
 In nearly twenty years of coaching PLM implementations, I’ve noticed something striking: these projects often mirror politics—not just in complexity, but in the blame game that follows when things go wrong.
In nearly twenty years of coaching PLM implementations, I’ve noticed something striking: these projects often mirror politics—not just in complexity, but in the blame game that follows when things go wrong.
When something goes wrong, people rarely see it as an opportunity to solve the issue together. They look for someone to blame instead.
That happens in politics and in Product Lifecycle Management. I wrote about it in 2019, The PLM Blame Game—and most of those observations still hold—although the emphasis has shifted.
But what if the real issue isn’t the system or the technology? What if it’s the human connections—or lack thereof—that determine success?
Political systems/ PLM approaches
In democracies, everyone debates priorities, but progress is slow. Stakeholders defend their own interests, consultants favor preferred solutions, and vendors promise the moon. Long-term plans such as digital transformation often stall.
![]() The result is familiar: each leadership change resets ambitions, leaving users with mixed messages and less commitment – sounds familiar in PLM?.
The result is familiar: each leadership change resets ambitions, leaving users with mixed messages and less commitment – sounds familiar in PLM?.
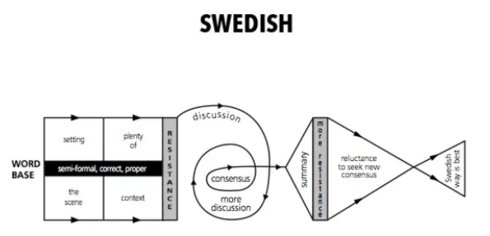
From: Communication charts around the world
Then there are the autocracies, where a single dominant view determines the path. Usually, that view comes not from the CEO but from the CFO or CIO. These leaders often have a limited understanding of product lifecycle management and instead rely on trusted networks.
That is why some companies choose SAP because “all enterprises run on SAP” or Teamcenter because “everyone in automotive uses Teamcenter.” Strategic consultants reinforce the same pattern with their own preferred solutions.
![]() The result: Surface-level alignment, but resistance beneath the surface—another familiar PLM scenario.
The result: Surface-level alignment, but resistance beneath the surface—another familiar PLM scenario.
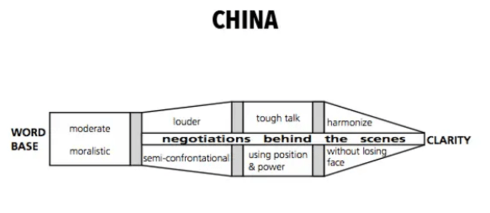
From: Communication charts around the world – 2014 China
In smaller companies, a populist version often appears. Without a strong strategic layer, the loudest voices from vendors and implementers shape the company’s view. That is the riskiest setup because vision and strategy are effectively outsourced. Early in my career, I often heard:
“You know solution XYZ, so tell us what to do.”
![]() The result is predictable: no one in the company feels a true sense of ownership of the business outcome – the type of situations I have been mediating the most.
The result is predictable: no one in the company feels a true sense of ownership of the business outcome – the type of situations I have been mediating the most.

Of course, the analogy is imperfect. Countries usually lack competition, so citizens cannot simply switch. Still, it is a useful way to frame what happens in PLM.
They – not us – are the problem!
 In the past, debates focused on who was to blame for project problems, often blaming the stakeholder who was not at the table.
In the past, debates focused on who was to blame for project problems, often blaming the stakeholder who was not at the table.
Vendors and implementers blamed customers, vendors and customers blamed implementers, and implementers blamed vendors. My role in PLM mediations was to get everyone into the same room.
 But one issue always remained:
But one issue always remained:
Blaming the customer is difficult when the customer is assumed to be right – They are paying the bill and not always with pleasure.
Why 70 % of PLM implementations fail – or not?
 For decades, we have heard horror stories about failed PLM implementations, each supposedly explained by one simple cause.
For decades, we have heard horror stories about failed PLM implementations, each supposedly explained by one simple cause.
Depending on who tells the story, the culprit is the software, the company culture, poor user involvement, or unrealistic ambitions without a budget or understanding.
![]() But the truth is more nuanced: many of these implementations did not actually fail completely.
But the truth is more nuanced: many of these implementations did not actually fail completely.
People react strongly to the word failure because no one wants to be associated with it.

Yet, in software, ‘failing fast’ is often celebrated—it’s a way to adapt early. PLM is slowly catching on, with the rise of Minimum Viable Product (MVP) approaches. Instead of waiting for a ‘perfect’ big-bang rollout, companies now start with a working foundation and iterate as needs emerge.”
 That only works if the company owns its vision and strategy. An MVP approach also demands end-to-end stakeholder involvement, because everyone contributes to the solution. At the same time, our limbic brain works against us: it pushes us to protect what we know and react strongly to change.
