
You are currently browsing the category archive for the ‘IP Security’ category.
 In my last post in this series, The road to model-based and connected PLM, I mentioned that perhaps it is time to talk about SLM instead of PLM when discussing popular TLA’s for our domain of expertise. There were not so many encouraging statements for SLM so far.
In my last post in this series, The road to model-based and connected PLM, I mentioned that perhaps it is time to talk about SLM instead of PLM when discussing popular TLA’s for our domain of expertise. There were not so many encouraging statements for SLM so far.
SLM could mean for me, Solution Lifecycle Management, considering that the company’s offering more and more is a mix of products and services. Or SLM could mean System Lifecycle Management, in that case pushing the idea that more and more products are interacting with the outside world and therefore could be considered systems. Products are (almost) dead.
In addition, I mentioned that the typical product lifecycle and related configuration management concepts need to change as in the SLM domain. There is hardware and software with different lifecycles and change processes.
 It is a topic I want to explore further. I am curious to learn more from Martijn Dullaart, who will be lecturing at the PLM Road map and PDT 2021 fall conference in November. I hope my expectations are not too high, knowing it is a topic of interest for Martijn. Feel free to join this discussion
It is a topic I want to explore further. I am curious to learn more from Martijn Dullaart, who will be lecturing at the PLM Road map and PDT 2021 fall conference in November. I hope my expectations are not too high, knowing it is a topic of interest for Martijn. Feel free to join this discussion
In this post, it is time to follow up on my third statement related to what data-driven implies:
Data-driven means that we need to manage data in a much more granular manner. We have to look different at data ownership. It becomes more about data accountability per role as the data can be used and consumed throughout the product lifecycle
On this topic, I have a list of points to consider; let’s go through them.
The dataset
In this post, I will often use the term dataset (you are also allowed to write the data set I understood).
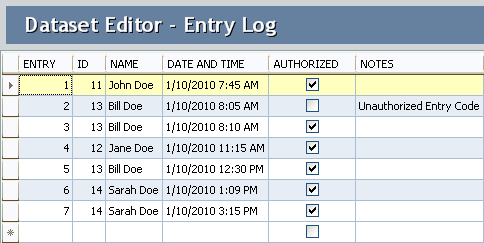 A dataset means a predefined number of attributes and values that belong logically to each other. Datasets should be defined based on the purpose and, if possible, designated for a single goal. In this way, they can be stored in a database.
A dataset means a predefined number of attributes and values that belong logically to each other. Datasets should be defined based on the purpose and, if possible, designated for a single goal. In this way, they can be stored in a database.
Combined with other datasets, a combination can result in relevant business information. Note a dataset is not only transactional data; a dataset could also describe geometry.
Identify the dataset
 In the document-based world, a lot of information could be stored in a single file. In a data-driven world, we should define a dataset that contains a specific piece of information, logically belonging together. If we are more precise, a part would have various related datasets that make up the definition of a part. These definitions could be:
In the document-based world, a lot of information could be stored in a single file. In a data-driven world, we should define a dataset that contains a specific piece of information, logically belonging together. If we are more precise, a part would have various related datasets that make up the definition of a part. These definitions could be:
- Core identification attributes like ID, Name, Type and Status
- The Type could define a set of linked information. For example, a valve would have different characteristics as a resistor. Through classification, we can link data sets to the core definition of a part.
- The part can have engineering-specific data (CAD and metadata), manufacturing-specific data, supplier-specific data, and service-specific data. Each of these datasets needs to be defined as a unique element in a data-driven environment
- CAD is a particular case as most current CAD systems don’t treat geometry as a single dataset. In a file-based world, many other datasets are stored in the file (e.g., engineering or manufacturing details). In a data-driven environment, we want to have the CAD definition to be treated like a dataset. Dassault Systèmes with their CATIA V6 and 3DEXPERIENCE platform or PTC with OnShape are examples of this approach.Having CAD as separate datasets makes sharing and collaboration so much easier, as we can see from these solutions. The concept for CAD stored in a database is not new, and this approach has been used in various disciplines. Mechanical CAD was always a challenge.
![]() Thanks to Moore’s Law (approximate every 2 years, processor power doubled – click on the image for the details) and higher network connection speed, it starts to make sense to have mechanical CAD also stored in a database instead of a file
Thanks to Moore’s Law (approximate every 2 years, processor power doubled – click on the image for the details) and higher network connection speed, it starts to make sense to have mechanical CAD also stored in a database instead of a file
An important point to consider is a kind of standardization of datasets. In theory, there should be a kind of minimum agreed collection of datasets. Industry standards provide these collections in their dictionary. Whenever you optimize your data model for a connected enterprise, make sure you look first into the standards that apply to your industry.
