
You are currently browsing the tag archive for the ‘Data Model’ tag.
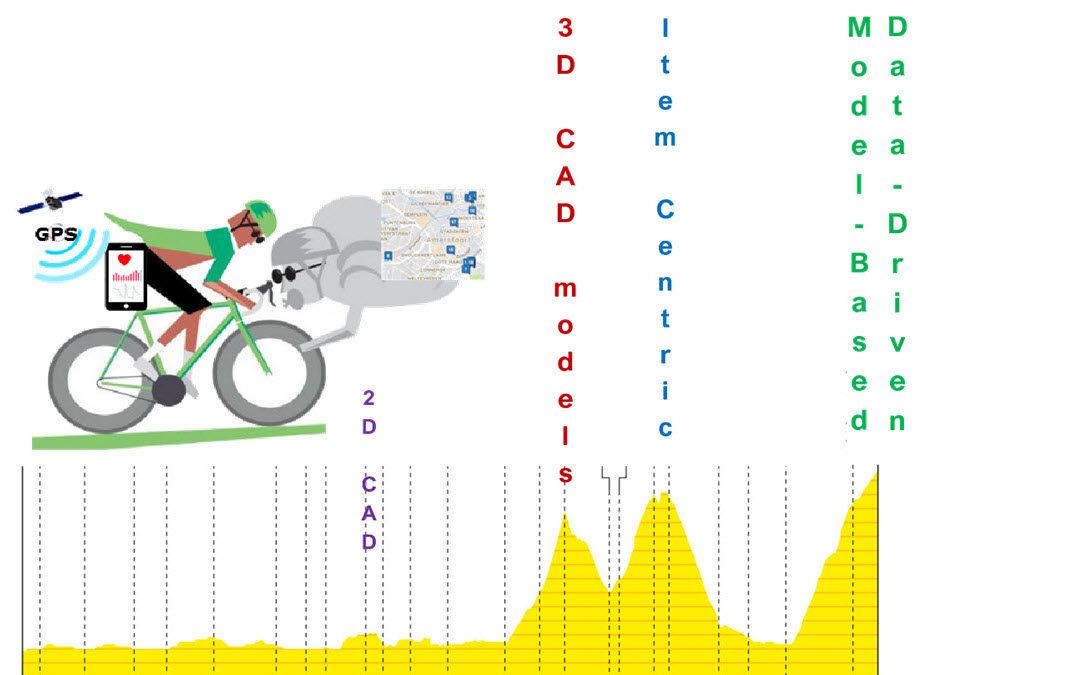 So far, I have been discussing PLM experiences and best practices that have changed due to introducing electronic drawings and affordable 3D CAD systems for the mainstream. From vellum to PDM to item-centric PLM to manage product designs and manufacturing specifications.
So far, I have been discussing PLM experiences and best practices that have changed due to introducing electronic drawings and affordable 3D CAD systems for the mainstream. From vellum to PDM to item-centric PLM to manage product designs and manufacturing specifications.
Although the technology has improved, the overall processes haven’t changed so much. As a result, disciplines could continue to work in their own comfort zone, most of the time hidden and disconnected from the outside world.
 Now, thanks to digitalization, we can connect and format information in real-time. Now we can provide every stakeholder in the company’s business to have almost real-time visibility on what is happening (if allowed). We have seen the benefits of platformization, where the benefits come from real-time connectivity within an ecosystem.
Now, thanks to digitalization, we can connect and format information in real-time. Now we can provide every stakeholder in the company’s business to have almost real-time visibility on what is happening (if allowed). We have seen the benefits of platformization, where the benefits come from real-time connectivity within an ecosystem.
Apple, Amazon, Uber, Airbnb are the non-manufacturing related examples. Companies are trying to replicate these models for other businesses, connecting the concept owner (OEM ?), with design and manufacturing (services), with suppliers and customers. All connected through information, managed in data elements instead of documents – I call it connected PLM
 Vendors have already shared their PowerPoints, movies, and demos from how the future would be in the ideal world using their software. The reality, however, is that implementing such solutions requires new business models, a new type of organization and probably new skills.
Vendors have already shared their PowerPoints, movies, and demos from how the future would be in the ideal world using their software. The reality, however, is that implementing such solutions requires new business models, a new type of organization and probably new skills.
The last point is vital, as in schools and organizations, we tend to teach what we know from the past as this gives some (fake) feeling of security.
 The reality is that most of us will have to go through a learning path, where skills from the past might become obsolete; however, knowledge of the past might be fundamental.
The reality is that most of us will have to go through a learning path, where skills from the past might become obsolete; however, knowledge of the past might be fundamental.
In the upcoming posts, I will share with you what I see, what I deduct from that and what I think would be the next step to learn.
I firmly believe connected PLM requires the usage of various models. Not only the 3D CAD model, as there are so many other models needed to describe and analyze the behavior of a product.
 I hope that some of my readers can help us all further on the path of connected PLM (with a model-based approach). This series of posts will be based on the max size per post (avg 1500 words) and the ideas and contributes coming from you and me.
I hope that some of my readers can help us all further on the path of connected PLM (with a model-based approach). This series of posts will be based on the max size per post (avg 1500 words) and the ideas and contributes coming from you and me.
What is platformization?
In our day-to-day life, we are more and more used to direct interaction between resellers and services providers on one side and consumers on the other side. We have a question, and within 24 hours, there is an answer. We want to purchase something, and potentially the next day the goods are delivered. These are examples of a society where all stakeholders are connected in a data-driven manner.
 We don’t have to create documents or specialized forms. An app or a digital interface allows us to connect. To enable this type of connectivity, there is a need for an underlying platform that connects all stakeholders. Amazon and Salesforce are examples for commercial activities, Facebook for social activities and, in theory, LinkedIn for professional job activities.
We don’t have to create documents or specialized forms. An app or a digital interface allows us to connect. To enable this type of connectivity, there is a need for an underlying platform that connects all stakeholders. Amazon and Salesforce are examples for commercial activities, Facebook for social activities and, in theory, LinkedIn for professional job activities.
The platform is responsible for direct communication between all stakeholders.
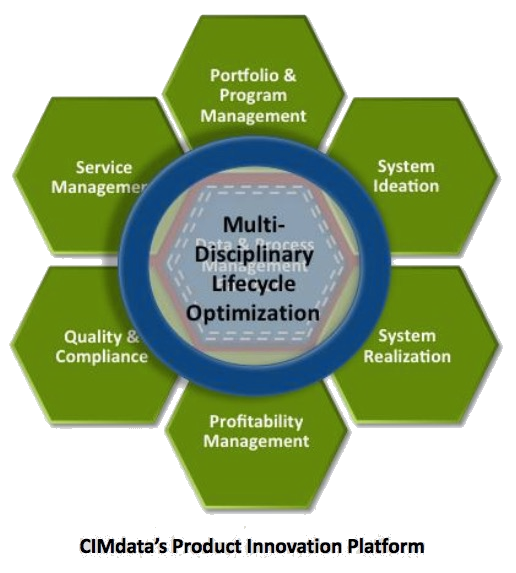
The same applies to businesses. Depending on the products or services they deliver, they could benefit from one or more platforms. The image below shows five potential platforms that I identified in my customer engagements. Of course, they have a PLM focus (in the middle), and the grouping can be made differently.

Five potential business platforms
The 5 potential platforms
The ERP platform
 is mainly dedicated to the company’s execution processes – Human Resources, Purchasing, Finance, Production scheduling, and potentially many more services. As platforms try to connect as much as possible all stakeholders. The ERP platform might contain CRM capabilities, which might be sufficient for several companies. However, when the CRM activities become more advanced, it would be better to connect the ERP platform to a CRM platform. The same logic is valid for a Product Innovation Platform and an ERP platform. Examples of ERP platforms are SAP and Oracle (and they will claim they are more than ERP)
is mainly dedicated to the company’s execution processes – Human Resources, Purchasing, Finance, Production scheduling, and potentially many more services. As platforms try to connect as much as possible all stakeholders. The ERP platform might contain CRM capabilities, which might be sufficient for several companies. However, when the CRM activities become more advanced, it would be better to connect the ERP platform to a CRM platform. The same logic is valid for a Product Innovation Platform and an ERP platform. Examples of ERP platforms are SAP and Oracle (and they will claim they are more than ERP)
Note: Historically, most companies started with an ERP system, which is not the same as an ERP platform. A platform is scalable; you can add more apps without having to install a new system. In a platform, all stored data is connected and has a shared data model.
The CRM platform
 a platform that is mainly focusing on customer-related activities, and as you can see from the diagram, there is an overlap with capabilities from the other platforms. So again, depending on your core business and products, you might use these capabilities or connect to other platforms. Examples of CRM platforms are Salesforce and Pega, providing a platform to further extend capabilities related to core CRM.
a platform that is mainly focusing on customer-related activities, and as you can see from the diagram, there is an overlap with capabilities from the other platforms. So again, depending on your core business and products, you might use these capabilities or connect to other platforms. Examples of CRM platforms are Salesforce and Pega, providing a platform to further extend capabilities related to core CRM.
The MES platform
 In the past, we had PDM and ERP and what happened in detail on the shop floor was a black box for these systems. MES platforms have become more and more important as companies need to trace and guide individual production orders in a data-driven manner. Manufacturing Execution Systems (and platforms) have their own data model. However, they require input from other platforms and will provide specific information to other platforms.
In the past, we had PDM and ERP and what happened in detail on the shop floor was a black box for these systems. MES platforms have become more and more important as companies need to trace and guide individual production orders in a data-driven manner. Manufacturing Execution Systems (and platforms) have their own data model. However, they require input from other platforms and will provide specific information to other platforms.
For example, if we want to know the serial number of a product and the exact production details of this product (used parts, quality status), we would use an MES platform. Examples of MES platforms (none PLM/ERP related vendors) are Parsec and Critical Manufacturing
The IoT platform
 these platforms are new and are used to monitor and manage connected products. For example, if you want to trace the individual behavior of a product of a process, you need an IoT platform. The IoT platform provides the product user with performance insights and alerts.
these platforms are new and are used to monitor and manage connected products. For example, if you want to trace the individual behavior of a product of a process, you need an IoT platform. The IoT platform provides the product user with performance insights and alerts.
However, it also provides the product manufacturer with the same insights for all their products. This allows the manufacturer to offer predictive maintenance or optimization services based on the experience of a large number of similar products. Examples of IoT platforms (none PLM/ERP-related vendors) are Hitachi and Microsoft.
The Product Innovation Platform (PIP)
 All the above platforms would not have a reason to exist if there was not an environment where products were invented, developed, and managed. The Product Innovation Platform PIP – as described by CIMdata -is the place where Intellectual Property (IP) is created, where companies decide on their portfolio and more.
All the above platforms would not have a reason to exist if there was not an environment where products were invented, developed, and managed. The Product Innovation Platform PIP – as described by CIMdata -is the place where Intellectual Property (IP) is created, where companies decide on their portfolio and more.
The PIP contains the traditional PLM domain. It is also a logical place to manage product quality and technical portfolio decisions, like what kind of product platforms and modules a company will develop. Like all previous platforms, the PIP cannot exist without other platforms and requires connectivity with the other platforms is applicable.
Look below at the CIMdata definition of a Product Innovation Platform.
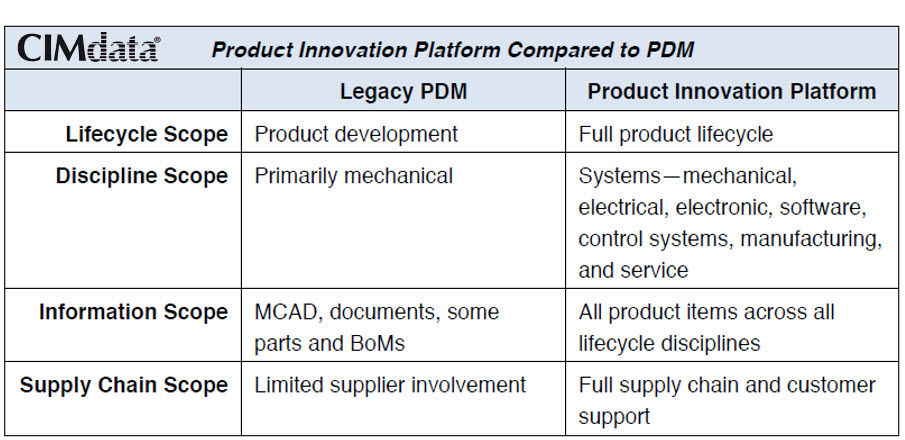
You will see that most of the historical PLM vendors aiming to be a PIP (with their different flavors): Aras, Dassault Systèmes, PTC and Siemens.
 Of course, several vendors sell more than one platform or even create the impression that everything is connected as a single platform. Usually, this is not the case, as each platform has its specific data model and combining them in a single platform would hurt the overall performance.
Of course, several vendors sell more than one platform or even create the impression that everything is connected as a single platform. Usually, this is not the case, as each platform has its specific data model and combining them in a single platform would hurt the overall performance.
Therefore, the interaction between these platforms will be based on standardized interfaces or ad-hoc connections.
Standard interfaces or ad-hoc connections?
Suppose your role and information needs can be satisfied within a single platform. In that case, most likely, the platform will provide you with the right environment to see and manipulate the information.
 However, it might be different if your role requires access to information from other platforms. For example, it could be as simple as an engineer analyzing a product change who needs to know the actual stock of materials to decide how and when to implement a change.
However, it might be different if your role requires access to information from other platforms. For example, it could be as simple as an engineer analyzing a product change who needs to know the actual stock of materials to decide how and when to implement a change.
This would be a PIP/ERP platform collaboration scenario.
 Or even more complex, it might be a product manager wanting to know how individual products behave in the field to decide on enhancements and new features. This could be a PIP, CRM, IoT and MES collaboration scenario if traceability of serial numbers is needed.