That only works if the company owns its vision and strategy. An MVP approach also demands end-to-end stakeholder involvement, because everyone contributes to the solution. At the same time, our limbic brain works against us: it pushes us to protect what we know and react strongly to change.
That reaction shows up in PLM projects too. The loudest critics get the most attention, which makes it easy to conclude a program failed—even when it is working for most people who have adapted to the change.
And now, a new trend has emerged:
PLM systems are failing!
Now, a new claim is gaining traction: PLM systems themselves are failing. With the rise of AI, traditional vendors are being blamed for failing to provide the right infrastructure or opportunities for AI-enabled capabilities.

After years of success built on legacy platforms, vendors now face growing pressure from opinion leaders calling for change.
 Martin Eigner has made this point in several posts:
Martin Eigner has made this point in several posts:
- Why We’re “Optimizing” Problems We Created Ourselves
- 50 % failure rate is not an accident
- My vision for the next 5 years
 Oleg Shilovitsky has made similar arguments:
Oleg Shilovitsky has made similar arguments:
- Did We Solve PLM, or Just Learn How to Describe It?
- Who can replace the big three PLM and why that may be the wrong question in the Age of AI?
- Is Product Memory Just a New Name for PLM?
 Prof. Dr. Jörg W. Fischer wrote:
Prof. Dr. Jörg W. Fischer wrote:
- Will we ever solve PLM? We did, but AI has taken over.
- Digitalization has failed to deliver on its central promise! Why?
 Doug Macdonald wrote about the shortcomings of Legacy PLM, which most companies imagine/practice:
Doug Macdonald wrote about the shortcomings of Legacy PLM, which most companies imagine/practice:
- The shortcomings of Legacy PLM
- Could you manage the development of a toothbrush in a Legacy PLM system
I agree with much of this critique, for sure, if you still consider PLM a system rather than a product lifecycle management strategy implemented through a federated infrastructure of systems.
 The posts I referred to highlight real problems from the past and suggest that new insights and AI might help us build better businesses. The question is whether that promise will be fulfilled.
The posts I referred to highlight real problems from the past and suggest that new insights and AI might help us build better businesses. The question is whether that promise will be fulfilled.
Creating the human thread
 AI could help businesses break through organizational silos by pulling together information across functions.
AI could help businesses break through organizational silos by pulling together information across functions.
That would make concepts such as the digital thread and digital twin easier to implement without relying on dedicated interfaces.
This shift creates both opportunity and risk.
If AI reduces the need for siloed optimization, traditional middle-management roles will change. The key question is whether companies are willing to rethink their structures or stay constrained by Conway’s Law.
It could also make many methodology debates less important.

Today, we as consultants often promote methodologies shaped by our own experience or vendor narratives. The long-running eBOM–mBOM debate is a good example. Across industries and platforms, the answer is often more straightforward than the discussion suggests.
As AI absorbs more collective knowledge, the role of PLM experts and consultants will shift. At the Share PLM Summit in Jerez, we discussed what should come next: a stronger focus on human connection.
 That is why I use the term human thread: the network of relationships that connects people across the business. Michael Finochario (Fino) touches on the same shift in his post on the changing balance between humans and technology, in his review of my session in Jerez.
That is why I use the term human thread: the network of relationships that connects people across the business. Michael Finochario (Fino) touches on the same shift in his post on the changing balance between humans and technology, in his review of my session in Jerez.
Others are moving in the same direction. This week, Helene Älander shared a post that makes a similar point.
Helene’s post and the related discussion suggest a growing belief that transformation depends less on technology alone and more on human connection and motivation inside the company.
A quote from Helene’s post, and I recommend reading the full post and thread.
One lesson has stayed with me ever since:
Transformation rarely fails because of technology. It slows down when the distance between executive ambition and middle-management reality becomes too large.
For now, I call this the need for the human thread. A successful transformation starts with an end-to-end human connection across the business, with people treating that connection as a shared priority.
Because people are intrinsically motivated by a human connection.
![]() The human thread requires a new approach, new forms of workshops and learning sessions where leaders, managers, and employees work together on the desired business flow.
The human thread requires a new approach, new forms of workshops and learning sessions where leaders, managers, and employees work together on the desired business flow.
Helene Älander points in this direction, and Share PLM supports it through initiatives such as Share The Nest.
Also this year at the Share PLM Summit in Jerez, Andreas Wank described how Pepperl+Fuchs made a breakthrough by bringing people together. As Fino in his review post quoted:
No one on the team wanted to make a decision because every decision affected someone else. So they put 30 people in one room for a week and forced them to make decisions. Not perfect decisions. Working hypotheses. That was a critical insight: In PLM, waiting for perfect certainty kills momentum.
The year before, at the 2025 Share PLM Summit, Andrea Järvrén already shared a similar lesson, describing how Tetra Pak used design sprints to advance its PLM work by prioritizing human interaction.
It is an unstoppable trend – the human thread popping up in more and more conversations.
