
 In my last post in this series, The road to model-based and connected PLM, I mentioned that perhaps it is time to talk about SLM instead of PLM when discussing popular TLA’s for our domain of expertise. There were not so many encouraging statements for SLM so far.
In my last post in this series, The road to model-based and connected PLM, I mentioned that perhaps it is time to talk about SLM instead of PLM when discussing popular TLA’s for our domain of expertise. There were not so many encouraging statements for SLM so far.
SLM could mean for me, Solution Lifecycle Management, considering that the company’s offering more and more is a mix of products and services. Or SLM could mean System Lifecycle Management, in that case pushing the idea that more and more products are interacting with the outside world and therefore could be considered systems. Products are (almost) dead.
In addition, I mentioned that the typical product lifecycle and related configuration management concepts need to change as in the SLM domain. There is hardware and software with different lifecycles and change processes.
 It is a topic I want to explore further. I am curious to learn more from Martijn Dullaart, who will be lecturing at the PLM Road map and PDT 2021 fall conference in November. I hope my expectations are not too high, knowing it is a topic of interest for Martijn. Feel free to join this discussion
It is a topic I want to explore further. I am curious to learn more from Martijn Dullaart, who will be lecturing at the PLM Road map and PDT 2021 fall conference in November. I hope my expectations are not too high, knowing it is a topic of interest for Martijn. Feel free to join this discussion
In this post, it is time to follow up on my third statement related to what data-driven implies:
Data-driven means that we need to manage data in a much more granular manner. We have to look different at data ownership. It becomes more about data accountability per role as the data can be used and consumed throughout the product lifecycle
On this topic, I have a list of points to consider; let’s go through them.
The dataset
In this post, I will often use the term dataset (you are also allowed to write the data set I understood).
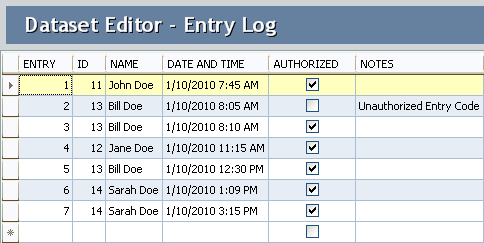 A dataset means a predefined number of attributes and values that belong logically to each other. Datasets should be defined based on the purpose and, if possible, designated for a single goal. In this way, they can be stored in a database.
A dataset means a predefined number of attributes and values that belong logically to each other. Datasets should be defined based on the purpose and, if possible, designated for a single goal. In this way, they can be stored in a database.
Combined with other datasets, a combination can result in relevant business information. Note a dataset is not only transactional data; a dataset could also describe geometry.
Identify the dataset
 In the document-based world, a lot of information could be stored in a single file. In a data-driven world, we should define a dataset that contains a specific piece of information, logically belonging together. If we are more precise, a part would have various related datasets that make up the definition of a part. These definitions could be:
In the document-based world, a lot of information could be stored in a single file. In a data-driven world, we should define a dataset that contains a specific piece of information, logically belonging together. If we are more precise, a part would have various related datasets that make up the definition of a part. These definitions could be:
- Core identification attributes like ID, Name, Type and Status
- The Type could define a set of linked information. For example, a valve would have different characteristics as a resistor. Through classification, we can link data sets to the core definition of a part.
- The part can have engineering-specific data (CAD and metadata), manufacturing-specific data, supplier-specific data, and service-specific data. Each of these datasets needs to be defined as a unique element in a data-driven environment
- CAD is a particular case as most current CAD systems don’t treat geometry as a single dataset. In a file-based world, many other datasets are stored in the file (e.g., engineering or manufacturing details). In a data-driven environment, we want to have the CAD definition to be treated like a dataset. Dassault Systèmes with their CATIA V6 and 3DEXPERIENCE platform or PTC with OnShape are examples of this approach.Having CAD as separate datasets makes sharing and collaboration so much easier, as we can see from these solutions. The concept for CAD stored in a database is not new, and this approach has been used in various disciplines. Mechanical CAD was always a challenge.
![]() Thanks to Moore’s Law (approximate every 2 years, processor power doubled – click on the image for the details) and higher network connection speed, it starts to make sense to have mechanical CAD also stored in a database instead of a file
Thanks to Moore’s Law (approximate every 2 years, processor power doubled – click on the image for the details) and higher network connection speed, it starts to make sense to have mechanical CAD also stored in a database instead of a file
An important point to consider is a kind of standardization of datasets. In theory, there should be a kind of minimum agreed collection of datasets. Industry standards provide these collections in their dictionary. Whenever you optimize your data model for a connected enterprise, make sure you look first into the standards that apply to your industry.