Or even more complex, it might be a product manager wanting to know how individual products behave in the field to decide on enhancements and new features. This could be a PIP, CRM, IoT and MES collaboration scenario if traceability of serial numbers is needed.
The company might decide to build a custom app or dashboard for this role to support such a role. Combining in real-time data from the relevant platforms, using standard interfaces (preferred) or using API’s, web services, REST services, microservices (for specialists) and currently in fashion Low-Code development platforms, which allow users to combine data services from different platforms without being an expert in coding.
 Without going too much in technology, the topics in this paragraph require an enterprise architecture and vision. It is opportunistic to think that your existing environment will evolve smoothly into a digital highway for the future by “fixing” demands per user. Your infrastructure is much more likely to end up congested as spaghetti.
Without going too much in technology, the topics in this paragraph require an enterprise architecture and vision. It is opportunistic to think that your existing environment will evolve smoothly into a digital highway for the future by “fixing” demands per user. Your infrastructure is much more likely to end up congested as spaghetti.
In that context, I read last week an interesting post Low code: A promising trend or Pandora’s box. Have a look and decide for yourself
I am less focused on technology, more on methodology. Therefore, I want to come back to the theme of my series: The road to model-based and connected PLM. For sure, in the ideal world, the platforms I mentioned, or other platforms that run across these five platforms, are cloud-based and open to connect to other data sources. So, this is the infrastructure discussion.
In my upcoming blog post, I will explain why platforms require a model-based approach and, therefore, cause a challenge, particularly in the PLM domain.
 It took us more than fifty years to get rid of vellum drawings. It took us more than twenty years to introduce 3D CAD for design and engineering. Still primarily relying on drawings. It will take us for sure one generation to switch from document-based engineering to model-based engineering.
It took us more than fifty years to get rid of vellum drawings. It took us more than twenty years to introduce 3D CAD for design and engineering. Still primarily relying on drawings. It will take us for sure one generation to switch from document-based engineering to model-based engineering.
Conclusion
In this post, I tried to paint a picture of the ideal future based on connected platforms. Such an environment is needed if we want to be highly efficient in designing, delivering, and maintaining future complex products based on hardware and software. Concepts like Digital Twin and Industry 4.0 require a model-based foundation.
In addition, we will need Digital Twins to reach our future sustainability goals efficiently. So, there is work to do.
Your opinion, Your contribution?
I believe we are almost at the end of learning from the past. We have seen how, from an initial serial CAD-driven approach with PDM, we evolved to PLM-managed structures, the EBOM and the MBOM. Or to illustrate this statement, look at the image below, where I use a Tech-Clarity image from Jim Brown.
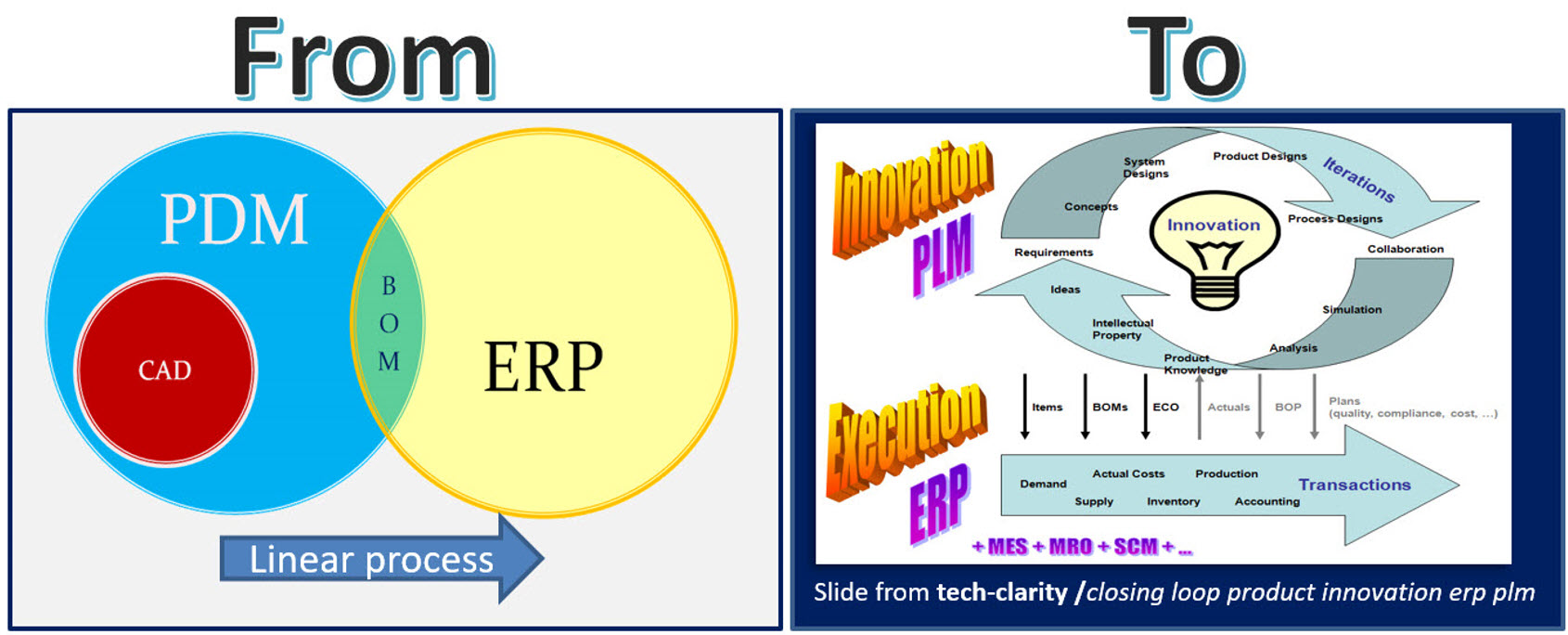
The image on the right describes perfectly the complementary roles of PLM and ERP. The image on the left shows the typical PDM-approach. PDM feeding ERP in a linear process. The image on the right, I believe it is from 2004, shows the best practice before digital transformation. PLM is supporting product innovation in an iterative approach, pushing released information to ERP for execution.
 As I think in images, I like the concept of a circle for PLM and an arrow for ERP. I am always using those two images in discussions with my customers when we want to understand if a particular activity should be in the PLM or ERP-domain.
As I think in images, I like the concept of a circle for PLM and an arrow for ERP. I am always using those two images in discussions with my customers when we want to understand if a particular activity should be in the PLM or ERP-domain.
Ten years ago, the PLM-domain was conceptually further extended by introducing support for products in operations and service. Similar to the EBOM (engineering) and the MBOM (manufacturing), the SBOM (service) was introduced to support product information for products in operation. In theory a full connected cicle.
Asset Lifecycle Management
At the same time, I was promoting PLM-practices for owners/operators to enhance Asset Lifecycle Management. My first post from June 2010 was called: PLM for Asset Lifecycle Management and Asset Development introduces this approach.
 Conceptually the SBOM and Asset Lifecycle Management have a lot in common. There is a design product, in this case, an asset (plant, machine) running in the field, and we need to make sure operators have the latest information about the asset. And in case of asset changes, which can be a maintenance operation, a repair or complete overall, we need to be sure the changes are based on the correct information from the as-built environment. This requires full configuration management.
Conceptually the SBOM and Asset Lifecycle Management have a lot in common. There is a design product, in this case, an asset (plant, machine) running in the field, and we need to make sure operators have the latest information about the asset. And in case of asset changes, which can be a maintenance operation, a repair or complete overall, we need to be sure the changes are based on the correct information from the as-built environment. This requires full configuration management.
Asset changes can be based on extensive projects that need to be treated like new product development projects, with a staged approach that can take weeks, months, sometimes years. These activities are typical activities performed in PLM-systems, not in MRO-systems that are designed to manage the actual operation. Again here we see the complementary roles of PLM (iterative) and MRO (execution).
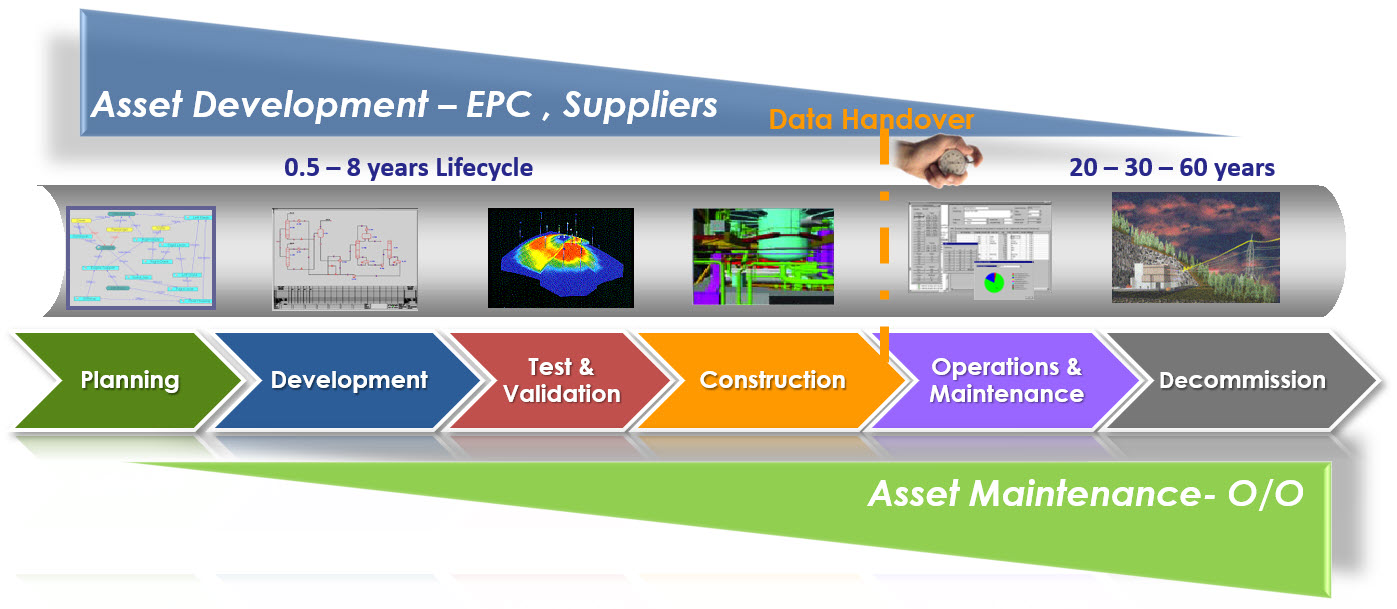
Since 2008, I have worked a lot in this environment, mainly in the nuclear and process industry. If you want to learn more about this aspect of PLM, I recommend looking at the PLMpartner website, where Bjørn Fidjeland, in cooperation with SharePLM, published a course on Plant Information Management. We worked together in several projects and Bjørn has done a great effort to describe the logical model to be used instead of a function-feature story.
Ten years ago, we were not calling this concept the “Digital Twin,” as the aim was to provide end-to-end support of asset information from engineering, procurement, and construction towards operation in a coordinated manner. The breaking point in the relation between the EPCs and Owner/Operators is the data-handover – how much of your IP can/do you expose and what is needed. Nowadays, we would call striving for end-to-end data continuity the Digital Thread.
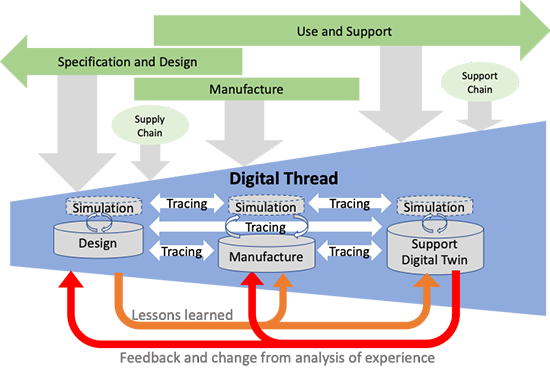
Hot from the press in this context, CIMdata just published a commentary Managing the Digital Thread in Global Value Chains describing Eurostep’s ShareAspace capabilities and experiences in managing an end-to-end information flow (Digital Thread) in a heterogeneous environment based on exchange standards like ISO 10303-239 PLCS. Their solution is based on what I consider a more modern approach for managing digital continuity compared to the traditional approach I described before. Compare the two images in this paragraph. The first image represents the old/current way with a disconnected handover, the second represents ShareAspace connected approach based on a real digital thread.
The Service BOM
As discussed with Asset Lifecycle Management, there is a disconnect between the engineering disciplines and operations in the field, looking from the point of view of an Asset owner/operator.
Now when we look from the perspective of a manufacturing company that produces assets to be serviced, we can identify a different dataflow and a new structure, the Service BOM (SBOM).
 The SBOM provides information on how a product needs to be serviced. What are the parts that require service, and what are the service kits that are possible for that product? For that reason, service engineering should be done in parallel to product engineering. When designing a product, the engineer needs to identify which the wearing parts (always require service in time) and which parts might be serviceable.
The SBOM provides information on how a product needs to be serviced. What are the parts that require service, and what are the service kits that are possible for that product? For that reason, service engineering should be done in parallel to product engineering. When designing a product, the engineer needs to identify which the wearing parts (always require service in time) and which parts might be serviceable.
There are different ways to look at the SBOM. Conceptually, the SBOM could be created in close relation with the EBOM. At the moment you define your product, you also should specify how the product will be serviced. See the image below

From this example, it is clear that part standardization and modularization have a considerable benefit for services downstream. What if you have only one serviceable part that applies to many products? The number of parts to have in stock will be strongly reduced instead of having many similar parts that only fit in a single product?
 Depending on the type of product, the SBOM can be generic, serving many products in the field. In that case, the company has to deal with catalogs, to be defined in PLM. Or the SBOM can be aligned with the As-Built of a capital product in the field. In that case, the concepts of Asset Lifecycle Management apply. Click on the image to see a clear picture.