Conclusion
The time for blaming systems, technology, and methodology should fade into the background. Companies need to focus on building business flow through the human thread—the human connections that drive commitment, motivation, and change.
So, here is the question: Are we ready to stop blaming systems and start building the human thread? Or will we keep repeating the same patterns, just with fancier technology?


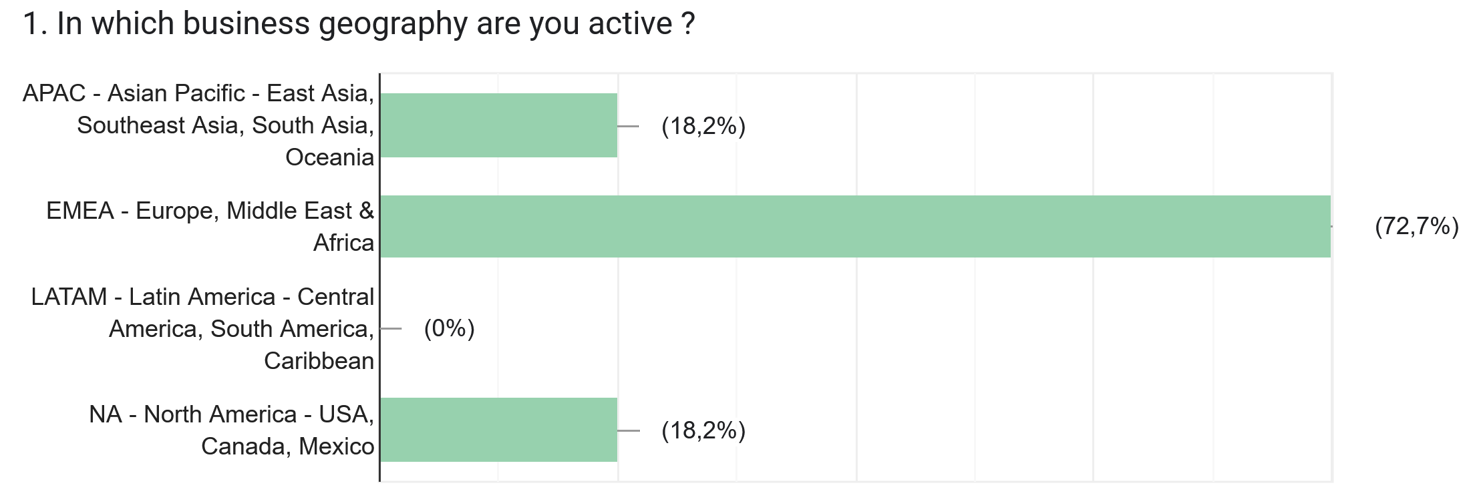
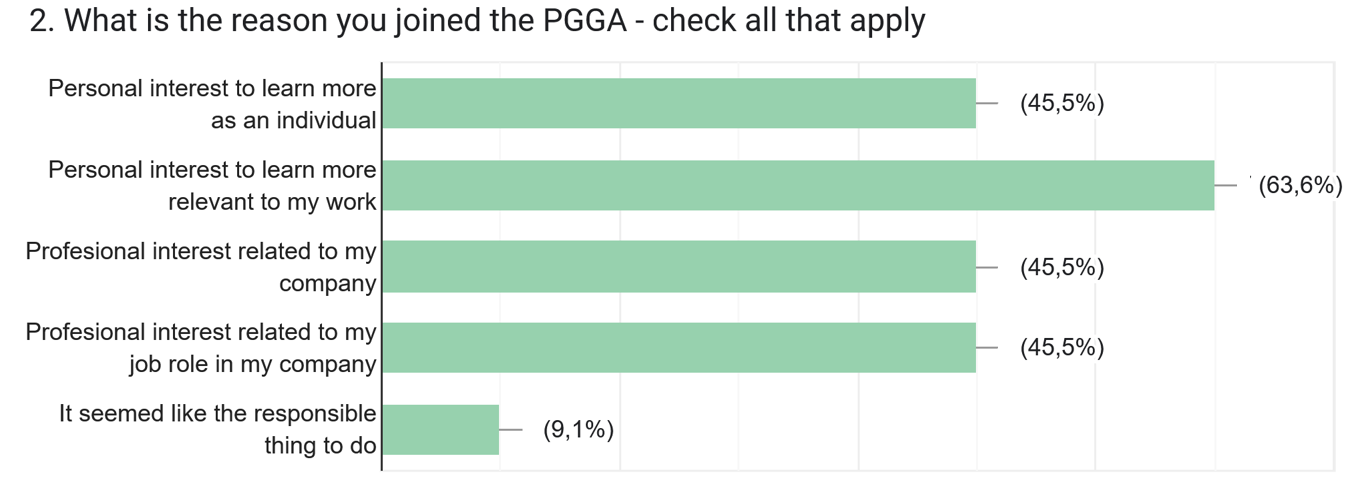
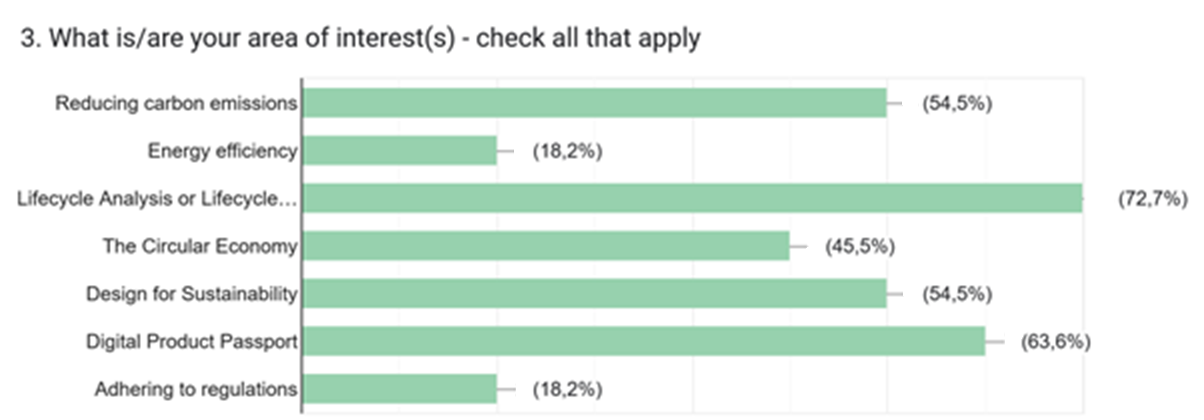
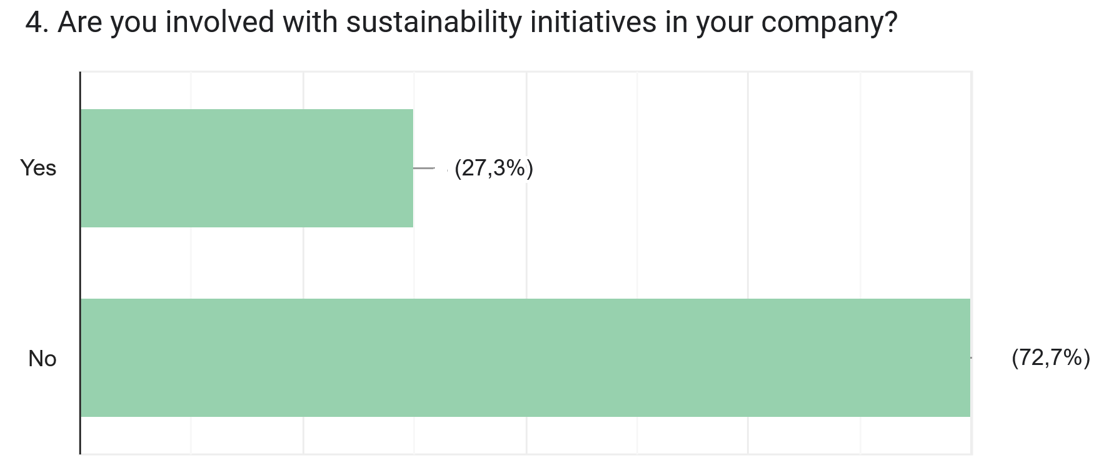
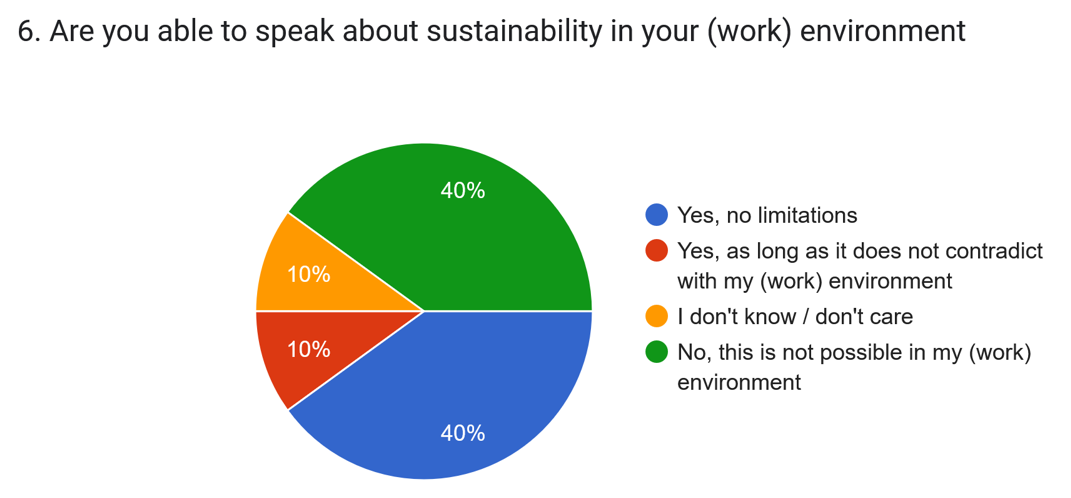
 Despite political headwinds, businesses have been implementing more sustainability initiatives, and we were curious to hear from PLM vendors and implementers about what they are currently observing and offering to the field.