 They might not be perfect or complete, but inventing your own new standard is a guarantee for legacy issues in the future. This remark is also valid for the software vendors in this domain. A proprietary data model might give you a competitive advantage.
They might not be perfect or complete, but inventing your own new standard is a guarantee for legacy issues in the future. This remark is also valid for the software vendors in this domain. A proprietary data model might give you a competitive advantage.
Still, in the long term, there is always the need to connect with outside stakeholders.
Identify the RACI
To ensure a dataset is complete and well maintained, the concept of RACI could be used. RACI is the abbreviation for Responsible Accountable Consulted and Informed and a simplification of the RASCI Model, see also a responsibility assignment matrix.
 In a data-driven environment, there is no data ownership anymore like you have for documents. The main reason that data ownership can no longer be used is that datasets can be consumed by anyone in the ecosystem. No longer only your department or the manufacturing or service department.
In a data-driven environment, there is no data ownership anymore like you have for documents. The main reason that data ownership can no longer be used is that datasets can be consumed by anyone in the ecosystem. No longer only your department or the manufacturing or service department.
Data sets in a data-driven environment bring value when connected with other datasets in applications or dashboards.
A dataset describing the specification attributes of a part could be used in a spare part app and a service app. Of course, the dataset will be used in a different context – still, we need to ensure we can trust the data.
Therefore, per identified dataset, there should be governed by a kind of RACI concept. The RACI concept is a way to break the siloes in an organization.
Identify Inside / outside
There is a lot of fear that a connected, data-driven environment will expose Intellectual Property (IP). It came up in recent discussions. If you like storytelling and technology, read my old SmarTeam colleague Alex Bruskin’s post: The Bilbo Baggins Threat to PLM Assets. Alex has written some “poetry” with a deep technical message behind it.
 It is true that if your data set is too big, you have the challenge of exposing IP when connecting this dataset with others. Therefore, when building a data model, you should make it possible to have datasets pure for internal usage and datasets for sharing.
It is true that if your data set is too big, you have the challenge of exposing IP when connecting this dataset with others. Therefore, when building a data model, you should make it possible to have datasets pure for internal usage and datasets for sharing.
When you use the concept of RACI, the difference should be defined by the I(informed) – is it PLM-data or PIM-data for example?