Depending on the type of product, the SBOM can be generic, serving many products in the field. In that case, the company has to deal with catalogs, to be defined in PLM. Or the SBOM can be aligned with the As-Built of a capital product in the field. In that case, the concepts of Asset Lifecycle Management apply. Click on the image to see a clear picture.
![]() The SBOM on its own, in such an environment, will have links to specific documents, service instructions, operating manuals.
The SBOM on its own, in such an environment, will have links to specific documents, service instructions, operating manuals.
If your PLM-system allows it, extending the EBOM and MBOM with an SBOM is not a complex effort. What is crucial to understand is that the SBOM has its own lifecycle, which can even last longer than the active product sold. So sometimes, manufacturing specifications, related to service parts need to be maintained too, creating a link between the SBOM and potential MBOM(s).
ECM = Enterprise Change Management
When I discussed ECM in my previous post in the context of Engineering Change Management, I got the feedback that nowadays, everyone talks about Enterprise Change Management. Engineering Change Management is old school.

In the past, and even in a 2014 benchmark, a customer had two change management systems. One in PLM and one in ERP, and companies were looking into connecting these two processes. Like the BOM-interaction between PLM and ERP, this is technology-wise, never a real problem.
 The real problem in such situations was to come to a logical flow of events. Many times the company insisted that every change should start from the ERP-system as we like to standardize. This means that even an engineering change had to be registered first in the ERP-system
The real problem in such situations was to come to a logical flow of events. Many times the company insisted that every change should start from the ERP-system as we like to standardize. This means that even an engineering change had to be registered first in the ERP-system
Luckily the reach of PLM has grown. PLM is no longer the engineering tool (IT-system thinking). PLM has become the information backbone for product information all along the product lifecycle. Having the MBOM and SBOM available through a PLM-infrastructure allows organizations to streamline their processes.
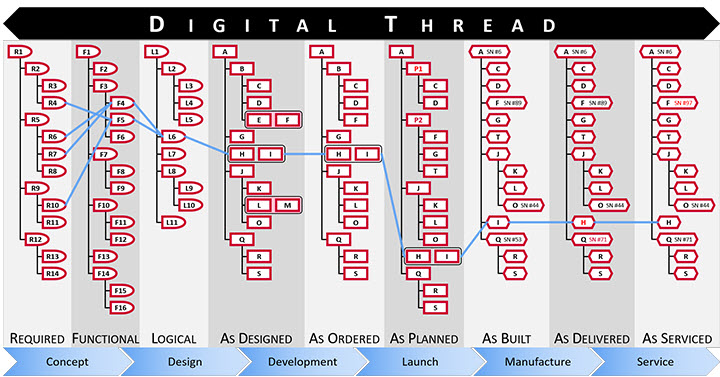
Aras – digital thread through connected structures
And in this modern environment, enterprise change management might take place mostly in a PLM-infrastructure. The PLM-infrastructure providing a digital thread, as the Aras picture above illustrates, provides the full traceability to support configuration management.
 However, we still have to remember that configuration management and engineering change management, first of all, are based on methodology and processes. Next, the combination of tools to be used will vary.
However, we still have to remember that configuration management and engineering change management, first of all, are based on methodology and processes. Next, the combination of tools to be used will vary.
I like to conclude this topic with a quote from Lee Perrin’s comment on my previous blog post
I would add that aerospace companies implemented CM, to avoid fatal consequences to their companies, but also to their flying customers.
PLM provides the framework within which to carry out Configuration Management. CM can indeed be carried out without PLM, as was done in the old paper-based days. As you have stated, PLM makes the whole CM process much more efficient. I think more transparent too.
Conclusion
After nine posts around the theme Learning from the past to understand the future, I walked through the history of CAD, PDM and PLM in a fast mode, pointing to practices and friction points. In the blogging space, it is hard to find this information as most blog posts are coming from software vendors explaining why their tool is needed. Hopefully, these series have helped many of you to understand a broader context. Now I want to focus on the future again in my upcoming blog posts.
Still, feel free to contact me and discuss methodology topics.
 Already five posts since we started looking at the roots of PLM, where every step illustrated that new technical capabilities could create opportunities for better practices. Alternatively, sometimes, these capabilities introduced complexity while maintaining old practices. Where the previous posts were design and engineering-centric, now I want to make the step moving to manufacturing-preparation and the MBOM. In my opinion, if you start to manage your manufacturing BOM in the context of your product design, you are in the scope of PLM.
Already five posts since we started looking at the roots of PLM, where every step illustrated that new technical capabilities could create opportunities for better practices. Alternatively, sometimes, these capabilities introduced complexity while maintaining old practices. Where the previous posts were design and engineering-centric, now I want to make the step moving to manufacturing-preparation and the MBOM. In my opinion, if you start to manage your manufacturing BOM in the context of your product design, you are in the scope of PLM.
For the moment, I will put two other related domains aside, i.e., Configuration Management and Configured Products. Note these domains are entirely different from each other.
Some data model principles
 In part five, I introduced the need to have a split between a logical product definition and a technical EBOM definition. The logical product definition is more the system or modular structure to be used when configuring solutions for a customer. The technical EBOM definition is, most of the time, a stable engineering specification independent of how and where the product is manufactured. The manufacturing BOM (the MBOM) should represent how the product will be manufactured, which can vary per location and vary over time. Let us look in some of the essential elements of this data model
In part five, I introduced the need to have a split between a logical product definition and a technical EBOM definition. The logical product definition is more the system or modular structure to be used when configuring solutions for a customer. The technical EBOM definition is, most of the time, a stable engineering specification independent of how and where the product is manufactured. The manufacturing BOM (the MBOM) should represent how the product will be manufactured, which can vary per location and vary over time. Let us look in some of the essential elements of this data model
The Product
 The logical definition of the product, which can also be a single component if you are a lower tier-supplier, has an understandable number, like 6030-10B. A customer needs to be able to order this product or part without a typo mistake. The product has features or characteristics that are used to sell the product. Usually, products do not have a revision, as it is a logical definition of a set of capabilities. Most of the time, marketing is responsible for product definition. This would be the sales catalog, which can be connected in a digital PLM environment. Like the PDM-ERP relation, there is a similar discussion related to where the catalog resides—more on the product side later in time.
The logical definition of the product, which can also be a single component if you are a lower tier-supplier, has an understandable number, like 6030-10B. A customer needs to be able to order this product or part without a typo mistake. The product has features or characteristics that are used to sell the product. Usually, products do not have a revision, as it is a logical definition of a set of capabilities. Most of the time, marketing is responsible for product definition. This would be the sales catalog, which can be connected in a digital PLM environment. Like the PDM-ERP relation, there is a similar discussion related to where the catalog resides—more on the product side later in time.
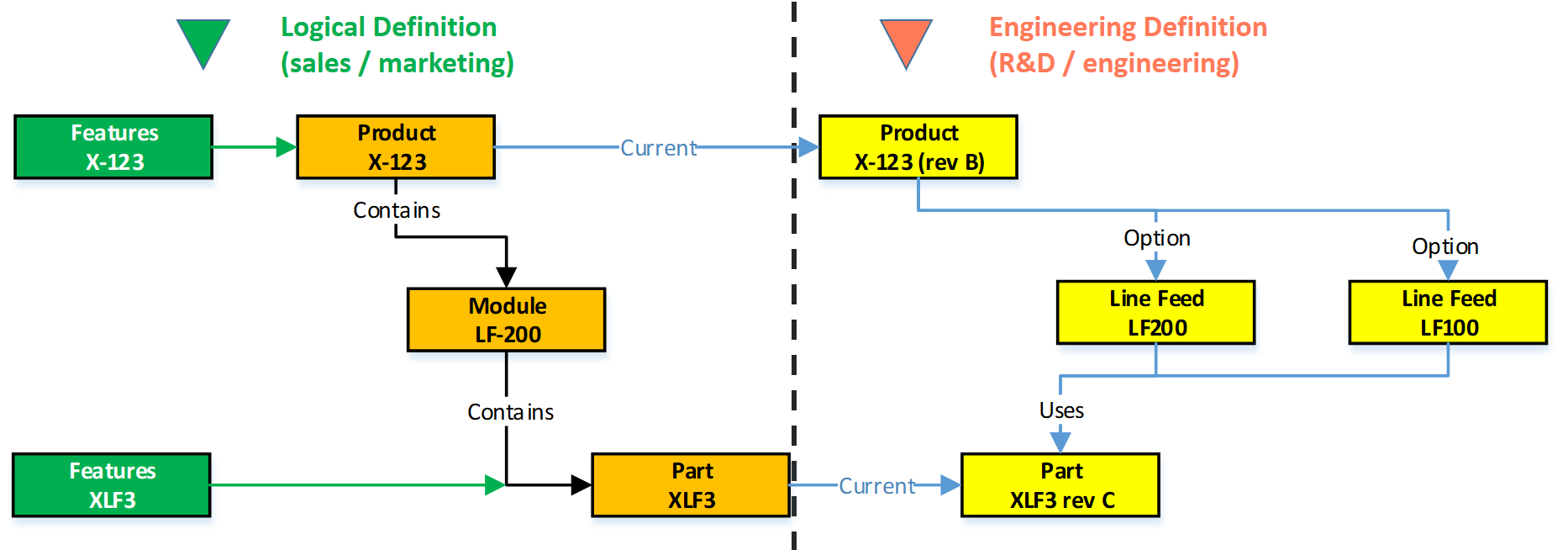
The EBOM
Related to the product or component in the logical definition, there is an actual EBOM, which represents the technical specification of the product. The image above shows the relation represented by the blue “current” link.
 Note: not all systems will support such a data model, and often the marketing sides in managed disconnected from the engineering side. Either in Excel or in a specialized Product Line Engineering (PLE) tools.
Note: not all systems will support such a data model, and often the marketing sides in managed disconnected from the engineering side. Either in Excel or in a specialized Product Line Engineering (PLE) tools.
We discussed in the previous post that if you want to minimize maintenance, meaning fewer revisions on your EBOM, you should not embed manufacturer-specific parts in your EBOM.
 The EBOM typically contains purchase parts and make parts. The purchased parts are sourced based on their specification, and you might have a single source in the beginning. The make parts are entirely under your engineering control, and you define where they are produced and by whom. For the rest, the EBOM might have functional groupings of modules and subassemblies that are defined for reuse by engineering.
The EBOM typically contains purchase parts and make parts. The purchased parts are sourced based on their specification, and you might have a single source in the beginning. The make parts are entirely under your engineering control, and you define where they are produced and by whom. For the rest, the EBOM might have functional groupings of modules and subassemblies that are defined for reuse by engineering.
 Note: An EBOM is the place where multidisciplinary collaboration comes together. This post mainly deals with the mechanical part (as we are looking at the past)
Note: An EBOM is the place where multidisciplinary collaboration comes together. This post mainly deals with the mechanical part (as we are looking at the past)
Note: An EBOM can contain multiple valid configurations which you can filter based on a customer or market-specific demand. In this case, we talk about a Configured EBOM or a 150 % EBOM.
The MBOM
 The MBOM represents the way the unique product is going to be manufactured. This means the MBOM-structure will represent the manufacturing steps. For each EBOM-purchase-part, the approved manufacturer for that plant needs to be selected. For each make-part in the EBOM, if made in this plant per customer order, the EBOM parts need to be resolved by one or more manufacturing steps combined with purchased materials.
The MBOM represents the way the unique product is going to be manufactured. This means the MBOM-structure will represent the manufacturing steps. For each EBOM-purchase-part, the approved manufacturer for that plant needs to be selected. For each make-part in the EBOM, if made in this plant per customer order, the EBOM parts need to be resolved by one or more manufacturing steps combined with purchased materials.
Let us look at some examples:
The flat MBOM
Some companies do not have real machinery anymore in their plants, the product they deliver to the market is only assembled at the best financial location. This means that all MBOM-parts should arrive at the shop floor to be assembled there. As an example, we have plant A below.