 They might not be perfect or complete, but inventing your own new standard is a guarantee for legacy issues in the future. This remark is also valid for the software vendors in this domain. A proprietary data model might give you a competitive advantage.
They might not be perfect or complete, but inventing your own new standard is a guarantee for legacy issues in the future. This remark is also valid for the software vendors in this domain. A proprietary data model might give you a competitive advantage.
Still, in the long term, there is always the need to connect with outside stakeholders.
Identify the RACI
To ensure a dataset is complete and well maintained, the concept of RACI could be used. RACI is the abbreviation for Responsible Accountable Consulted and Informed and a simplification of the RASCI Model, see also a responsibility assignment matrix.
 In a data-driven environment, there is no data ownership anymore like you have for documents. The main reason that data ownership can no longer be used is that datasets can be consumed by anyone in the ecosystem. No longer only your department or the manufacturing or service department.
In a data-driven environment, there is no data ownership anymore like you have for documents. The main reason that data ownership can no longer be used is that datasets can be consumed by anyone in the ecosystem. No longer only your department or the manufacturing or service department.
Data sets in a data-driven environment bring value when connected with other datasets in applications or dashboards.
A dataset describing the specification attributes of a part could be used in a spare part app and a service app. Of course, the dataset will be used in a different context – still, we need to ensure we can trust the data.
Therefore, per identified dataset, there should be governed by a kind of RACI concept. The RACI concept is a way to break the siloes in an organization.
Identify Inside / outside
There is a lot of fear that a connected, data-driven environment will expose Intellectual Property (IP). It came up in recent discussions. If you like storytelling and technology, read my old SmarTeam colleague Alex Bruskin’s post: The Bilbo Baggins Threat to PLM Assets. Alex has written some “poetry” with a deep technical message behind it.
 It is true that if your data set is too big, you have the challenge of exposing IP when connecting this dataset with others. Therefore, when building a data model, you should make it possible to have datasets pure for internal usage and datasets for sharing.
It is true that if your data set is too big, you have the challenge of exposing IP when connecting this dataset with others. Therefore, when building a data model, you should make it possible to have datasets pure for internal usage and datasets for sharing.
When you use the concept of RACI, the difference should be defined by the I(informed) – is it PLM-data or PIM-data for example?