Tracking relations
Suppose we follow up on the concept of datasets. In that case, it becomes clear that relations between the datasets are as crucial as the dataset. In traditional PLM applications, these relations are often predefined as part of the core data model/
 For example, the EBOM parts have relationships between themselves and specification data – see image.
For example, the EBOM parts have relationships between themselves and specification data – see image.
The MBOM parts have links with the supplier data or the manufacturing process.
The prepared relations in a PLM system allow people to implement the system relatively quickly to map their approaches to this taxonomy.
 However, traditional PLM systems are based on a document-based (or file-based) taxonomy combined with related metadata. In a model-based and connected environment, we have to get rid of the document-based type of data.
However, traditional PLM systems are based on a document-based (or file-based) taxonomy combined with related metadata. In a model-based and connected environment, we have to get rid of the document-based type of data.
Therefore, the datasets will be more granular, and there is a need to manage exponential more relations between datasets.
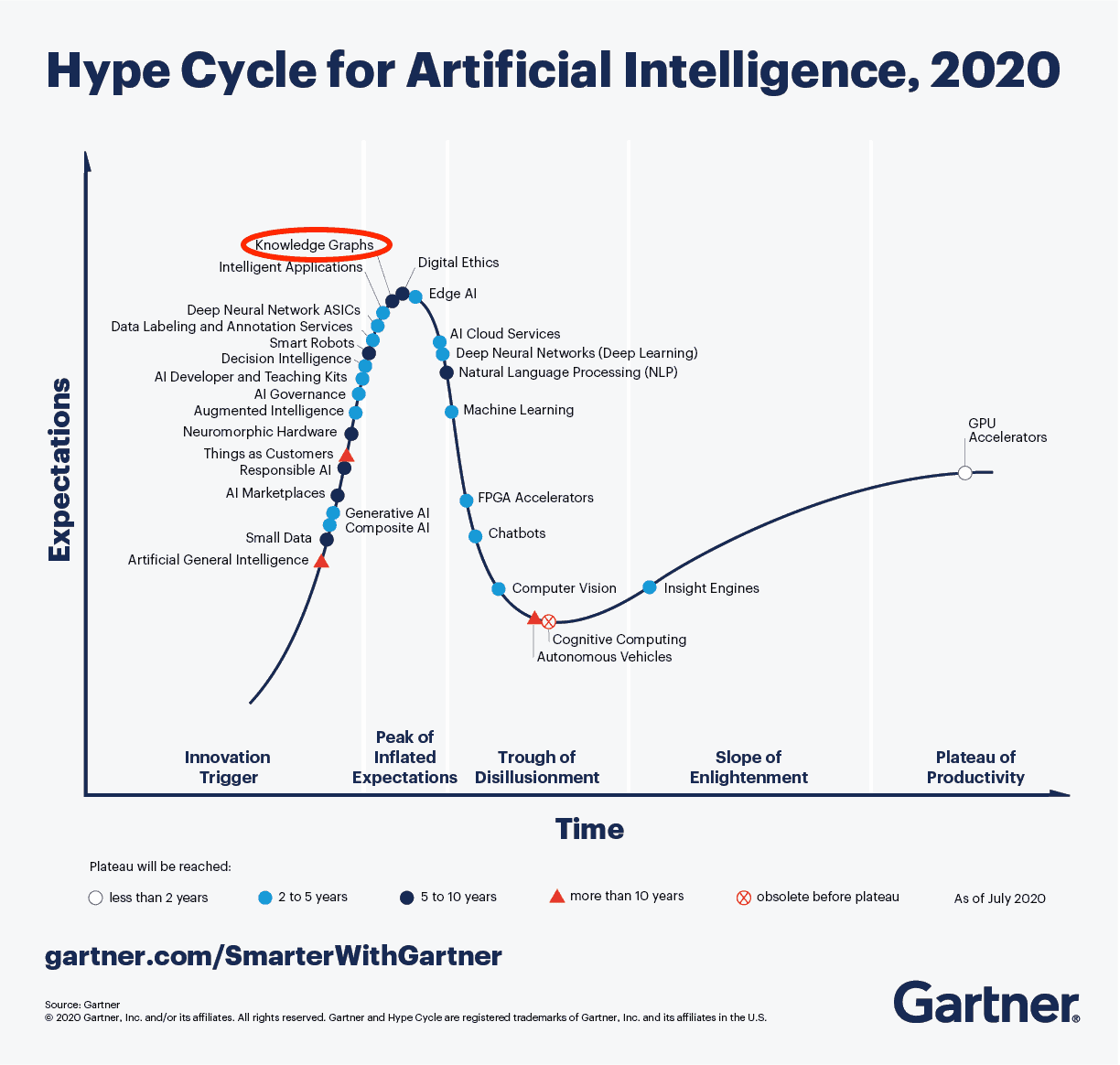 This is why you see the graph database coming up as a needed infrastructure for modern connected applications. If you haven’t heard of a graph database yet, you are probably far from technology hypes. To understand the principles of a graph database you can read this article from neo4j: Graph Databases for Beginners: Why graph technology is the future
This is why you see the graph database coming up as a needed infrastructure for modern connected applications. If you haven’t heard of a graph database yet, you are probably far from technology hypes. To understand the principles of a graph database you can read this article from neo4j: Graph Databases for Beginners: Why graph technology is the future
As you can see from the 2020 Gartner Hype Cycle for Artificial Intelligence this technology is at the top of the hype and conceptually the way to manage a connected enterprise. The discussion in this post also demonstrates that besides technology there is a lot of additional conceptual thinking needed before it can be implemented.
Although software vendors might handle the relations and datasets within their platform, the ultimate challenge will be sharing datasets with other platforms to get a connected ecosystem.
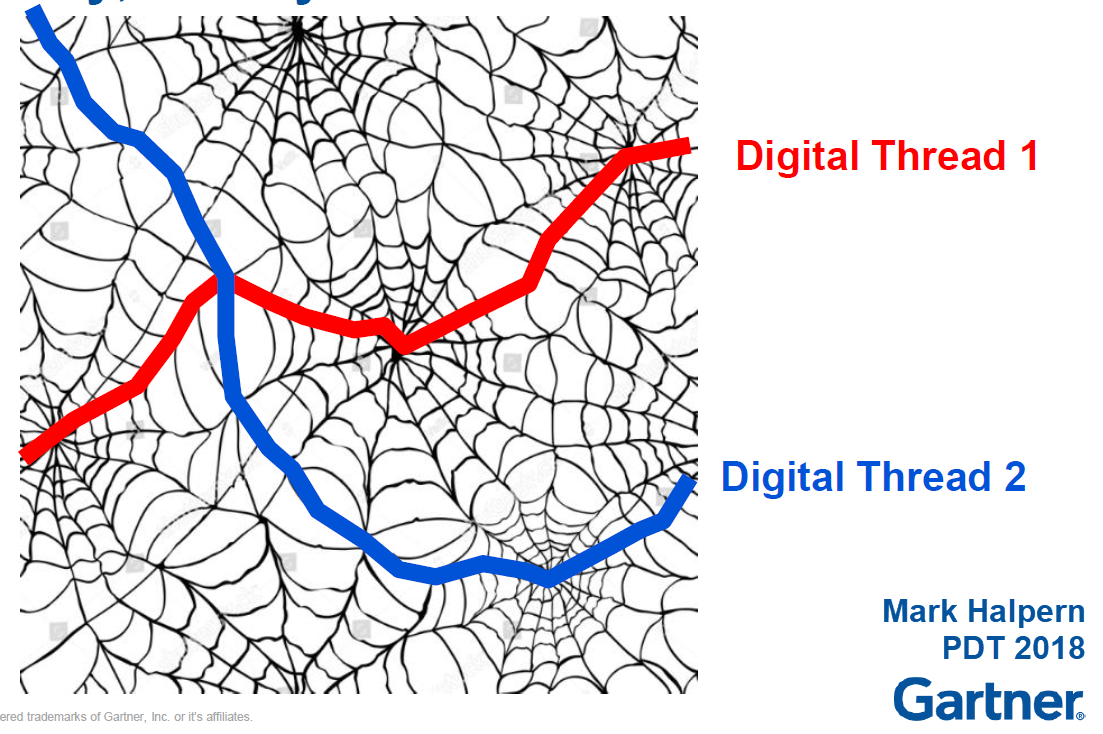
For example, the digital web picture shown above and introduced by Marc Halpern at the 2018 PDT conference shows this concept. Recently CIMdata discussed this topic in a similar manner: The Digital Thread is Really a Web, with the Engineering Bill of Materials at Its Center
(Note I am not sure if CIMdata has published a recording of this webinar – if so I will update the link)
