long before we had IT-systems. Therefore, configuration management is more a collection of activities (see diagram above) to ensure the consistency of information is correct for any given product. Consistent during design, where requirements match product capabilities. Consistent with manufacturing, where the manufacturing process is based on the correct engineering specifications. And consistent with operations, meaning that we have the full definition of product in the field, the As-Built, in correct relation to its engineering and manufacturing definition.

Source: Configuration management in aerospace industry
This consistency is crucial for products where the cost of an error can have a massive impact on the manufacturer. The first industries that invested heavily in configuration management were the Aerospace and Defense industries. Configuration management is needed in these industries as the products are usually complex, and failure can have a fatal impact on the company. Combined with many regulatory constraints, managing the configuration of a product and the impact of changes is a discipline on its own.

Other industries have also introduced configuration management nowadays. The nuclear power industry and the pharmaceutical industry use configuration management as part of their regulatory compliance. The automotive industry requires configuration management partly for compliance, mainly driven by quality targets. An accident or a recall can be costly for a car manufacturer. Other manufacturing companies all have their own configuration management strategies, mainly depending on their own risk assessment. Configuration management is a pro-active discipline – it costs money – time, people and potential tools to implement it. In my experience, many of these companies try to do “some” configuration management, always hoping that a real disaster will not happen (or can happen). Proper configuration management allows you to perform reliable impact analysis for any change (image above)
What happens in the field?
 When introducing PLM in mid-market companies, often, the dream was that with the new PLM-system configuration, management would be there too.
When introducing PLM in mid-market companies, often, the dream was that with the new PLM-system configuration, management would be there too.
Management believes the tools will fix the issue.
Partly because configuration management deals with a structured approach on how to manage changes, there was always confusion with engineering change management. Modern PLM-systems all have an impact analysis capability. However, most of the time, this impact analysis only reaches the content that is in the PLM-system. Configuration Management goes further.
If you think that configuration management is crucial for your company, start educating yourselves first before implementing anything in a tool. There are several places where you can learn all about configuration management.
![]()
- Probably the best-known organization is IpX (Institute for Process Excellence), teaching the CM2 methodology. Have a look here: CM2 certification and courses
- Closely related to IpX, Martijn Dullaart shares his thoughts coming from the field as Lead Architect for Enterprise Configuration Management at ASML (one of the Dutch crown jewels) in his blog: MDUX
- CMstat, a configuration and data management solution provider, provides educational posts from their perspective. Have a look at their posts, for example, PLM or PDM or CM
- If you want to have a quick overview of Configuration Management in general, targeted for the mid-market, have a look at this (outdated) course: Training for Small and Medium Enterprises on CONFIGURATION MANAGEMENT. Good for self-study to get an understanding of the domain.
To summarize
 In regulated industries, Configuration Management and PLM are a must to ensure compliance and quality. Configuration management and (engineering) change management are, first of all, required methodologies that guarantee the quality of your products. The more complex your products are, the higher the need for change and configuration management.
In regulated industries, Configuration Management and PLM are a must to ensure compliance and quality. Configuration management and (engineering) change management are, first of all, required methodologies that guarantee the quality of your products. The more complex your products are, the higher the need for change and configuration management.
PLM-systems require embedded engineering change management – part of the PDM domain. Performing Engineering Change Management in a system is something many users do not like, as it feels like overhead. Too much administration or too many mouse clicks.
So far, there is no golden egg that performs engineering change management automatically. Perhaps in a data-driven environment, algorithms can speed-up change management processes. Still, there is a need for human decisions.
Similar to configuration management. If you have a PLM-system that connects all the data from concept, design, and manufacturing in a single environment, it does not mean you are performing configuration management. You need to have processes in place, and depending on your product and industry, the importance will vary.
Conclusion
In the first seven posts, we discussed the design and engineering practices, from CAD to EBOM, ending with the MBOM. Engineering Change Management and, in particular, Configuration Management are methodologies to ensure the consistency of data along the product lifecycle. These methodologies are connected and need to be fit for the future – more on this when we move to modern model-based approaches.
Closing note:
 While finishing this blog post today I read Jan Bosch’s post: Why you should not align. Jan touches the same topic that I try to describe in my series Learning from the Past ….., as my intention is to make us aware that by holding on to practices from the past we are blocking our future. Highly recommended to read his post – a quote:
While finishing this blog post today I read Jan Bosch’s post: Why you should not align. Jan touches the same topic that I try to describe in my series Learning from the Past ….., as my intention is to make us aware that by holding on to practices from the past we are blocking our future. Highly recommended to read his post – a quote:
The problem is, of course, that every time you resist change, you get a bit behind. You accumulate some business, process and technical debt. You become a little less “fitting” to the environment in which you’re operating

Hi Jos, Knowing your background in methodology and education, I wanted to share a longer article with you: “What is…
Interesting reflection, Jos. In my experience, the situation you describe is very recognizable. At the company where I work, sustainability…
[…] (The following post from PLM Green Global Alliance cofounder Jos Voskuil first appeared in his European PLM-focused blog HERE.) […]
[…] recent discussions in the PLM ecosystem, including PSC Transition Technologies (EcoPLM), CIMPA PLM services (LCA), and the Design for…
Jos, all interesting and relevant. There are additional elements to be mentioned and Ontologies seem to be one of the…