Tracking relations
Suppose we follow up on the concept of datasets. In that case, it becomes clear that relations between the datasets are as crucial as the dataset. In traditional PLM applications, these relations are often predefined as part of the core data model/
 For example, the EBOM parts have relationships between themselves and specification data – see image.
For example, the EBOM parts have relationships between themselves and specification data – see image.
The MBOM parts have links with the supplier data or the manufacturing process.
The prepared relations in a PLM system allow people to implement the system relatively quickly to map their approaches to this taxonomy.
 However, traditional PLM systems are based on a document-based (or file-based) taxonomy combined with related metadata. In a model-based and connected environment, we have to get rid of the document-based type of data.
However, traditional PLM systems are based on a document-based (or file-based) taxonomy combined with related metadata. In a model-based and connected environment, we have to get rid of the document-based type of data.
Therefore, the datasets will be more granular, and there is a need to manage exponential more relations between datasets.
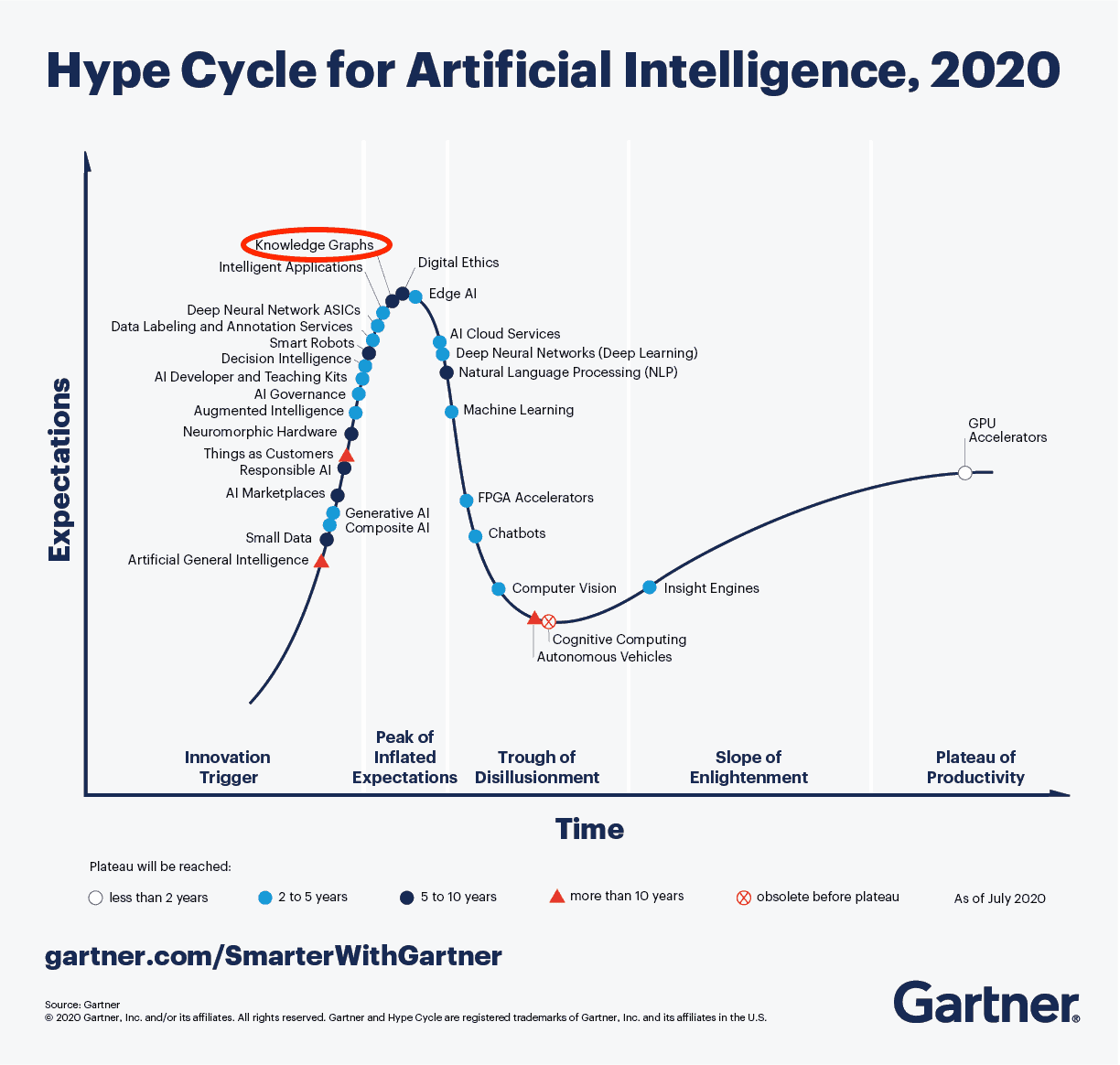 This is why you see the graph database coming up as a needed infrastructure for modern connected applications. If you haven’t heard of a graph database yet, you are probably far from technology hypes. To understand the principles of a graph database you can read this article from neo4j: Graph Databases for Beginners: Why graph technology is the future
This is why you see the graph database coming up as a needed infrastructure for modern connected applications. If you haven’t heard of a graph database yet, you are probably far from technology hypes. To understand the principles of a graph database you can read this article from neo4j: Graph Databases for Beginners: Why graph technology is the future
As you can see from the 2020 Gartner Hype Cycle for Artificial Intelligence this technology is at the top of the hype and conceptually the way to manage a connected enterprise. The discussion in this post also demonstrates that besides technology there is a lot of additional conceptual thinking needed before it can be implemented.
Although software vendors might handle the relations and datasets within their platform, the ultimate challenge will be sharing datasets with other platforms to get a connected ecosystem.
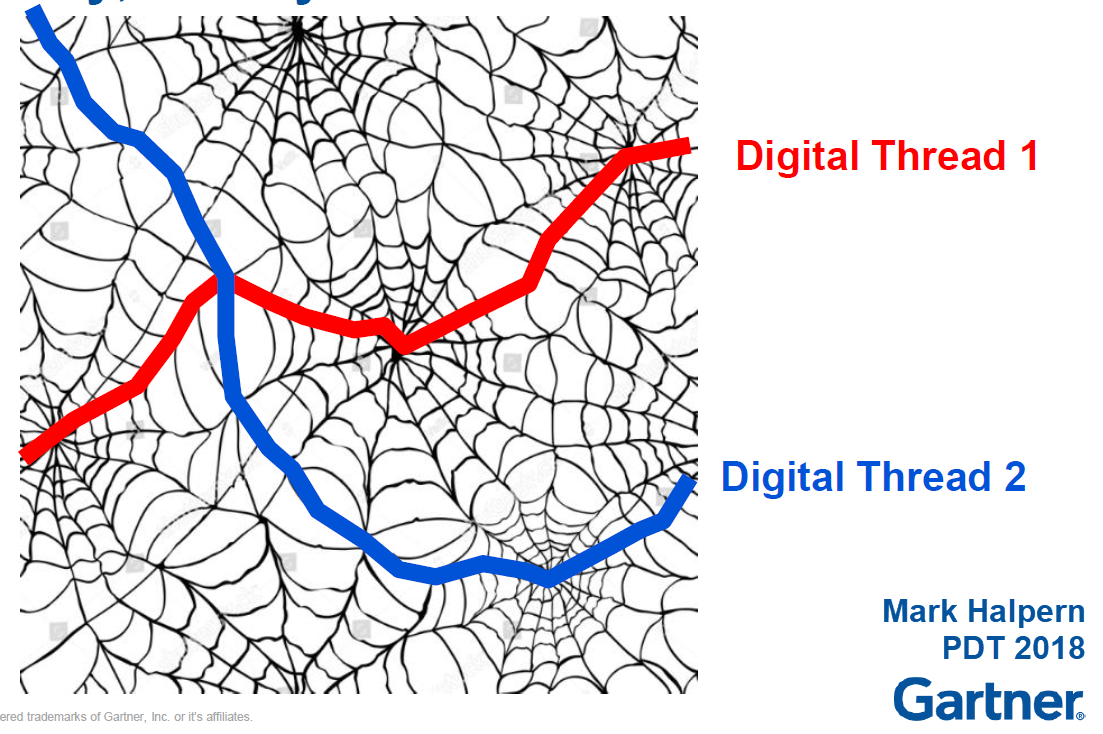
For example, the digital web picture shown above and introduced by Marc Halpern at the 2018 PDT conference shows this concept. Recently CIMdata discussed this topic in a similar manner: The Digital Thread is Really a Web, with the Engineering Bill of Materials at Its Center