Despite political headwinds, businesses have been implementing more sustainability initiatives, and we were curious to hear from PLM vendors and implementers about what they are currently observing and offering to the field.






 Let me start with a confession: as a kid, I was a classic nerd, drawn to soccer and exact sciences. Math and physics weren’t just subjects—they were my playground.
Let me start with a confession: as a kid, I was a classic nerd, drawn to soccer and exact sciences. Math and physics weren’t just subjects—they were my playground. The upside of this experience? Technical and physical concepts never intimidated me – they helped me to see the bigger picture. I was wired to think deeply, patiently, and persistently—skills that have stayed with me ever since.
The upside of this experience? Technical and physical concepts never intimidated me – they helped me to see the bigger picture. I was wired to think deeply, patiently, and persistently—skills that have stayed with me ever since.

 Organizational Change Management is often considered too soft to address, particularly in so-called result-driven organizations. Shut up and do the work!
Organizational Change Management is often considered too soft to address, particularly in so-called result-driven organizations. Shut up and do the work! I believe, with the experience as a PLM coach, that every PLM implementation should be a people and business discussion first – preferably sponsored at C-level – before jumping on the solutions.
I believe, with the experience as a PLM coach, that every PLM implementation should be a people and business discussion first – preferably sponsored at C-level – before jumping on the solutions.
 Is the “product memory” based on an agentic AI layer and an underlying ontology, the next big thing after the connected digital enterprise? Initially formulated by
Is the “product memory” based on an agentic AI layer and an underlying ontology, the next big thing after the connected digital enterprise? Initially formulated by 
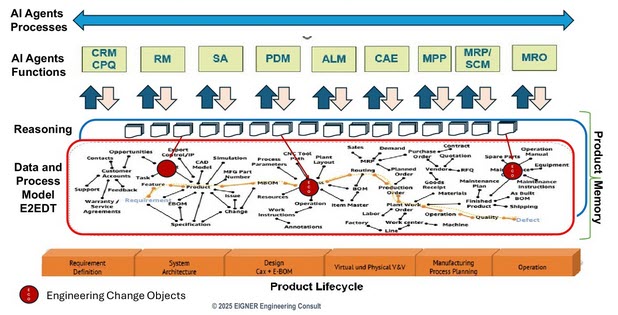
 In the techie world, there was always a hypothetical response for this question, but will it happen in a product memory environment where not everything is 100 percent exact and correct?
In the techie world, there was always a hypothetical response for this question, but will it happen in a product memory environment where not everything is 100 percent exact and correct?  Now compare this with the human brain; when a serious accident happens, the person involved might have trauma from that. Then you need a psychiatrist to fix the trauma, meaning create other memory constructs – rewiring the brain.
Now compare this with the human brain; when a serious accident happens, the person involved might have trauma from that. Then you need a psychiatrist to fix the trauma, meaning create other memory constructs – rewiring the brain.
 Last week I listened to a Dutch podcast that gave me an unexpected inspiration. The podcast
Last week I listened to a Dutch podcast that gave me an unexpected inspiration. The podcast 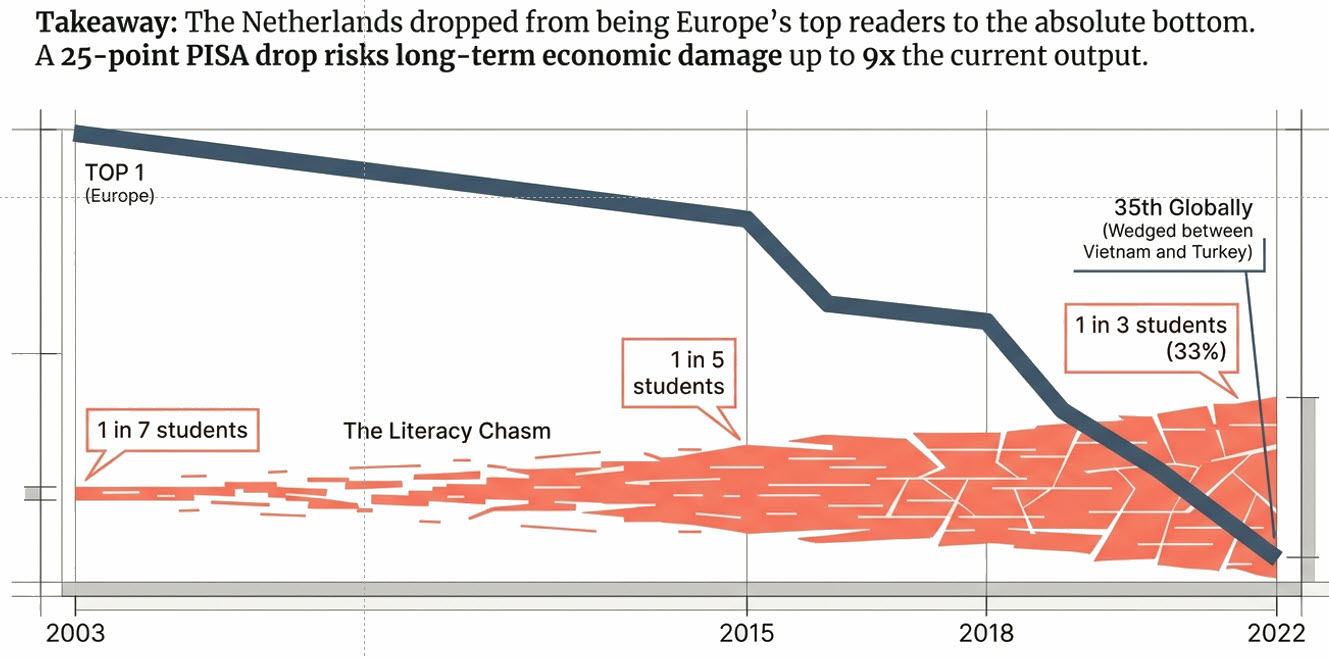



 I believe our brain is a muscle. Like any muscle, it needs resistance to stay strong. You do not become a better cyclist by riding an eBike everywhere — the motor does the work, and your legs lose the real strength needed when you are without your bike. The same applies to cognitive effort.
I believe our brain is a muscle. Like any muscle, it needs resistance to stay strong. You do not become a better cyclist by riding an eBike everywhere — the motor does the work, and your legs lose the real strength needed when you are without your bike. The same applies to cognitive effort. It is not the first time a transformative technology arrived with enormous promise and created a deeply unequal outcome. The Industrial Revolution reduced most workers to resources while a few became extraordinarily wealthy.