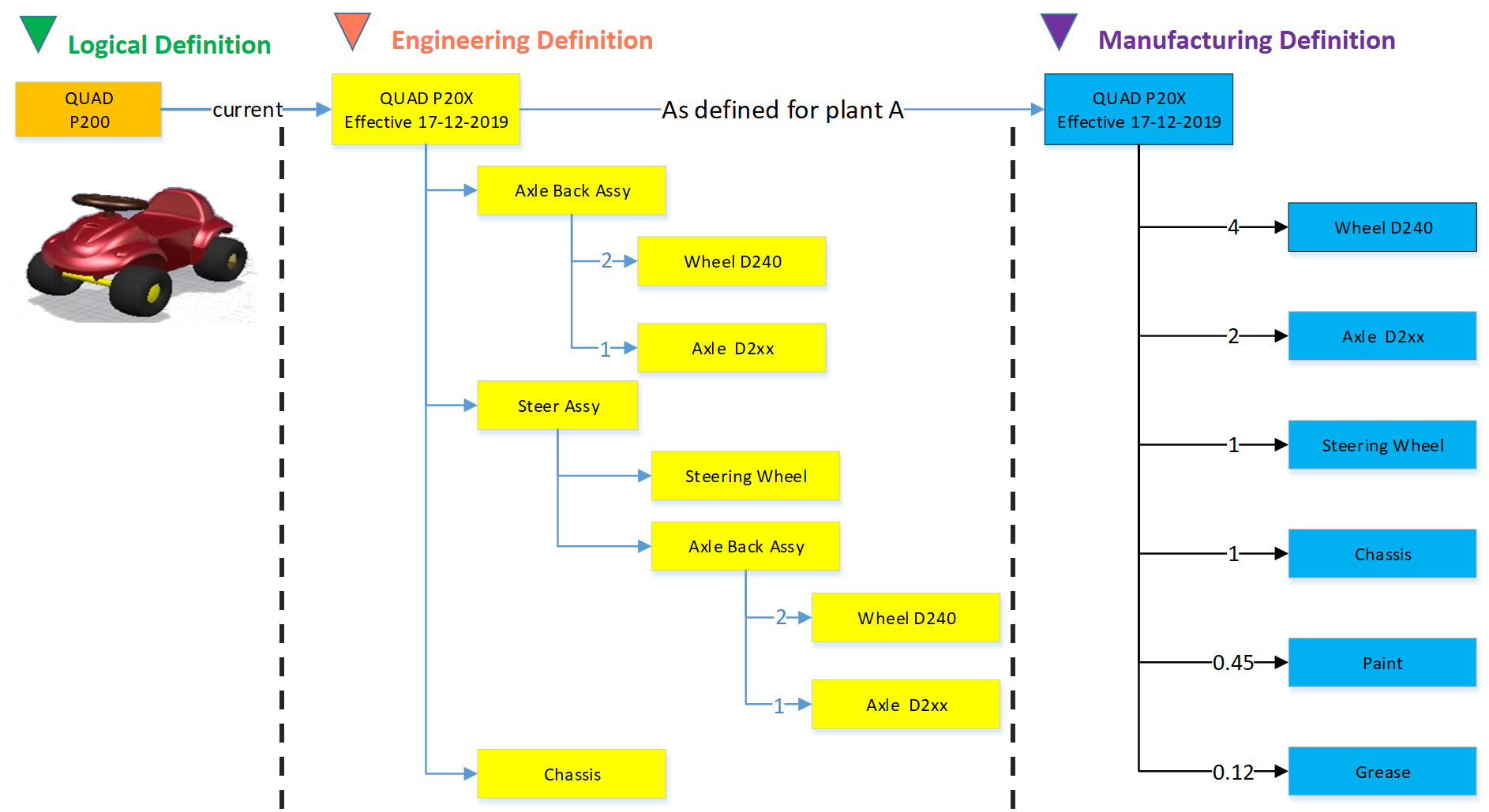
Of course, this is a simplified version to illustrate the basics of the MBOM. The flat MBOM only makes sense if the product is straightforward to assemble. Based on the engineering specifications, the assembly drawing(s) people on the shop floor will know what to do.
The engineering definition specifies that the chassis needs to be painted, and fitting the axles requires grease. These quantities are not visible in the EBOM; they will appear in the MBOM. The quantities and the unit of measure are, of course, relevant here.
Note: The exact quantities for paint and grease might be adjusted in the MBOM when a series of Squads have been manufactured.
The MBOM and Bill of Process
Most of the time, a product is manufactured in several process steps. For that reason, the MBOM is closely related to the Bill of Process or the Routing definitions. The image below illustrates the relationship between an MBOM and the operations in a plant.
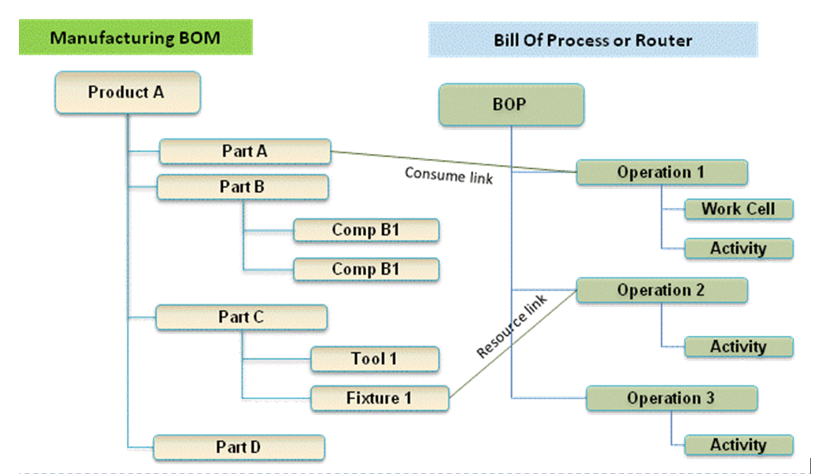
If we continue with our example of the Squad, let us now assume that the wheels and the axle are joined together in a work cell. In addition, the chassis is painted in a separate cell. The MBOM would look like the image below:

In the image, we see that the same Engineering definition now results in a different MBOM. A company can change the MBOM when optimizing the production, without affecting the engineering definition. In this MBOM, the Axle assembly might also be used in other squads manufactured by the company.
The MBOM and purchased parts
 In the previous example, all components for the Squad were manufactured by the same company with the option to produce in Plant A or in Plant B. Now imagine the company also has a plant C in a location where they cannot produce the wheels and axle assembly. Therefore plant C has to “purchase” the Wheel-Axle assembly, and lucky for them plant B is selling the Wheel+Axle assembly to the market as a product.
In the previous example, all components for the Squad were manufactured by the same company with the option to produce in Plant A or in Plant B. Now imagine the company also has a plant C in a location where they cannot produce the wheels and axle assembly. Therefore plant C has to “purchase” the Wheel-Axle assembly, and lucky for them plant B is selling the Wheel+Axle assembly to the market as a product.
The MBOM for plant C would look like the image below:
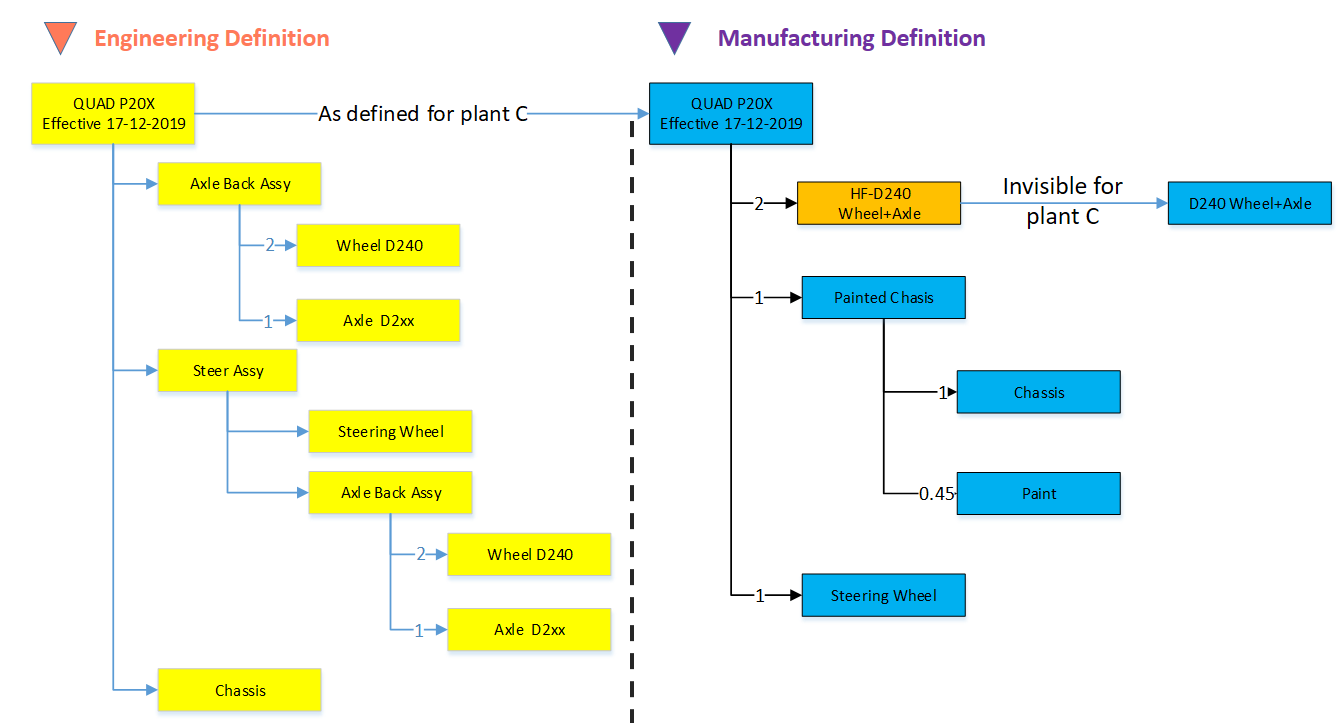
For Plant C, they will order the right amount of the Wheel+Axle product, according to its specifications (HF-D240). How the Wheel+Axle product is manufactured is invisible for Plant C, the only point to check is if the Wheel+Axle product complies with the Engineering Definition and if its purchase price is within the target price range.
Why this simple EBOM-MBOM story?
 For those always that have been active in the engineering domain, a better understanding of the information flow downstream to manufacturing is crucial. Historically this flow of information has been linear – and in many companies, it is still the fact. The main reason for that lies in the fact that engineering had their own system (PDM or PLM), and manufacturing has their own system (ERP).
For those always that have been active in the engineering domain, a better understanding of the information flow downstream to manufacturing is crucial. Historically this flow of information has been linear – and in many companies, it is still the fact. The main reason for that lies in the fact that engineering had their own system (PDM or PLM), and manufacturing has their own system (ERP).
Engineers did their best to provide the best engineering specification and release the data to ERP. In the early days, as discussed in Part 4, the engineering specification was most of the time based on a kind of hybrid BOM containing engineering and manufacturing parts already defined.
 Next, manufacturing engineering uses the engineering specifications to define the manufacturing BOM in the ERP system. Based on the drawings and parts list, they create a preferred manufacturing process (MBOM and BOP) – most of the time, a manual process. Despite the effort done by engineering, there might be a need to change the product. A different shape or dimension make manufacturing more efficient or done with existing tooling. This means an iteration, which causes delays and higher engineering costs.
Next, manufacturing engineering uses the engineering specifications to define the manufacturing BOM in the ERP system. Based on the drawings and parts list, they create a preferred manufacturing process (MBOM and BOP) – most of the time, a manual process. Despite the effort done by engineering, there might be a need to change the product. A different shape or dimension make manufacturing more efficient or done with existing tooling. This means an iteration, which causes delays and higher engineering costs.
The first optimization invented was the PDM-ERP interface to reduce the manual work and introduction of typos/misunderstanding of data. This topic was “hot” between 2000 and 2010, and I visited many SmarTeam customers and implementers to learn and later explain that this is a mission impossible. The picture below says it all.

We have an engineering BOM (with related drawings). Through an interface, this EBOM will be restructured into a manufacturing BOM, thanks to all kinds of “clever” programming based on particular attributes. Discussed in Part 3
 The result, however, was that the interface was never covering all situations and became the most expensive part of the implementation.
The result, however, was that the interface was never covering all situations and became the most expensive part of the implementation.
Good business for the implementing companies, bad for the perception of PDM/PLM.
The lesson learned from all these situations: If you have a PLM-system that can support both the EBOM and MBOM in the same environment, you do not need this complex interface anymore. You can still use some automation to move from an EBOM to an MBOM.
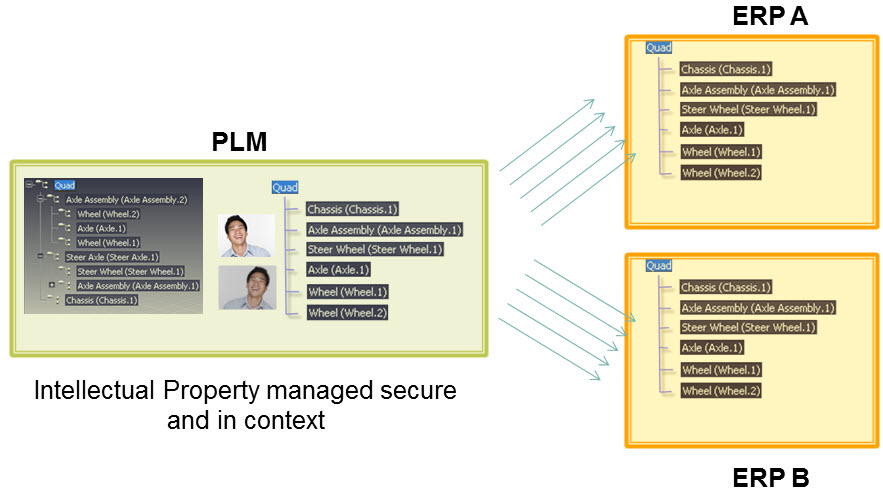
However, three essential benefits come from this approach
- Working in a single environment allows manufacturing engineers to work directly in the context of the EBOM, proposing changes to engineering in the same environment and perform manual restructuring on the MBOM as programming logic does not exist. Still, compare tools will ensure all EBOM-parts are resolved in the manufacturing definition.
- All product Intellectual Property is now managed in a single environment. There is no scattered product information residing in local ERP-systems. When companies moved towards multiple plants for manufacturing, there was the need for a centralized generic MBOM to be resolved for the local plant (local suppliers / local plant conditions). Having the generic MBOM and Bill of Process in PLM was the solution.
- When engineers and manufacturing engineers work in the same environment, manufacturing engineering can start earlier with the manufacturing process definition, providing early feedback to engineering even when the engineering specification has not been released. This approach allows real concurrent engineering, reducing time to market and cost significantly
Conclusion
Again 1600 words this time. We are now at the stage that connecting the EBOM and the MBOM in PLM has become a best practice in most standard PLM-systems. If implemented correctly, the interface to ERP is no longer on the critical path – the technology never has been the limitation – it is all about methodology.
Next time a little bit more on advanced EBOM/MBOM interactions
One week ago, Yoann Maingon wrote an innocent post with the question: Has FFF killed? The question was raised related to a 2014 problem at GM, where a changed part was causing fatal accidents.
 The discussion started by Yoann and here my short extract. Assuming this problem was a configuration management issue and Yoann somehow indicated that the problem might be related to the fact that ERP-systems do not carry a revision on the part number – leading to an unnoticed change. Therefore, he assumes there is a disconnect between the PLM-side (where we have parts with multiple lifecycle states and revisions) and ERP (where we have an industrial lifecycle – prototype/production).