(Note I am not sure if CIMdata has published a recording of this webinar – if so I will update the link)
Anyway, these are signs that we started to find the right visuals to imagine new concepts. The traditional digital thread pictures, like the one below, are, for me, impressions of the past as they are too rigid and focusing on some particular value streams.
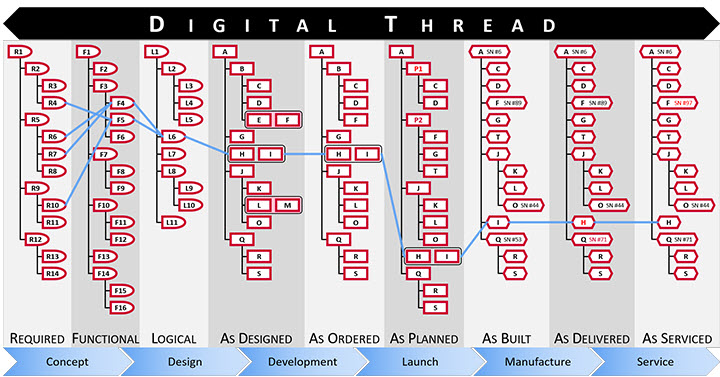
From a distance, it looks like a connected enterprise should work like our brain. We story information on different abstraction levels. We keep incredibly many relations between information elements. As the brain is a biological organ, connections degrade or get lost. Or the opposite other relationships become so strong that we cannot change them anymore. (“I know I am always right”)
 Interestingly, the brain does not use the “single source of truth”-concept – there can be various “truths” inside a brain. This makes us human beings with all the good and the harmful effects of that.
Interestingly, the brain does not use the “single source of truth”-concept – there can be various “truths” inside a brain. This makes us human beings with all the good and the harmful effects of that.
As long as we realize there is no single source of truth.
In business and our technological world, we need sometimes the undisputed truth. Blockchain could be the basis for securing the right connections between datasets to guarantee the result is valid. I am curious if blockchain can scale to complex connected situations, although Moore’s Law might ultimately help us here too(if still valid).
 The topic is not new – in 2014 I wrote a post with the title: PLM is doomed unless …. Where I introduced the topic of owning and sharing in the context of the human brain. In the post, I refer to the book On Intelligence by Jeff Hawkins how tries to analyze what is human-based intelligence and how could we apply it to our technology concepts. Still a fascinating book worth reading if you have the time and opportunity.
The topic is not new – in 2014 I wrote a post with the title: PLM is doomed unless …. Where I introduced the topic of owning and sharing in the context of the human brain. In the post, I refer to the book On Intelligence by Jeff Hawkins how tries to analyze what is human-based intelligence and how could we apply it to our technology concepts. Still a fascinating book worth reading if you have the time and opportunity.
Conclusion
A data-driven approach requires a more granular definition of information, leading to the concepts of datasets and managing relations between datasets. This is a fundamental difference compared to the past, where we were operating systems with information. Now we are heading towards connected platforms that provide a filtered set of real-time data to act upon.
I am curious to learn more about how people have solved the connected challenges and in what kind of granularity. Let us know!