It is not the first time a transformative technology arrived with enormous promise and created a deeply unequal outcome. The Industrial Revolution reduced most workers to resources while a few became extraordinarily wealthy.
 The PLM vendors benefited from selling the dream, the consultants benefited from its complexity and the users, initially engineers and later more stakeholders in the product lifecycle, often suffered under rigid processes and complex systems. As the systems were designed to store information. User-friendlyness was not a priority.
The PLM vendors benefited from selling the dream, the consultants benefited from its complexity and the users, initially engineers and later more stakeholders in the product lifecycle, often suffered under rigid processes and complex systems. As the systems were designed to store information. User-friendlyness was not a priority.
 There is an interesting discussion ongoing about the future of PLM infrastructures, well described recently by
There is an interesting discussion ongoing about the future of PLM infrastructures, well described recently by 
 As individuals, we need to keep on training our brain-muscles without AI where the muscle matters. As the Dutch podcast mentioned: write your first draft before asking Claude to improve it, think through a problem before asking ChatGPT to solve it, and read a book of 100 pages.
As individuals, we need to keep on training our brain-muscles without AI where the muscle matters. As the Dutch podcast mentioned: write your first draft before asking Claude to improve it, think through a problem before asking ChatGPT to solve it, and read a book of 100 pages.



 Within the PGGA, everyone is welcome to share their perspective — with respect for those who see it differently. It’s not about being right or wrong. It’s about the dialogue, and about finding paths forward to a future that’s sustainable not just for the planet, but for businesses and the people within them.
Within the PGGA, everyone is welcome to share their perspective — with respect for those who see it differently. It’s not about being right or wrong. It’s about the dialogue, and about finding paths forward to a future that’s sustainable not just for the planet, but for businesses and the people within them.

 ERP always had a strong voice at the management level—boxes on an org chart, reporting lines, clear ownership and KPIs flowing upward. You could see how the company was performing.
ERP always had a strong voice at the management level—boxes on an org chart, reporting lines, clear ownership and KPIs flowing upward. You could see how the company was performing. In many of my engagements, the company’s management often struggles to understand the value of collaboration because there is no direct line between collaboration and immediate performance. Revenue can be measured. Cycle times can be measured. Defects can be measured. Even employee turnover can be measured.
In many of my engagements, the company’s management often struggles to understand the value of collaboration because there is no direct line between collaboration and immediate performance. Revenue can be measured. Cycle times can be measured. Defects can be measured. Even employee turnover can be measured. The problem is not that collaboration has no impact on performance – look at the introduction of email in companies. Did your company make a business case for that?
The problem is not that collaboration has no impact on performance – look at the introduction of email in companies. Did your company make a business case for that? The return on investment on collaboration is real, but it does not show up as a clean, linear metric.
The return on investment on collaboration is real, but it does not show up as a clean, linear metric.
 “We need better platforms.”
“We need better platforms.”