The discussion started by Yoann and here my short extract. Assuming this problem was a configuration management issue and Yoann somehow indicated that the problem might be related to the fact that ERP-systems do not carry a revision on the part number – leading to an unnoticed change. Therefore, he assumes there is a disconnect between the PLM-side (where we have parts with multiple lifecycle states and revisions) and ERP (where we have an industrial lifecycle – prototype/production).
He posted his thoughts, and then LinkedIn exploded (currently 116 comments), which means it is a topic that is of significant concern in our community. Next, if you read the comments, there are different viewpoints:
- What does FFF really imply?
- What about revisions of parts?
- What are the best practices?
Let’s investigate these viewpoints with some comments
What does FFF really imply?
When we talk about FFF in engineering, we mean Form, Fit and Function – the three primary characteristics to describe a part (source Wikipedia)
- Form refers to such characteristics as external dimensions, weight, size, and visual appearance of a part or assembly. This is the element of FFF that is most affected by an engineer’s aesthetic choices, including enclosure, chassis, and control panel, that become the outward “face” of the product.
- Fit refers to the ability of the part or feature to connect to, mate with, or join to another feature or part within an assembly. The “fit” allows the part to meet the required assembly tolerances to be useful.
- Function is a criterion that is met when the part performs its stated purpose effectively and reliably. In an electronics product, for example, a function can depend on the solid-state components used, the software or firmware, and quite often on the features of the electronics enclosure selected.
 One of the comments in Yoann’s post referred to Safe/Unsafe as a potential functional characteristic. I think this addition is not needed. Safety should be a requirement for the part, not a characteristic.
One of the comments in Yoann’s post referred to Safe/Unsafe as a potential functional characteristic. I think this addition is not needed. Safety should be a requirement for the part, not a characteristic.
FFF was and still is an approach for engineers to decide if a new, improved version of the part would get a revision or needs a new part number.
I think before we dive deeper into the other viewpoints, it is crucial to define the part number a little more.
In a correct PLM data model, there are two types of part numbers. First, the internal part number that your company uses inside its engineering Bill of Materials to identify a part. This part number can be a meaningless part only to provide uniqueness inside the company.
In 2015 I wrote several posts related to best practices and data modeling for PLM. The most relevant posts to this discussion are here:
The part number can specify a part that needs to be manufactured according to specification, or it can be a part that needs to be purchased from an available supplier/manufacturer. The manufacturer part number is, most of the time, a meaningful number (6 – 7 characters) as these parts need to be ordered by your company. The manufacturer part number is the SKU for the manufacturer. As you can imagine in the manufacturer’s catalog, there isn’t a revision mentioned. In graphics, see the image below:

Your company might sell Product MP-323121 (note: the ID is meaningful to help the customer to order the product).
Internally there is a related EBOM that specifies the product. The EBOM top part is O122 (note: here, we can use a meaningless identifier as all is digitally connected).
For the manufacturing of O122, we need to resolve the EBOM according to its specifications. Therefore, for Part O124, the company needs to decide to purchase from their approved manufacturers either part ABC-21231 or XYZ-88818 (note: again, a meaningful ID as these companies are not digitally connected).
Now coming back to the FFF-discussion. For the orange parts, with a meaningful ID, no revision exists. However, if Assembly O122 is 100% FFF compatible, the Product ID MP-323121 will not change. It allows your company to optimize the EBOM and/or MBOM, meanwhile keeping 100% compatibility to the outside world. (note: the same principle applies to the two manufacturers for Part O124.)
In case Top Assembly O122 has new or changed parts – what should happen there?
 At that moment, the definition has changed. The definitions, most of the time described in documents/drawings/models, are related information to the BOM. Therefore the Top Assembly O122 should get a new identifier. There is no need to name it a revision, it is a new data set in the PLM-system, again with a meaningless identifier as we are connected digitally,
At that moment, the definition has changed. The definitions, most of the time described in documents/drawings/models, are related information to the BOM. Therefore the Top Assembly O122 should get a new identifier. There is no need to name it a revision, it is a new data set in the PLM-system, again with a meaningless identifier as we are connected digitally,
What about revisions of parts?
Of course, the management of changes existed long before PLM-systems were introduced.
 The specifications of a part were defined in drawings. The drawing contained all the information, not only the geometry definitions, but also specifications on how to manufacture the part.
The specifications of a part were defined in drawings. The drawing contained all the information, not only the geometry definitions, but also specifications on how to manufacture the part.
For complex products, a considerable set of consistently related drawings would be released to manufacturing. A release process with physical signatures on it.
At the same time, there was no discussion: the drawing represents the part. And as there was no digital connection, part numbers/drawing numbers were meaningful, often with the format of the drawing as part of the identifier.
![]()
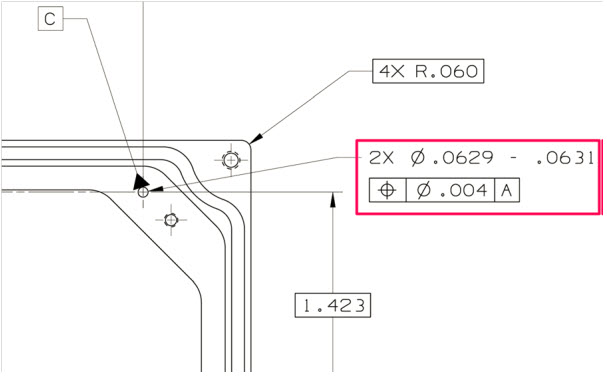 In case changes were needed, for example, fixing a dimension or tolerance as discovered during manufacturing, the drawing had to be revised to remain consistent. First, in the original drawing, the issue or change was marked in red (redlining). Then engineering had to create a new version of the drawing.
In case changes were needed, for example, fixing a dimension or tolerance as discovered during manufacturing, the drawing had to be revised to remain consistent. First, in the original drawing, the issue or change was marked in red (redlining). Then engineering had to create a new version of the drawing.
Depending on the impact of change (here comes also the FFF-principle), people decided if a new part number was needed (FFF-change) or that the change only required an update of the drawing(s), meaning a revision. If the difference was small (for example, adding a missing annotation), it could be called a minor change, all to be reflected in the drawing number, which equals the part number in this approach. So, when we talk about revisions of parts, we are talking about a document change.
A lousy practice from that approach is also that often manufacturing just redlines a drawing and keeps the redlined drawing as their source. It is too time-consuming or difficult to update the source drawing(s) through a change process. Engineering is not aware of this change, and when a later change comes through from engineering, these “fixes” might be missed as there is no traceability.
Generic example of a PLM data model and its relationsWhen PLM-systems were introduced, of course, companies did not want to disrupt their existing ways of working. Therefore, they were asking the PLM-editors to enable revisions on parts and so the PLM-editors did (or do).

Decoupling of parts and documents in a PLM data model
However, if you want to use the PLM-system in the best manner, you need to “decouple” the concept: part number equals drawing number, combined with the possibility to start using meaningless identifiers, as relations between parts and drawings are managed in the PLM-system through relational links.
Relevant post related to the PLM data model are:
- EBOM and (CAD) Documents
- Intelligent Part or Product numbers
- The impact of Non-Intelligent Part numbers
What are the best practices?
As some people mentioned in their comments to Yoann’s post, why do we have to answer this question as all is already well understood and described in best practices? I agree with that statement: Best Practices exist – so how to obtain them?
 First, there is the whole framework of Configuration Management, which existed long before PLM-systems were introduced. If you follow their methodology, you can be (almost) guaranteed your information is consistent and correct. Configuration Management is crucial in areas where the impact of an error is enormous, like the GM-example Yoann referred to. Also, companies in the Aerospace and Defense industry are the ones that have strict configuration management in place.
First, there is the whole framework of Configuration Management, which existed long before PLM-systems were introduced. If you follow their methodology, you can be (almost) guaranteed your information is consistent and correct. Configuration Management is crucial in areas where the impact of an error is enormous, like the GM-example Yoann referred to. Also, companies in the Aerospace and Defense industry are the ones that have strict configuration management in place.
Configuration management does not come for free. It requires an investment in skills, potentially a change in ways of working, and requires an overhead. Manufacturing companies that are creating less “risky” products often focus more on optimizing (= reducing) the cost of their internal processes instead of investing in proper methodologies to manage consistency.
If you want to learn more about CM, investigate the Institute of Process Excellence (IPX), the founders of the CM2 framework for Enterprise Configuration Management, and much more. Note: Their knowledge does not come for free, which I can understand. However, it also creates a barrier for the company’s further investment in CM as this kind of strategic investments are hard to sell at the management level by individuals in a company.
 In the context of CM, I advise you to follow Martijn Dullaart, who is quite active in our social community. His latest blog post related to this thread is: It’s about Interchangeability and Traceability
In the context of CM, I advise you to follow Martijn Dullaart, who is quite active in our social community. His latest blog post related to this thread is: It’s about Interchangeability and Traceability
With the introduction of PLM-system, these companies and the PLM-editors created the opportunity to implement configuration management in their system.
 The data inside the system would be the “single version of the truth.” Unfortunately, this was most of the time, just a sales strategy, falsely giving the impression that information is under control now. Last year I wrote several posts related to the relation between PLM and CM, starting from PLM and Configuration Management – a happy marriage?
The data inside the system would be the “single version of the truth.” Unfortunately, this was most of the time, just a sales strategy, falsely giving the impression that information is under control now. Last year I wrote several posts related to the relation between PLM and CM, starting from PLM and Configuration Management – a happy marriage?
If you are interested in another resource for information related to these topics, have a look at the website from Jörg Eisenträger who also collected his best practices for PLM and CM for sharing (thanks Paul van der Ree for the link)
Don’t expect best practices from your PLM-vendors as their role is to sell software. It is the continuous discussion between:
- A PLM-system that forces companies to work according to embedded methodology (hard to sell/implement but idealistically correct)
And
- A flexible PLM-system that allows you to build and configure anything (easy to sell/challenging to implement correctly, depending on “wise” decisions)
The Future
 Even though most companies are working drawing-centric, with or without a linked PLM-backbone for BOM-management, the next upcoming challenge is to evolve to model-based practices. The current CM-practices still talk about documents, although documents are already electronic datasets in that context. The future, however, in a model-based enterprise evolves related to connected models, 3D Models, but also simulation and software models, with different lifecycles and pace of change. For the model-based enterprise, we need to develop digital best practices that guarantee the same level of quality, however, executed and/or supported by (AI) Artificial Intelligence. AI is needed as human beings cannot physically analyze and understand all the impact of a change in such an environment.
Even though most companies are working drawing-centric, with or without a linked PLM-backbone for BOM-management, the next upcoming challenge is to evolve to model-based practices. The current CM-practices still talk about documents, although documents are already electronic datasets in that context. The future, however, in a model-based enterprise evolves related to connected models, 3D Models, but also simulation and software models, with different lifecycles and pace of change. For the model-based enterprise, we need to develop digital best practices that guarantee the same level of quality, however, executed and/or supported by (AI) Artificial Intelligence. AI is needed as human beings cannot physically analyze and understand all the impact of a change in such an environment.
Conclusion
The FFF-discussion illustrates that building a consistent framework within PLM is not an easy goal to achieve. My blog buddy Oleg Shilovitsky would claim that we consultants create the complexity. PLM-editors will never solve this complexity, it is up to your company’s mission to invest in knowledge to understand why and how to reduce the complexity. With this post and the related links and discussions, I hope more clarity will help you to make “wise” decisions.
 In my previous post, the PLM blame game, I briefly mentioned that there are two delivery models for PLM. One approach based on a PLM system, that contains predefined business logic and functionality, promoting to use the system as much as possible out-of-the-box (OOTB) somehow driving toward a certain rigidness or the other approach where the PLM capabilities need to be developed on top of a customizable infrastructure, providing more flexibility. I believe there has been a debate about this topic over more than 15 years without a decisive conclusion. Therefore I will take you through the pros and cons of both approaches illustrated by examples from the field.
In my previous post, the PLM blame game, I briefly mentioned that there are two delivery models for PLM. One approach based on a PLM system, that contains predefined business logic and functionality, promoting to use the system as much as possible out-of-the-box (OOTB) somehow driving toward a certain rigidness or the other approach where the PLM capabilities need to be developed on top of a customizable infrastructure, providing more flexibility. I believe there has been a debate about this topic over more than 15 years without a decisive conclusion. Therefore I will take you through the pros and cons of both approaches illustrated by examples from the field.
PLM started as a toolkit
 The initial cPDM/PLM systems were toolkits for several reasons. In the early days, scalable connectivity was not available or way too expensive for a standard collaboration approach. Engineering information, mostly design files, needed to be shared globally in an efficient manner, and the PLM backbone was often a centralized repository for CAD-data. Bill of Materials handling in PLM was often at a basic level, as either the ERP-system (mostly Aerospace/Defense) or home-grown developed BOM-systems(Automotive) were in place for manufacturing.
The initial cPDM/PLM systems were toolkits for several reasons. In the early days, scalable connectivity was not available or way too expensive for a standard collaboration approach. Engineering information, mostly design files, needed to be shared globally in an efficient manner, and the PLM backbone was often a centralized repository for CAD-data. Bill of Materials handling in PLM was often at a basic level, as either the ERP-system (mostly Aerospace/Defense) or home-grown developed BOM-systems(Automotive) were in place for manufacturing.
Depending on the business needs of the company, the target was too connect as much as possible engineering data sources to the PLM backbone – PLM originated from engineering and is still considered by many people as an engineering solution. For connectivity interfaces and integrations needed to be developed in a time that application integration frameworks were primitive and complicated. This made PLM implementations complex and expensive, so only the large automotive and aerospace/defense companies could afford to invest in such systems. And a lot of tuition fees spent to achieve results. Many of these environments are still operational as they became too risky to touch, as I described in my post: The PLM Migration Dilemma.