After a short summer break with almost no mentioning of the word PLM, it is time to continue this series of posts exploring the future of “connected” PLM. For those who also started with a cleaned-up memory, here is a short recap:
 In part 1, I rush through more than 60 years of product development, starting from vellum drawings ending with the current PLM best practice for product development, the item-centric approach.
In part 1, I rush through more than 60 years of product development, starting from vellum drawings ending with the current PLM best practice for product development, the item-centric approach.
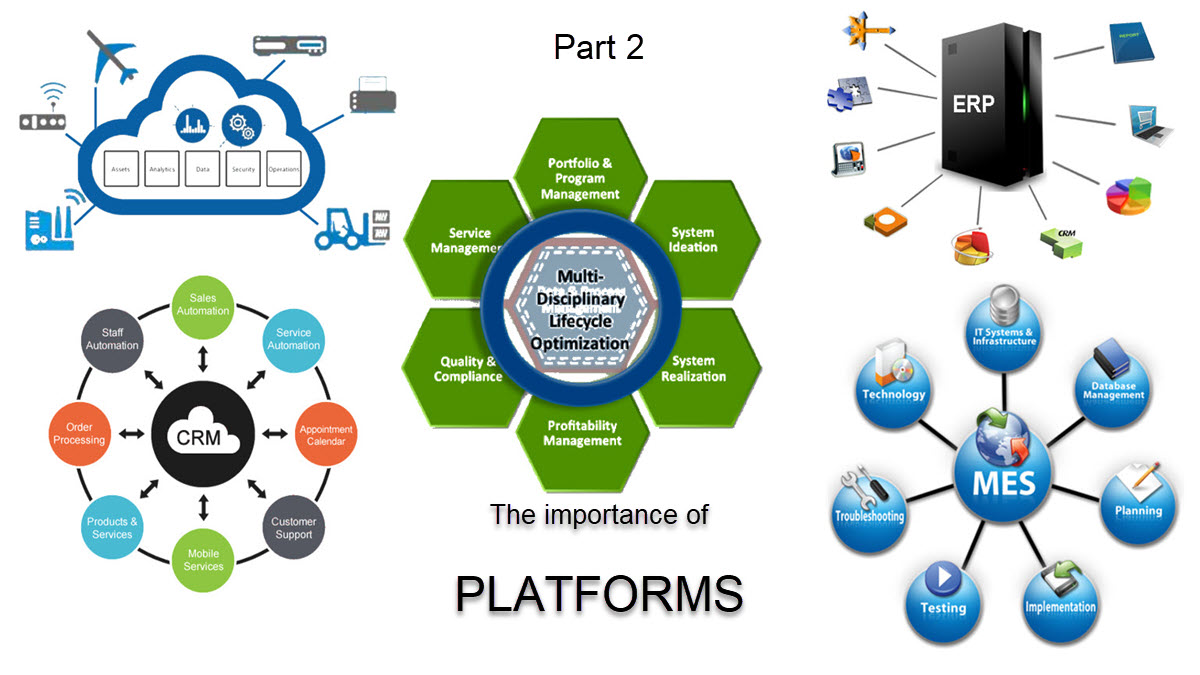 In part 2, I painted a high-level picture of the future, introducing the concept of digital platforms, which, if connected wisely, could support the digital enterprise in all its aspects. The five platforms I identified are the ERP and CRM platform (the oldest domains).
In part 2, I painted a high-level picture of the future, introducing the concept of digital platforms, which, if connected wisely, could support the digital enterprise in all its aspects. The five platforms I identified are the ERP and CRM platform (the oldest domains).
Next, the MES and PIP platform(modern domains to support manufacturing and product innovation in more detail) and the IoT platform (needed to support connected products and customers).
 In part 3, I explained what is data-driven and how data-driven is closely connected to a model-based approach. Here we abandon documents (electronic files) as active information carriers. Documents will remain, however, as reports, baselines, or information containers. In this post, I ended up with seven topics related to data-driven, which I will discuss in upcoming posts.
In part 3, I explained what is data-driven and how data-driven is closely connected to a model-based approach. Here we abandon documents (electronic files) as active information carriers. Documents will remain, however, as reports, baselines, or information containers. In this post, I ended up with seven topics related to data-driven, which I will discuss in upcoming posts.
Hopefully, by describing these topics – and for sure, there are more related topics – we will better understand the connected future and make decisions to enable the future instead of freezing the past.
Topic 1 for this post:
Data-driven does not imply, there needs to be a single environment, a single database that contains all information. As I mentioned in my previous post, it will be about managing connected datasets federated. It is not anymore about owned the data; it is about access to reliable data.
Platform or a collection of systems?
One of the first (marketing) hurdles to take is understanding what a data platform is and what is a collection of systems that work together, sold as a platform.