 For companies, it is easier to celebrate the hero who fixes a late-stage integration disaster than the quiet team that prevented it months earlier through cross-functional dialogue.
For companies, it is easier to celebrate the hero who fixes a late-stage integration disaster than the quiet team that prevented it months earlier through cross-functional dialogue. Note: shared experiences are not the same as planned online webmeetings that became popular during and after COVID. They have a rigid regime of collaboration enforcement, back-to-back in many companies, most of the time lacking the typical “coffee machine” experiences.
Note: shared experiences are not the same as planned online webmeetings that became popular during and after COVID. They have a rigid regime of collaboration enforcement, back-to-back in many companies, most of the time lacking the typical “coffee machine” experiences. The question is not whether collaboration is valuable. The question is whether we are willing to adjust our vertical incentives to make it possible.
The question is not whether collaboration is valuable. The question is whether we are willing to adjust our vertical incentives to make it possible.


 I enjoyed my role as the “Flying Dutchman,” travelling around the world to support PLM implementations and discussions. Flying was simply part of the job. Real communication meant being in the same room; early phone and video calls were expensive, awkward, and often ineffective. PLM was — and still is — a human business.
I enjoyed my role as the “Flying Dutchman,” travelling around the world to support PLM implementations and discussions. Flying was simply part of the job. Real communication meant being in the same room; early phone and video calls were expensive, awkward, and often ineffective. PLM was — and still is — a human business.





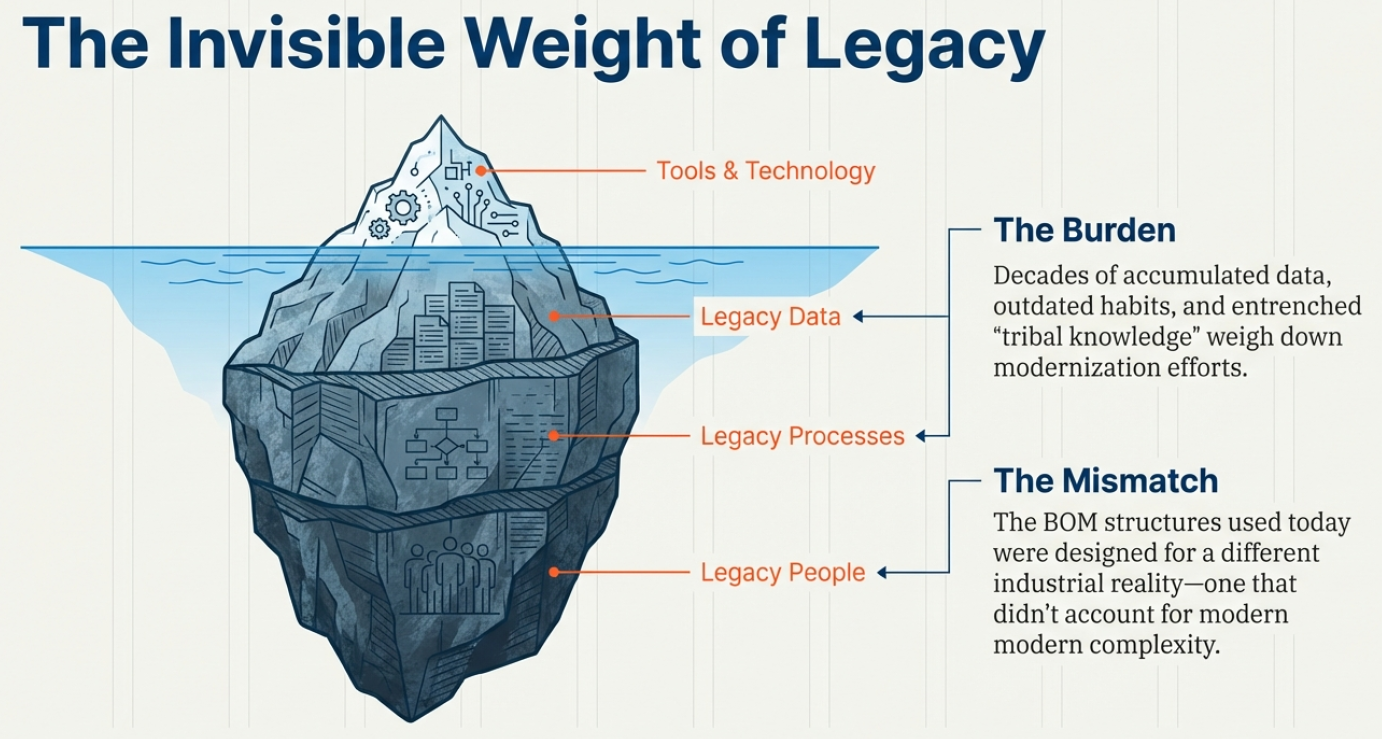
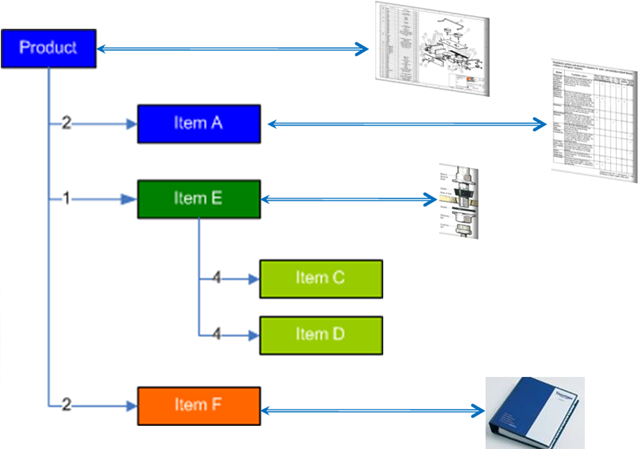

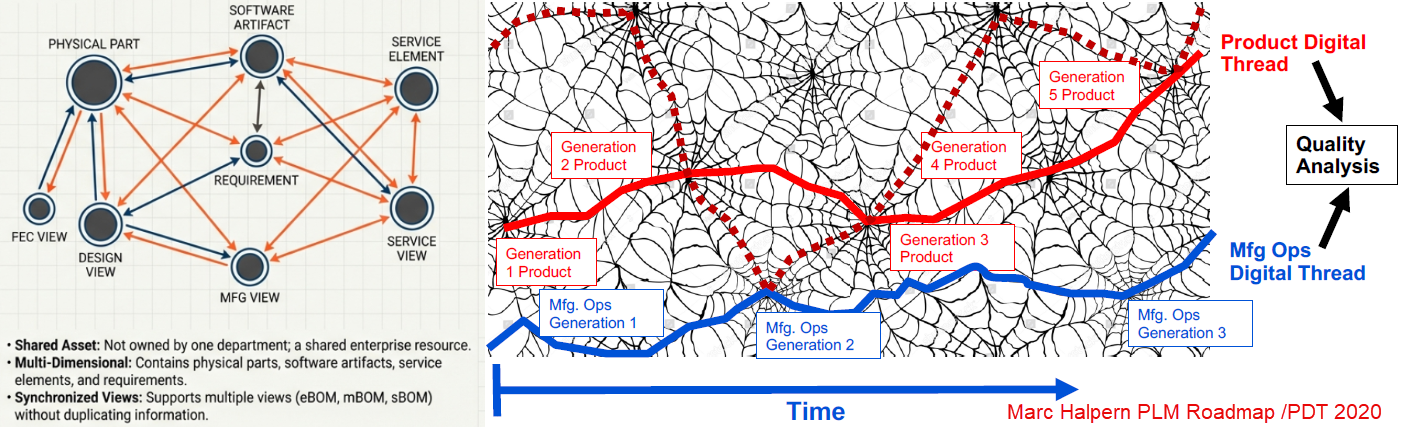