The birth of OOTB
 Around the year 2000, there was the first development of OOTB PLM. There was Agile (later acquired by Oracle) focusing on the high-tech and medical industry. Instead of document management, they focused on the scenario from bringing the BOM from engineering to manufacturing based on a relatively fixed scenario – therefore fast to implement and fast to validate. The last point, in particular, is crucial in regulated medical environments.
Around the year 2000, there was the first development of OOTB PLM. There was Agile (later acquired by Oracle) focusing on the high-tech and medical industry. Instead of document management, they focused on the scenario from bringing the BOM from engineering to manufacturing based on a relatively fixed scenario – therefore fast to implement and fast to validate. The last point, in particular, is crucial in regulated medical environments.
At that time, I was working with SmarTeam on the development of templates for various industries, with a similar mindset. A predefined template would lead to faster implementations and therefore reducing the implementation costs. The challenge with SmarTeam, however, was that is was very easy to customize, based on Microsoft technology and wizards for data modeling and UI design.
 This was not a benefit for OOTB-delivery as SmarTeam was implemented through Value Added Resellers, and their major revenue came from providing services to their customers. So it was easy to reprogram the concepts of the templates and use them as your unique selling points towards a customer. A similar situation is now happening with Aras – the primary implementation skills are at the implementing companies, and their revenue does not come from software (maintenance).
This was not a benefit for OOTB-delivery as SmarTeam was implemented through Value Added Resellers, and their major revenue came from providing services to their customers. So it was easy to reprogram the concepts of the templates and use them as your unique selling points towards a customer. A similar situation is now happening with Aras – the primary implementation skills are at the implementing companies, and their revenue does not come from software (maintenance).
The result is that each implementer considers another implementer as a competitor and they are not willing to give up their IP to the software company.
SmarTeam resellers were not eager to deliver their IP back to SmarTeam to get it embedded in the product as it would reduce their unique selling points. I assume the same happens currently in the Aras channel – it might be called Open Source however probably it is only high-level infrastructure.
Around 2006 many of the main PLM-vendors had their various mid-market offerings, and I contributed at that time to the SmarTeam Engineering Express – a preconfigured solution that was rapid to implement if you wanted.
 Although the SmarTeam Engineering Express was an excellent sales tool, the resellers that started to implement the software began to customize the environment as fast as possible in their own preferred manner. For two reasons: the customer most of the time had different current practices and secondly the money come from services. So why say No to a customer if you can say Yes?
Although the SmarTeam Engineering Express was an excellent sales tool, the resellers that started to implement the software began to customize the environment as fast as possible in their own preferred manner. For two reasons: the customer most of the time had different current practices and secondly the money come from services. So why say No to a customer if you can say Yes?
OOTB and modules
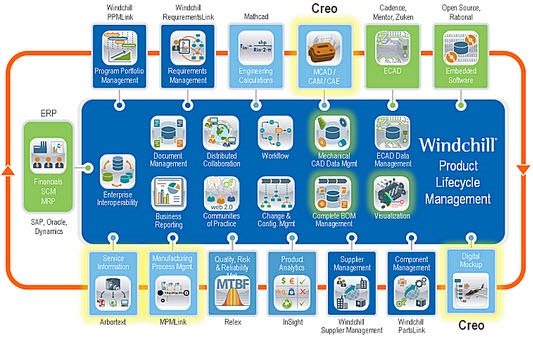 Initially, for the leading PLM Vendors, their mid-market templates were not just aiming at the mid-market. All companies wanted to have a standardized PLM-system with as little as possible customizations. This meant for the PLM vendors that they had to package their functionality into modules, sometimes addressing industry-specific capabilities, sometimes areas of interfaces (CAD and ERP integrations) as a module or generic governance capabilities like portfolio management, project management, and change management.
Initially, for the leading PLM Vendors, their mid-market templates were not just aiming at the mid-market. All companies wanted to have a standardized PLM-system with as little as possible customizations. This meant for the PLM vendors that they had to package their functionality into modules, sometimes addressing industry-specific capabilities, sometimes areas of interfaces (CAD and ERP integrations) as a module or generic governance capabilities like portfolio management, project management, and change management.
The principles behind the modules were that they need to deliver data model capabilities combined with business logic/behavior. Otherwise, the value of the module would be not relevant. And this causes a challenge. The more business logic a module delivers, the more the company that implements the module needs to adapt to more generic practices. This requires business change management, people need to be motivated to work differently. And who is eager to make people work differently? Almost nobody, as it is an intensive coaching job that cannot be done by the vendors (they sell software), often cannot be done by the implementers (they do not have the broad set of skills needed) or by the companies (they do not have the free resources for that). Precisely the principles behind the PLM Blame Game.
OOTB modularity advantages
 The first advantage of modularity in the PLM software is that you only buy the software pieces that you really need. However, most companies do not see PLM as a journey, so they agree on a budget to start, and then every module that was not identified before becomes a cost issue. Main reason because the implementation teams focus on delivering capabilities at that stage, not at providing value-based metrics.
The first advantage of modularity in the PLM software is that you only buy the software pieces that you really need. However, most companies do not see PLM as a journey, so they agree on a budget to start, and then every module that was not identified before becomes a cost issue. Main reason because the implementation teams focus on delivering capabilities at that stage, not at providing value-based metrics.
 The second potential advantage of PLM modularity is the fact that these modules supposed to be complementary to the other modules as they should have been developed in the context of each other. In reality, this is not always the case. Yes, the modules fit nicely on a single PowerPoint slide, however, when it comes to reality, there are separate systems with a minimum of integration with the core. However, the advantage is that the PLM software provider now becomes responsible for upgradability or extendibility of the provided functionality, which is a serious point to consider.
The second potential advantage of PLM modularity is the fact that these modules supposed to be complementary to the other modules as they should have been developed in the context of each other. In reality, this is not always the case. Yes, the modules fit nicely on a single PowerPoint slide, however, when it comes to reality, there are separate systems with a minimum of integration with the core. However, the advantage is that the PLM software provider now becomes responsible for upgradability or extendibility of the provided functionality, which is a serious point to consider.
 The third advantage from the OOTB modular approach is that it forces the PLM vendor to invest in your industry and future needed capabilities, for example, digital twins, AR/VR, and model-based ways of working. Some skeptic people might say PLM vendors create problems to solve that do not exist yet, optimists might say they invest in imagining the future, which can only happen by trial-and-error. In a digital enterprise, it is: think big, start small, fail fast, and scale quickly.
The third advantage from the OOTB modular approach is that it forces the PLM vendor to invest in your industry and future needed capabilities, for example, digital twins, AR/VR, and model-based ways of working. Some skeptic people might say PLM vendors create problems to solve that do not exist yet, optimists might say they invest in imagining the future, which can only happen by trial-and-error. In a digital enterprise, it is: think big, start small, fail fast, and scale quickly.
OOTB modularity disadvantages
 Most of the OOTB modularity disadvantages will be advantages in the toolkit approach, therefore discussed in the next paragraph. One downside from the OOTB modular approach is the disconnect between the people developing the modules and the implementers in the field. Often modules are developed based on some leading customer experiences (the big ones), where the majority of usage in the field is targeting smaller companies where people have multiple roles, the typical SMB approach. SMB implementations are often not visible at the PLM Vendor R&D level as they are hidden through the Value Added Reseller network and/or usually too small to become apparent.
Most of the OOTB modularity disadvantages will be advantages in the toolkit approach, therefore discussed in the next paragraph. One downside from the OOTB modular approach is the disconnect between the people developing the modules and the implementers in the field. Often modules are developed based on some leading customer experiences (the big ones), where the majority of usage in the field is targeting smaller companies where people have multiple roles, the typical SMB approach. SMB implementations are often not visible at the PLM Vendor R&D level as they are hidden through the Value Added Reseller network and/or usually too small to become apparent.
Toolkit advantages
 The most significant advantage of a PLM toolkit approach is that the implementation can be a journey. Starting with a clear business need, for example in modern PLM, create a digital thread and then once this is achieved dive deeper in areas of the lifecycle that require improvement. And increased functionality is only linked to the number of users, not to extra costs for a new module.
The most significant advantage of a PLM toolkit approach is that the implementation can be a journey. Starting with a clear business need, for example in modern PLM, create a digital thread and then once this is achieved dive deeper in areas of the lifecycle that require improvement. And increased functionality is only linked to the number of users, not to extra costs for a new module.
However, if the development of additional functionality becomes massive, you have the risk that low license costs are nullified by development costs.
 The second advantage of a PLM toolkit approach is that the implementer and users will have a better relationship in delivering capabilities and therefore, a higher chance of acceptance. The implementer builds what the customer is asking for.
The second advantage of a PLM toolkit approach is that the implementer and users will have a better relationship in delivering capabilities and therefore, a higher chance of acceptance. The implementer builds what the customer is asking for.
However, as Henry Ford said, if I would ask my customers what they wanted, they would ask for faster horses.
Toolkit considerations
There are several points where a PLM toolkit can be an advantage but also a disadvantage, very much depending on various characteristics of your company and your implementation team. Let’s review some of them:
 Innovative: a toolkit does not provide an innovative way of working immediately. The toolkit can have an infrastructure to deliver innovative capabilities, even as small demonstrations, the implementation, and methodology to implement this innovative way of working needs to come from either your company’s resources or your implementer’s skills.
Innovative: a toolkit does not provide an innovative way of working immediately. The toolkit can have an infrastructure to deliver innovative capabilities, even as small demonstrations, the implementation, and methodology to implement this innovative way of working needs to come from either your company’s resources or your implementer’s skills.
 Uniqueness: with a toolkit approach, you can build a unique PLM infrastructure that makes you more competitive than the other. Don’t share your IP and best practices to be more competitive. This approach can be valid if you truly have a competing plan here. Otherwise, the risk might be you are creating a legacy for your company that will slow you down later in time.
Uniqueness: with a toolkit approach, you can build a unique PLM infrastructure that makes you more competitive than the other. Don’t share your IP and best practices to be more competitive. This approach can be valid if you truly have a competing plan here. Otherwise, the risk might be you are creating a legacy for your company that will slow you down later in time.
 Performance: this is a crucial topic if you want to scale your solution to the enterprise level. I spent a lot of time in the past analyzing and supporting SmarTeam implementers and template developers on their journey to optimize their solutions. Choosing the right algorithms, the right data modeling choices are crucial.
Performance: this is a crucial topic if you want to scale your solution to the enterprise level. I spent a lot of time in the past analyzing and supporting SmarTeam implementers and template developers on their journey to optimize their solutions. Choosing the right algorithms, the right data modeling choices are crucial.
Sometimes I came into a situation where the customer blamed SmarTeam because customizations were possible – you can read about this example in an old LinkedIn post: the importance of a PLM data model
 Experience: When you plan to implement PLM “big” with a toolkit approach, experience becomes crucial as initial design decisions and scope are significant for future extensions and maintainability. Beautiful implementations can become a burden after five years as design decisions were not documented or analyzed. Having experience or an experienced partner/coach can help you in these situations. In general, it is sporadic for a company to have internally experienced PLM implementers as it is not their core business to implement PLM. Experienced PLM implementers vary from size and skills – make the right choice.
Experience: When you plan to implement PLM “big” with a toolkit approach, experience becomes crucial as initial design decisions and scope are significant for future extensions and maintainability. Beautiful implementations can become a burden after five years as design decisions were not documented or analyzed. Having experience or an experienced partner/coach can help you in these situations. In general, it is sporadic for a company to have internally experienced PLM implementers as it is not their core business to implement PLM. Experienced PLM implementers vary from size and skills – make the right choice.
Conclusion
After writing this post, I still cannot write a final verdict from my side what is the best approach. Personally, I like the PLM toolkit approach as I have been working in the PLM domain for twenty years seeing and experiencing good and best practices. The OOTB-box approach represents many of these best practices and therefore are a safe path to follow. The undecisive points are who are the people involved and what is your business model. It needs to be an end-to-end coherent approach, no matter which option you choose.
 A week ago I attended the joined CIMdata Roadmap and PDT Europe conference in Stuttgart as you can recall from last week’s post: The weekend after CIMdata Roadmap / PDT Europe 2018. As there was so much information to share, I had to split the report into two posts. This time the focus on the PDT Europe. In general, the PDT conferences have always been focusing on sharing experiences and developments related to standards. A topic you will not see at PLM Vendor conferences. Therefore, your chance to learn and take part if you believe in standards.
A week ago I attended the joined CIMdata Roadmap and PDT Europe conference in Stuttgart as you can recall from last week’s post: The weekend after CIMdata Roadmap / PDT Europe 2018. As there was so much information to share, I had to split the report into two posts. This time the focus on the PDT Europe. In general, the PDT conferences have always been focusing on sharing experiences and developments related to standards. A topic you will not see at PLM Vendor conferences. Therefore, your chance to learn and take part if you believe in standards.
This year’s theme: Collaboration in the Engineering and Manufacturing Supply Chain – the Extended Digital Thread and Smart Manufacturing. Industry 4.0 plays a significant role here.
Model-based X: What is it and what is the status?
 I have seen Peter Bilello presenting this topic now several times, and every time there is a little more progress. The fact that there is still an acronym war illustrated that the various aspects of a model-based approach are not yet defined. Some critics will be stating that’s because we do not need model-based and it is only a vendor marketing trick again. Two comments here:
I have seen Peter Bilello presenting this topic now several times, and every time there is a little more progress. The fact that there is still an acronym war illustrated that the various aspects of a model-based approach are not yet defined. Some critics will be stating that’s because we do not need model-based and it is only a vendor marketing trick again. Two comments here:
- If you want to implement an end-to-end model-based approach including your customers and supply chain, you cannot avoid standard. More will become clear when you read the rest of this post. Vendors will not promote standards as it reduces their capabilities to deliver unique So standards must come from the market, not from the marketing.