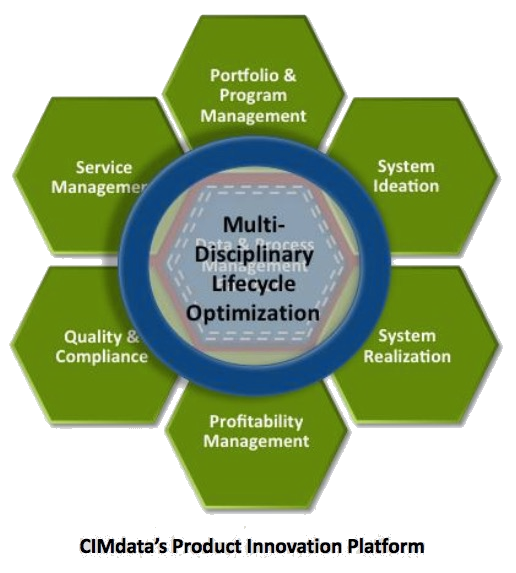 CIMdata published in 2017 an excellent whitepaper positioning the PIP (Product Innovation Platform): Product Innovation Platforms: Definition, Their Role in the Enterprise, and Their Long-Term Viability. CIMdata’s definition is extensive and covers the full scope of product innovation. Of course, you can find a platform that starts from a more focused process.
CIMdata published in 2017 an excellent whitepaper positioning the PIP (Product Innovation Platform): Product Innovation Platforms: Definition, Their Role in the Enterprise, and Their Long-Term Viability. CIMdata’s definition is extensive and covers the full scope of product innovation. Of course, you can find a platform that starts from a more focused process.
For example, look at OpenBOM (focus on BOM collaboration), OnShape (focus on CAD collaboration) or even Microsoft 365 (historical, document-based collaboration).
The idea behind a platform is that it provides basic capabilities connected to all stakeholders, inside and outside your company. In addition, to avoid that these capabilities are limited, a platform should be open and able to connect with other data sources that might be either local or central available.
 From these characteristics, it is clear that the underlying infrastructure of a platform must be based on a multitenant SaaS infrastructure, still allowing local data to be connected and shielded for performance or IP reasons.
From these characteristics, it is clear that the underlying infrastructure of a platform must be based on a multitenant SaaS infrastructure, still allowing local data to be connected and shielded for performance or IP reasons.
The picture below describes the business benefits of a Product Innovation Platform as imagined by Accenture in 2014

Link to CIMdata’s 2014 commentary of Digital PLM HERE
 Sometimes vendors sell their suite of systems as a platform. This is a marketing trick because when you want to add functionality to your PLM infrastructure, you need to install a new system and create or use interfaces with the existing systems, not really a scalable environment.
Sometimes vendors sell their suite of systems as a platform. This is a marketing trick because when you want to add functionality to your PLM infrastructure, you need to install a new system and create or use interfaces with the existing systems, not really a scalable environment.
In addition, sometimes, the collaboration between systems in such a marketing platform is managed through proprietary exchange (file) formats.
 A practice we have seen in the construction industry before cloud connectivity became available. However, a so-called end-to-end solution working on PowerPoint implemented in real life requires a lot of human intervention.
A practice we have seen in the construction industry before cloud connectivity became available. However, a so-called end-to-end solution working on PowerPoint implemented in real life requires a lot of human intervention.
Not a single environment
There has always been the debate:
“Do I use best-in-class tools, supporting the end-user of the software, or do I provide an end-to-end infrastructure with more generic tools on top of that, focusing on ease of collaboration?”
In the system approach, the focus was most of the time on the best-in-class tools where PLM-systems provide the data governance. A typical example is the item-centric approach. It reflects the current working culture, people working in their optimized siloes, exchanging information between disciplines through (neutral) files.
The platform approach makes it possible to deliver the optimized user interface for the end-user through a dedicated app. Assuming the data needed for such an app is accessible from the current platform or through other systems and platforms.
 It might be tempting as a platform provider to add all imaginable data elements to their platform infrastructure as much as possible. The challenge with this approach is whether all data should be stored in a central data environment (preferably cloud) or federated. And what about filtering IP?
It might be tempting as a platform provider to add all imaginable data elements to their platform infrastructure as much as possible. The challenge with this approach is whether all data should be stored in a central data environment (preferably cloud) or federated. And what about filtering IP?
In my post PLM and Supply Chain Collaboration, I described the concept of having an intermediate hub (ShareAspace) between enterprises to facilitate real-time data sharing, however carefully filtered which data is shared in the hub.

It may be clear that storing everything in one big platform is not the future. As I described in part 2, in the end, a company might implement a maximum of five connected platforms (CRM, ERP, PIP, IoT and MES). Each of the individual platforms could contain a core data model relevant for this part of the business. This does not imply there might be no other platforms in the future. Platforms focusing on supply chain collaboration, like ShareAspace or OpenBOM, will have a value proposition too. In the end, the long-term future is all about realizing a digital tread of information within the organization.