 This definition needs to be resolved and adapted for a specific plant with its local suppliers and resources. PLM systems often support the transformation from the eBOM to a proposed mBOM, and if done more completely with a Bill of Process.
This definition needs to be resolved and adapted for a specific plant with its local suppliers and resources. PLM systems often support the transformation from the eBOM to a proposed mBOM, and if done more completely with a Bill of Process.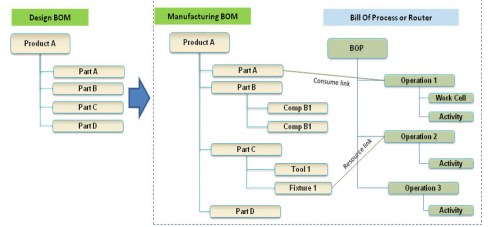
 The challenge for these companies is that there is a lot of guesswork to be done, as the service business was not planned in their legacy business. A quick and dirty solution was to use the mBOM in ERP as the source of information. However, the ERP system usually does not provide any context information, such as where the part is located and what potential other parts need to be replaced—a challenging job for service engineers.
The challenge for these companies is that there is a lot of guesswork to be done, as the service business was not planned in their legacy business. A quick and dirty solution was to use the mBOM in ERP as the source of information. However, the ERP system usually does not provide any context information, such as where the part is located and what potential other parts need to be replaced—a challenging job for service engineers.



Hi Jos, Knowing your background in methodology and education, I wanted to share a longer article with you: “What is…
Interesting reflection, Jos. In my experience, the situation you describe is very recognizable. At the company where I work, sustainability…
[…] (The following post from PLM Green Global Alliance cofounder Jos Voskuil first appeared in his European PLM-focused blog HERE.) […]
[…] recent discussions in the PLM ecosystem, including PSC Transition Technologies (EcoPLM), CIMPA PLM services (LCA), and the Design for…
Jos, all interesting and relevant. There are additional elements to be mentioned and Ontologies seem to be one of the…