- In 2007 Carl Bass, at that time CEO at Autodesk made his statement: “There are only three customers in the world that have a PLM problem; Dassault, PTC, and There are no other companies that say I have a PLM problem”. Have a look here. PLM is understood by now and even by Autodesk. The statement illustrates that in the beginning the PLM target was not clear and people thought PLM was a system instead of a strategic approach. Model-based ways of working have to go through the same learning path, hopefully, faster.
Peter’s presentation was a good walk-through pointing out what exists, where we focus and that there is still working to be done. Not by vendors but by companies. Therefore I wholeheartedly agree with Peter’s closing remarks – no time to sit back and watch if you want to benefit from model-based approaches.

Smart Manufacturing
Kenny Swope, known from his presentations related to Boeing, now spoke to us as the Chair of the ISO/TC 184/SC 4 workgroup related to Industrial Data. To say it in decoded mode: Kenny is heading Sub-committee 4 with a focus on Industrial Data. SC4 is part of a more prominent theme: Automation Systems and integration identified by TC 184 all as part of the ISO framework. The scope:
Standardization of the content, meaning, structure, representation and quality management of the information required to define an engineered product and its characteristics at any required level of detail at any part of its lifecycle from conception through disposal, together with the interfaces required to deliver and collect the information necessary to support any business or technical process or service related to that engineered product during its lifecycle.
Perhaps boring to read if you think about all the demos you have seen at trade shows related to Smart Manufacturing. If you want these demos to become true in a vendor-independent environment, you will need to agree on a common framework of definitions to ensure future continuity beyond the demo. And here lies the business excitement, the real competitive advantages companies can have implementing Smart Manufacturing in a Scaleable, future-oriented way.
One of the often heard statements is that standards are too slow or incomplete. Incomplete is not a problem when there is a need, the standard will follow. Compare it with language, we will always invent new words for new concepts.
Being slow might be the case in the past. Kenny showed the relative fast convergence from country-specific Smart Manufacturing standards into a joined ISO/IEC framework – all within three years. ISO and IEC have been teaming-up already to build Smart Manufacturing Reference models.
This is already a considerable effort, as the local reference models need to be studied and mapped to a common architecture. The target is to have a first Technical Specification for a joint standard final 2020 – quite fast!
 Meinolf Gröpper from the German VDMA presented what they are doing to support Smart Manufacturing / Industrie 4.0. The VDMA is a well-known engineering federation with 3200 member companies, 85 % of them are Small and Medium Enterprises – the power of the German economy.
Meinolf Gröpper from the German VDMA presented what they are doing to support Smart Manufacturing / Industrie 4.0. The VDMA is a well-known engineering federation with 3200 member companies, 85 % of them are Small and Medium Enterprises – the power of the German economy.
The VDMA provides networking capabilities, readiness assessments for members to be the enabler for companies to transform. As Meinolf stated Industrie 4.0 is not about technology, it is about cross-border services and international cooperation. A strategy that every company has to develop and if possible implement at its own pace. Standards will accelerate the implementation of Industrie 4.0
The Smart Manufacturing session was concluded by Gunilla Sivard, Professor at KTH in Stockholm and Hampus Wranér, Consultant at Eurostep. They presented the work done on the DIgln project, targeting an infrastructure for Smart Manufacturing.
The presentation showed the implementation of the testbed using twittering bus communication and the ISO 10303-239 PLCS information standard as the persistent layer. The results were promising to further build capabilities on top of the infrastructure below:
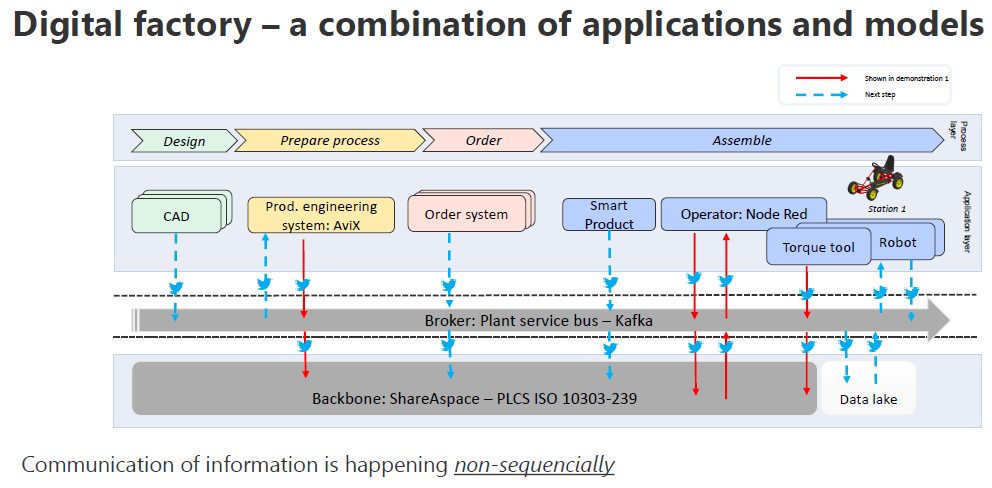 The conclusion from the Smart Manufacturing session was that emerging and available standards can accelerate the deployment.
The conclusion from the Smart Manufacturing session was that emerging and available standards can accelerate the deployment.
Enabling digital continuity in the Factory of the Future
Alcibiades Gonzalez-Noval from Airbus shared challenges and the strategy for Airbus’s factory of the future based on digital continuity from the virtual world towards the physical world, connecting with PLM, ERP, and MOM. Concepts many companies are currently working on with various maturity stages.
 I agree with his lessons learned. We cannot think in silos anymore in a digital future – everything is connected. And please forget the PoC, to gain time start piloting and fail or succeed fast. Companies have lost years because of just doing PoCs and not going into action. The last point, networks segregation for sure is an issue, relevant for plant operations. I experienced this also in the past when promoting PLM concepts for (nuclear) owners/operators of plants. Network security is for sure an issue to resolve.
I agree with his lessons learned. We cannot think in silos anymore in a digital future – everything is connected. And please forget the PoC, to gain time start piloting and fail or succeed fast. Companies have lost years because of just doing PoCs and not going into action. The last point, networks segregation for sure is an issue, relevant for plant operations. I experienced this also in the past when promoting PLM concepts for (nuclear) owners/operators of plants. Network security is for sure an issue to resolve.
Cross-Discipline Lifecycle Collaboration Forum
Setting up the digital thread across engineering and the value chain.
Peter Gerber, Chairman of CDLC Forum and Data Exchange & Integration Leader at Schaefller and Pierre Bodin at Senior Manager Mews Partners, presented their findings related to the challenge of managing complex products (mechanical, electrical, software using system engineering methodology) to work properly at affordable cost in a real-time mode, multidisciplinary and coordination across the whole value chain. Something you might expect could be done when reviewing all PLM Vendor’s marketing materials, something you might expect hard to do when remembering Martin Eigner’s statement that 95 % of the companies have not solved mechatronics collaboration yet. (See: The weekend after CIMdata PLM Roadmap and PDT Europe)

A demonstrator was defined, and various vendors participated in building a demonstrator based on their Out-Of-The-Box capabilities. The result showed that for all participants there were still gaps to resolve for full collaboration. A new version of the demonstrator is now planned for the middle of next year – curious to learn the results at that time. Multi-disciplinary collaboration is a (conceptual) pillar for future digital business – it needs to be possible.
A Digital Thread based on the PLCS standard.
![]() Nigel Shaw, Eurostep’s managing director in the UK, took us through his evolution of PLCS (Product Life Cycle Support) and extension of the ISO 10303 STEP standard. (STEP Standard for Exchange of Product data). Nigel mentioned how over all these years, millions (and a lot of brain power) have been invested in PLCS to where it is now.
Nigel Shaw, Eurostep’s managing director in the UK, took us through his evolution of PLCS (Product Life Cycle Support) and extension of the ISO 10303 STEP standard. (STEP Standard for Exchange of Product data). Nigel mentioned how over all these years, millions (and a lot of brain power) have been invested in PLCS to where it is now.
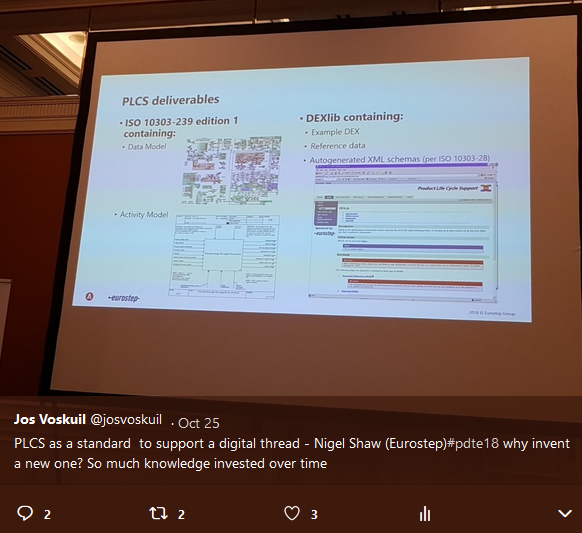 PLCS has been extremely useful as an interface standard for contracting, provide product data in a neutral way. As an example, last year the Swedish Defense organization (FMV) and France’s DGA made PLCS DEXs as part of the contractual conditions. It would be too costly to have all product data for all defense systems in proprietary vendor formats and this over the product lifecycle.
PLCS has been extremely useful as an interface standard for contracting, provide product data in a neutral way. As an example, last year the Swedish Defense organization (FMV) and France’s DGA made PLCS DEXs as part of the contractual conditions. It would be too costly to have all product data for all defense systems in proprietary vendor formats and this over the product lifecycle.
Those following the standards in the process industry will rely on ISO 15926 / CFIHOS as this standard’s dictionary, and data model is more geared to process data- and in particular the exchange of data from the various contractors with the owner/operator.
Coming back to PLCS and the Digital Twin – it is all about digital continuity of information. Otherwise, if we have to recreate information in every lifecycle stage of a product (design/manufacturing / operations), it will be too costly and not digital connected. This illustrates the growing needs for standards. I had nothing to add to Nigel’s conclusions:

It is interesting to note that product management has moved a long way over the last 10-20 years however as we include more and more into PLM, there are all the time new concepts to be solved. The cases we discuss today in our PLM communities were most of the time visions 10 years ago. Nowadays we want to include Model-Based Systems Engineering, 3D Modeling and simulation, electronics and software and even aftermarket, product support in true PLM. This was not the case 20 years ago. The people involved in the development of PLCS were for sure visionaries as product data connectivity along the whole lifecycle is needed and enabled by the standard.
Investing in Industry 4.0?
Hard Realities of the Grand Vision.
![]() Marc Halpern from Gartner is one of the regular speakers at the PDT conference. Unfortunate he could not be with us that day, however, through a labor-intensive connection (mobile phone close to the speaker and Nigel Shaw trying to stay in sync with the presented slides) we could hear Marc speak about what we wanted to achieve too – a digital continuity.
Marc Halpern from Gartner is one of the regular speakers at the PDT conference. Unfortunate he could not be with us that day, however, through a labor-intensive connection (mobile phone close to the speaker and Nigel Shaw trying to stay in sync with the presented slides) we could hear Marc speak about what we wanted to achieve too – a digital continuity.
Marc restated the massive potential of Industrie 4.0 when it comes to scalability, agility, flexibility, and efficiency.
Although technologies are evolving rapidly, it is the existing legacy that inhibits fast adoption. A topic that was also central in my presentation. It is not just a change in technology, there is much more connected.
Marc recommends a changing role for IT, where they should focus more on business priorities and business leadership strategies. This as opposed to the classical role of the IT organization where IT needed to support the business, now they will be part of leading the business too.
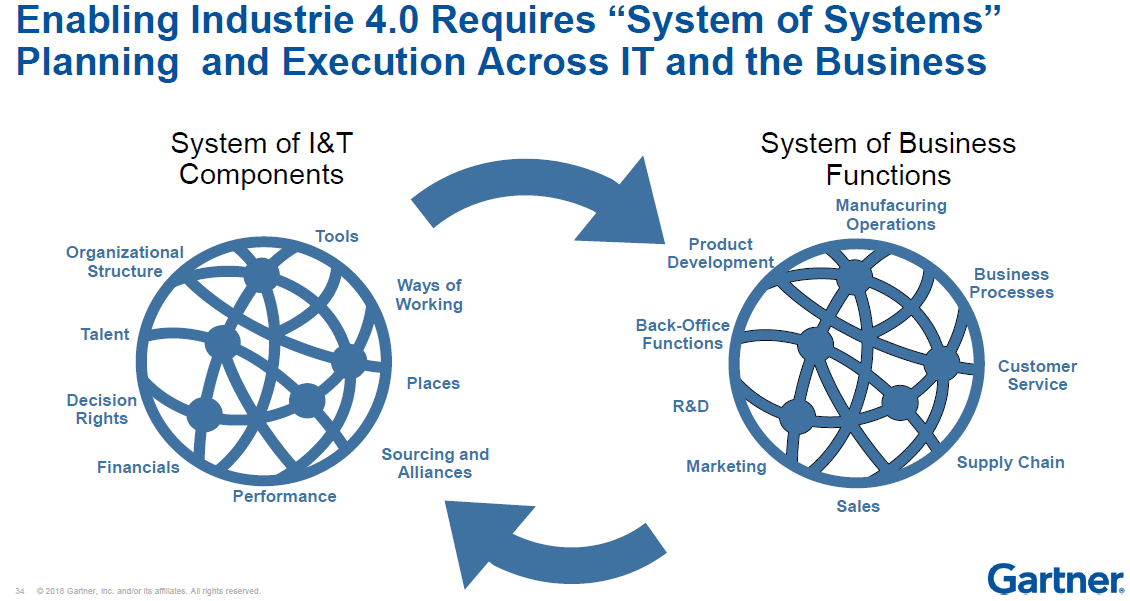 To orchestrate such an IT evolution, Marc recommends a “systems of systems” planning and execution across IT and Business. One of my recent blog posts: Moving to a model-based enterprise: The business (information) model can be seen in that context.