 Will we ever reach a perfectly connected enterprise or society? Probably not. Not because of technology but because of politics and human behavior. The connected enterprise might be the most efficient architecture, but will it be social, supporting all humanity. Predicting the future is impossible, as Yuval Harari described in his book: 21 Lessons for the 21st Century. Worth reading, still a collection of ideas.
Will we ever reach a perfectly connected enterprise or society? Probably not. Not because of technology but because of politics and human behavior. The connected enterprise might be the most efficient architecture, but will it be social, supporting all humanity. Predicting the future is impossible, as Yuval Harari described in his book: 21 Lessons for the 21st Century. Worth reading, still a collection of ideas.
Proprietary data model or standards?
So far, when you are a software vendor developing a system, there is no restriction in how you internally manage your data. In the domain of PLM, this meant that every vendor has its own proprietary data model and behavior.
 I have learned from my 25+ years of experience with systems that the original design of a product combined with the vendor’s culture defines the future roadmap. So even if a PLM vendor would rewrite all their software to become data-driven, the ways of working, the assumptions will be based on past experiences.
I have learned from my 25+ years of experience with systems that the original design of a product combined with the vendor’s culture defines the future roadmap. So even if a PLM vendor would rewrite all their software to become data-driven, the ways of working, the assumptions will be based on past experiences.
This makes it hard to come to unified data models and methodology valid for our PLM domain. However, large enterprises like Airbus and Boeing and the major Automotive suppliers have always pushed for standards as they will benefit the most from standardization.
 The recent PDT conferences were an example of this, mainly the 2020 Fall conference. Several Aerospace & Defense PLM Action groups reported their progress.
The recent PDT conferences were an example of this, mainly the 2020 Fall conference. Several Aerospace & Defense PLM Action groups reported their progress.
You can read my impression of this event in The weekend after PLM Roadmap / PDT 2020 – part 1 and The next weekend after PLM Roadmap PDT 2020 – part 2.
It would be interesting to see a Product Innovation Platform built upon a data model as much as possible aligned to existing standards. Probably it won’t happen as you do not make money from being open and complying with standards as a software vendor. Still, companies should push their software vendors to support standards as this is the only way to get larger connected eco-systems.
 I do not believe in the toolkit approach where every company can build its own data model based on its current needs. I have seen this flexibility with SmarTeam in the early days. However, it became an upgrade risk when new, overlapping capabilities were introduced, not matching the past.
I do not believe in the toolkit approach where every company can build its own data model based on its current needs. I have seen this flexibility with SmarTeam in the early days. However, it became an upgrade risk when new, overlapping capabilities were introduced, not matching the past.
 In addition, a flexible toolkit still requires a robust data model design done by experienced people who have learned from their mistakes.
In addition, a flexible toolkit still requires a robust data model design done by experienced people who have learned from their mistakes.
The benefit of using standards is that they contain the learnings from many people involved.
Conclusion
I did not like writing this post so much, as my primary PLM focus lies on people and methodology. Still, understanding future technologies is an important point to consider. Therefore, this time a not-so-exciting post. There is enough to read on the internet related to PLM technology; see some of the recent articles below. Enjoy
Matthias Ahrens shared: Integrated Product Lifecycle Management (Google translated from German)
Oleg Shilovitsky wrote numerous articles related to technology –
in this context:
3 Challenges of Unified Platforms and System Locking and
SaaS PLM Acceleration Trends
 Two terms pass me every day: Digital Transformation appears in every business discussion, and IP Security, a topic also discussed in all parts of society. We realize it is easy to steal electronic data without being detected (immediately).
Two terms pass me every day: Digital Transformation appears in every business discussion, and IP Security, a topic also discussed in all parts of society. We realize it is easy to steal electronic data without being detected (immediately).
What is Digital Transformation?
Digital Transformation is reshaping business processes to enable new business models, create a closer relation with the market, and react faster while reducing the inefficiencies of collecting, converting and processing analog or disconnected information.
Digital Transformation became possible thanks to the lower costs of technology and global connectivity, allowing companies, devices, and customers to interact in almost real-time when they are connected to the internet.
 IoT (Internet of Things) and IIoT (Industrial Internet of Things) are terms closely related to Digital Transformation. Their focus is on creating connectivity with products (systems) in the field, providing a tighter relation with the customer and enabling new (upgrade) services to gain better performance. Every manufacturing company should be exploring IoT and IIoT possibilities now.