Anyway, these are signs that we started to find the right visuals to imagine new concepts. The traditional digital thread pictures, like the one below, are, for me, impressions of the past as they are too rigid and focusing on some particular value streams.
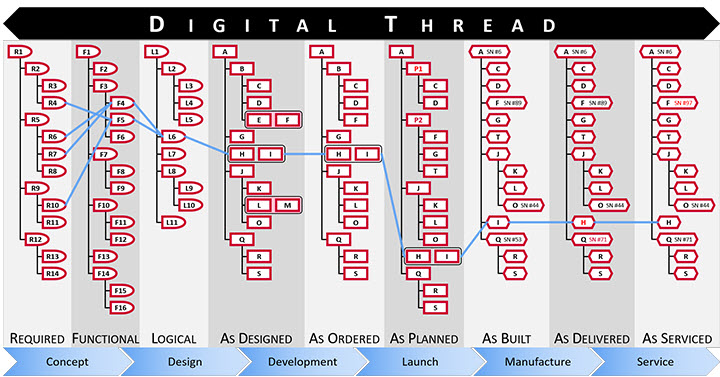
From a distance, it looks like a connected enterprise should work like our brain. We story information on different abstraction levels. We keep incredibly many relations between information elements. As the brain is a biological organ, connections degrade or get lost. Or the opposite other relationships become so strong that we cannot change them anymore. (“I know I am always right”)
 Interestingly, the brain does not use the “single source of truth”-concept – there can be various “truths” inside a brain. This makes us human beings with all the good and the harmful effects of that.
Interestingly, the brain does not use the “single source of truth”-concept – there can be various “truths” inside a brain. This makes us human beings with all the good and the harmful effects of that.
As long as we realize there is no single source of truth.
In business and our technological world, we need sometimes the undisputed truth. Blockchain could be the basis for securing the right connections between datasets to guarantee the result is valid. I am curious if blockchain can scale to complex connected situations, although Moore’s Law might ultimately help us here too(if still valid).
 The topic is not new – in 2014 I wrote a post with the title: PLM is doomed unless …. Where I introduced the topic of owning and sharing in the context of the human brain. In the post, I refer to the book On Intelligence by Jeff Hawkins how tries to analyze what is human-based intelligence and how could we apply it to our technology concepts. Still a fascinating book worth reading if you have the time and opportunity.
The topic is not new – in 2014 I wrote a post with the title: PLM is doomed unless …. Where I introduced the topic of owning and sharing in the context of the human brain. In the post, I refer to the book On Intelligence by Jeff Hawkins how tries to analyze what is human-based intelligence and how could we apply it to our technology concepts. Still a fascinating book worth reading if you have the time and opportunity.
Conclusion
A data-driven approach requires a more granular definition of information, leading to the concepts of datasets and managing relations between datasets. This is a fundamental difference compared to the past, where we were operating systems with information. Now we are heading towards connected platforms that provide a filtered set of real-time data to act upon.
I am curious to learn more about how people have solved the connected challenges and in what kind of granularity. Let us know!
Discover more from Jos Voskuil's Weblog
Subscribe to get the latest posts sent to your email.

Leave a comment
Comments feed for this article