IoT (Internet of Things) and IIoT (Industrial Internet of Things) are terms closely related to Digital Transformation. Their focus is on creating connectivity with products (systems) in the field, providing a tighter relation with the customer and enabling new (upgrade) services to gain better performance. Every manufacturing company should be exploring IoT and IIoT possibilities now.
Digital Transformation is also happening in the back office of companies. The target is to create a digital data flow inside the company and with the outside stakeholders, e.g., customers, suppliers, authorities. The benefits are mainly improved efficiency, faster response and higher quality interaction with the outside world.
 The part of Digital Transformation that concerns me the most is the domain of PLM. As I have stated in earlier posts (Best Practices or Next Practices ? / What is Digital PLM ?), the need is to replace the classical document-driven product to market approach by a modern data-driven interaction of products and services.
The part of Digital Transformation that concerns me the most is the domain of PLM. As I have stated in earlier posts (Best Practices or Next Practices ? / What is Digital PLM ?), the need is to replace the classical document-driven product to market approach by a modern data-driven interaction of products and services.
I am continually surprised that companies with an excellent Digital Transformation profile on their websites have no clue about Digital Transformation in their product innovation domain. Marketing is faster than reality.
 I am happy to discuss this topic with many of my peers in the product innovation world @ PI Berlin 2017, three weeks from now. I am eagerly looking to look at how and why companies do not embrace the Digital Transformation sooner and faster. The theme of the conference, “Digital Transformation: From Hype to Value “ says it all. You can find the program here, and I will report about this conference the weekend after.
I am happy to discuss this topic with many of my peers in the product innovation world @ PI Berlin 2017, three weeks from now. I am eagerly looking to look at how and why companies do not embrace the Digital Transformation sooner and faster. The theme of the conference, “Digital Transformation: From Hype to Value “ says it all. You can find the program here, and I will report about this conference the weekend after.
IP Security
The topic of IP protection has always been high on the agenda of manufacturing companies. Digital Transformation brings new challenges. Digital information will be stored somewhere on a server and probably through firewalls connected to the internet. Some industries have high-security policies, with separate networks for their operational environments. Still, many large enterprises are currently struggling with IP security policies as sharing data while protecting IP between various systems creates a lot of administration per system.
 Cloud solutions for sharing data are still a huge security risk. Where is the data stored and who else have access to it? Dropbox came in the news recently as “deleted” data came back after five years, “due to a bug.” Cloud data sharing cannot be trusted for real sensitive information.
Cloud solutions for sharing data are still a huge security risk. Where is the data stored and who else have access to it? Dropbox came in the news recently as “deleted” data came back after five years, “due to a bug.” Cloud data sharing cannot be trusted for real sensitive information.
Cloud providers always claim that their solutions are safer due to their strict safety procedures compared to the improvident behavior of employees. And, this is true. For example, a company I worked with had implemented Digital Rights Management (DRM) for internal sharing of their IP, making sure that users could only read information on the screen, and not store it locally if they had an issue with the server. “No problem”, one of the employees said, “I have here a copy of the documents on my USB-drive.”
 Cloud-based PLM systems are supposed to be safer. However, it still matters where the data is stored; security and hacking policies of countries vary. Assume your company´s IP is safe for hacking. Then the next question is “How about ownership of your data?”
Cloud-based PLM systems are supposed to be safer. However, it still matters where the data is stored; security and hacking policies of countries vary. Assume your company´s IP is safe for hacking. Then the next question is “How about ownership of your data?”
Vendor lock-in and ownership of data are topics that always comes back at the PDT conferences (see my post on PDT2016). When a PLM cloud provider stores your product data in a proprietary data format, you will always be forced to have a costly data migration project when you decide to change from the provider.
Why not use standards for data storage? Hakan Kårdén triggered me on this topic again with his recent post: Data Is The New Oil So Make Sure You Ask For The Right Quality.
Conclusion:
Digital Transformation is happening everywhere but not always with the same pace and focus. New PLM practices still need to be implemented on a larger scale to become best practices. Digital information in the context of Intellectual Property creates extra challenges to be solved. Cloud providers do not offer yet solutions that are safe and avoiding vendor lock-in.
Be aware. To be continued…
Many thanks (again) to Dick Bourke for his editing suggestions

Hi Jos, Knowing your background in methodology and education, I wanted to share a longer article with you: “What is…
Interesting reflection, Jos. In my experience, the situation you describe is very recognizable. At the company where I work, sustainability…
[…] (The following post from PLM Green Global Alliance cofounder Jos Voskuil first appeared in his European PLM-focused blog HERE.) […]
[…] recent discussions in the PLM ecosystem, including PSC Transition Technologies (EcoPLM), CIMPA PLM services (LCA), and the Design for…
Jos, all interesting and relevant. There are additional elements to be mentioned and Ontologies seem to be one of the…