To orchestrate such an IT evolution, Marc recommends a “systems of systems” planning and execution across IT and Business. One of my recent blog posts: Moving to a model-based enterprise: The business (information) model can be seen in that context.
How to deal with the incompatible future?
I was happy to conclude the sessions with the topic that concerns me the most at this time. Companies in their current business are already struggling to get aligned and coordinated between disciplines and external stakeholders, the gap to be connected is vast as it requires a master data management approach, an enterprise data model and model-based ways of working. Read my posts from the past ½ year starting here, and you get the picture.

Note: This image is based on Marc Halpern’s (Gartner) Technology/Maturity diagram from PDT 2015
I concluded with explaining companies need to learn to work in two modes. One mode will be the traditional way of working which I call the coordinated approach and a growing focus on operating in a connected mode. You can see my full presentation here on SlideShare: How to deal with the incompatible future.
Conclusion
The conference was closed with a panel discussion where we shared our concerns related to the challenges companies face to change their traditional ways of working meanwhile entering a digital era. The positive points are there – baby steps – PLM is becoming understood, the significance of standards is becoming more clear. The need: a long-term vision.
This concludes my review of an excellent conference – I learned again a lot and I hope to see you next year too. Thanks again to CIMdata and Eurostep for organizing this event
 Last week I attended the long-awaited joined conference from CIMdata and Eurostep in Stuttgart. As I mentioned in earlier blog posts. I like this conference because it is a relatively small conference with a focused audience related to a chosen theme.
Last week I attended the long-awaited joined conference from CIMdata and Eurostep in Stuttgart. As I mentioned in earlier blog posts. I like this conference because it is a relatively small conference with a focused audience related to a chosen theme.
 Instead of parallel sessions, all attendees follow the same tracks and after two days there is a common understanding for all. This time there were about 70 people discussing the themes: Digitalizing Reality—PLM’s role in enabling the digital revolution (CIMdata) and Collaboration in the Engineering and Manufacturing Supply Chain –the Extended Digital Thread and Smart Manufacturing (EuroStep)
Instead of parallel sessions, all attendees follow the same tracks and after two days there is a common understanding for all. This time there were about 70 people discussing the themes: Digitalizing Reality—PLM’s role in enabling the digital revolution (CIMdata) and Collaboration in the Engineering and Manufacturing Supply Chain –the Extended Digital Thread and Smart Manufacturing (EuroStep)
As you can see all about Digital. Here are my comments:
The State of the PLM Industry:
The Digital Revolution
 Peter Bilello kicked off with providing an overview of the PLM industry. The PLM market showed an overall growth of 7.3 % toward 43.6 Billion dollars. Zooming in into the details cPDM grew with 2.9 %. The significant growth came from the PLM tools (7.7 %). The Digital Manufacturing sector grew at 6.2 %. These numbers show to my opinion that in particular, managing collaborating remains the challenging part for PLM. It is easier to buy tools than invest in cPDM.
Peter Bilello kicked off with providing an overview of the PLM industry. The PLM market showed an overall growth of 7.3 % toward 43.6 Billion dollars. Zooming in into the details cPDM grew with 2.9 %. The significant growth came from the PLM tools (7.7 %). The Digital Manufacturing sector grew at 6.2 %. These numbers show to my opinion that in particular, managing collaborating remains the challenging part for PLM. It is easier to buy tools than invest in cPDM.
Peter mentioned that at the board level you cannot sell PLM as this acronym is too much framed as an engineering tool. Also, people at the board have been trained to interpret transactional data and build strategies on that. They might embrace Digital Transformation. However, the Product innovation related domain is hard to define in numbers. What is the value of collaboration? How do you measure and value innovation coming from R&D? Recently we have seen more simplified approaches how to get more value from PLM. I agree with Peter, we need to avoid the PLM-framing and find better consumable value statements.
Nothing to add to Peter’s closing remarks:

An Alternative View of the Systems Engineering “V”
 For me, the most interesting presentation of Day 1 was Don Farr’s presentation. Don and his Boeing team worked on depicting the Systems Engineering process for a Model-Based environment. The original “V” looks like a linear process and does not reflect the multi-dimensional iterations at various stages, the concept of a virtual twin and the various business domains that need to be supported.
For me, the most interesting presentation of Day 1 was Don Farr’s presentation. Don and his Boeing team worked on depicting the Systems Engineering process for a Model-Based environment. The original “V” looks like a linear process and does not reflect the multi-dimensional iterations at various stages, the concept of a virtual twin and the various business domains that need to be supported.

The result was the diamond symbol above. Don and his team have created a consistent story related to the depicted diamond which goes too far for this blog post. Current the diamond concept is copyrighted by Boeing, but I expect we will see more of this in the future as the classical systems engineering “V” was not design for our model-based view of the virtual and physical products to design AND maintain.
Sponsor vignette sessions
The vignette sponsors of the conference, Aras, ESI,-group, Granta Design, HCL, Oracle and TCS all got a ten minutes’ slot to introduce themselves, and the topics they believed were relevant for the audience. These slots served as a teaser to come to their booth during a break. Interesting for me was Granta Design who are bringing a complementary data service related to materials along the product lifecycle, providing a digital continuity for material information. See below.
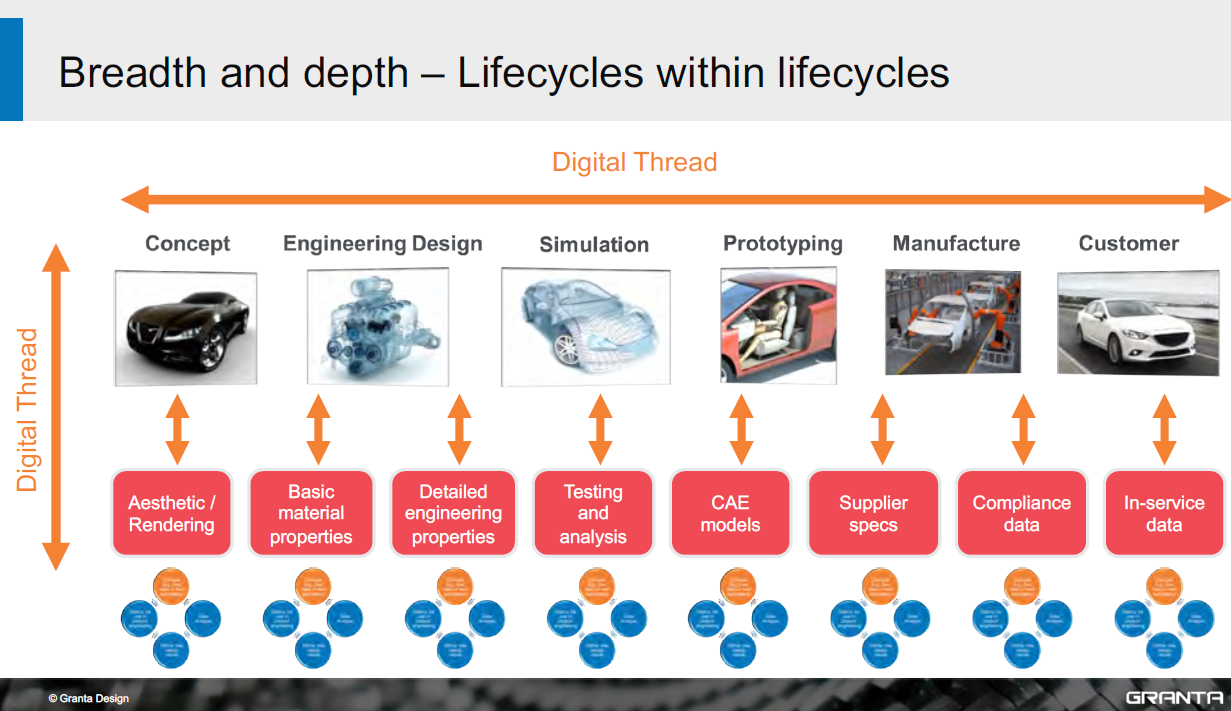
The PLM – CLM Axis vital for Digitalization of Product Process
![]() Mikko Jokela, Head of Engineering Applications CoE, from ABB, completed the morning sessions and left me with a lot of questions. Mikko’s mission is to provide the ABB companies with an information infrastructure that is providing end-to-end digital services for the future, based on apps and platform thinking.
Mikko Jokela, Head of Engineering Applications CoE, from ABB, completed the morning sessions and left me with a lot of questions. Mikko’s mission is to provide the ABB companies with an information infrastructure that is providing end-to-end digital services for the future, based on apps and platform thinking.
Apparently, the digital continuity will be provided by all kind of BOM-structures as you can see below.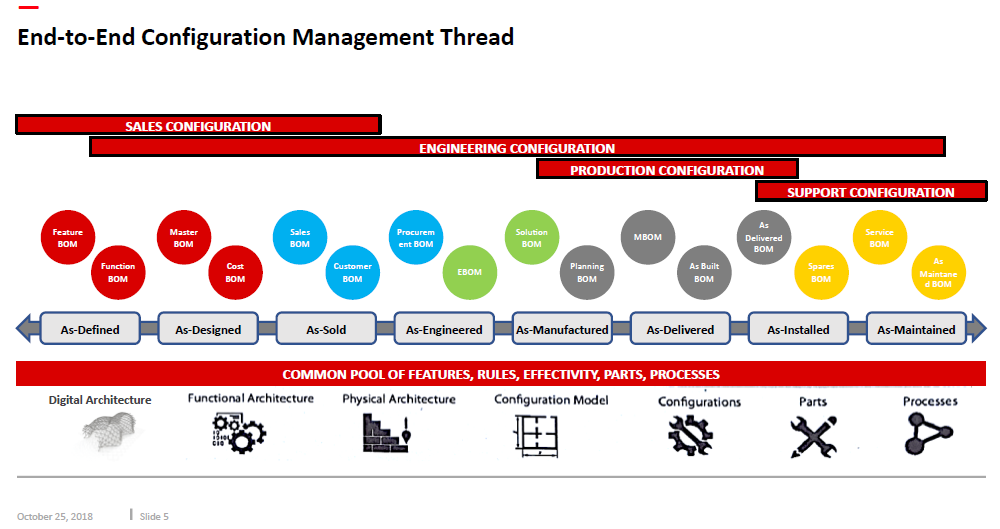 In my post, Coordinated or Connected, related to a model-based enterprise I call this approach a coordinated approach, which is a current best practice, not an approach for the future. There we want a model-based enterprise instead of a BOM-centric approach to ensure a digital thread. See also Don Farr’s diamond. When I asked Mikko which data standard(s) ABB will use to implement their enterprise data model it became clear there was no concept yet in place. Perhaps an excellent opportunity to look at PLCS for the product related schema.
In my post, Coordinated or Connected, related to a model-based enterprise I call this approach a coordinated approach, which is a current best practice, not an approach for the future. There we want a model-based enterprise instead of a BOM-centric approach to ensure a digital thread. See also Don Farr’s diamond. When I asked Mikko which data standard(s) ABB will use to implement their enterprise data model it became clear there was no concept yet in place. Perhaps an excellent opportunity to look at PLCS for the product related schema.
A general comment: Many companies are thinking about building their own platform. Not all will build their platform from scratch. For those starting from scratch have a look at existing standards for your industry. And to manage the quality of data, you will need to implement Master Data Management, where for the product part the PLM system can play a significant role. See Master Data Management and PLM.
Systems of Systems Approach to Product Design
Professor Martin Eigner keynote presentation was about the concepts how new products and markets need a Systems of Systems approach combined with Model-Based Systems Engineering (MBSE) and Product Line Engineering (PLE) where the PLM system can be the backbone to support the MBSE artifacts in context. All these concepts require new ways of working as stated below:
And this is a challenge. A quick survey in the room (and coherent with my observations from the field) is the fact that most companies (95 %) haven’t even achieved to work integrated for mechatronics products. You can imagine the challenge to incorporate also Software, Simulation, and other business disciplines. Martin’s presentations are always an excellent conceptual framework for those who want to dive deeper a start point for discussion and learning.
Additive Manufacturing (Enabled Supply) at Moog
 Moog Inc, a manufacturer of precision motion controls for various industries have made a strategic move towards Additive Manufacturing. Peter Kerl, Moog’s Engineering Systems Manager, gave a good introduction what is meant by Additive Manufacturing and how Moog is introducing Additive Manufacturing in their organization to create more value for their customer base and attract new customers in a less commodity domain. As you can image delivering products through Additive Manufacturing requires new skills (Design / Materials), new processes and a new organizational structure. And of course a new PLM infrastructure.
Moog Inc, a manufacturer of precision motion controls for various industries have made a strategic move towards Additive Manufacturing. Peter Kerl, Moog’s Engineering Systems Manager, gave a good introduction what is meant by Additive Manufacturing and how Moog is introducing Additive Manufacturing in their organization to create more value for their customer base and attract new customers in a less commodity domain. As you can image delivering products through Additive Manufacturing requires new skills (Design / Materials), new processes and a new organizational structure. And of course a new PLM infrastructure.

Jim van Oss, Moog’s PLM Architect and Strategist, explained how they have been involved in a technology solution for digital-enabled parts leveraging blockchain technology. Have a look at their VeriPart trademark. It was interesting to learn from Peter and Jim that they are actively working in a space that according to the Gartner’s hype curve is in the early transform phase. Peter and Jim’s presentation were very educational for the audience.
For me, it was also interesting to learn from Jim that at Moog they were really practicing the modes for PLM in their company. Two PLM implementations, one with the legacy data and the wrong data for the future and one with the new data model for the future. Both implementations build on the same PLM vendor’s release. A great illustration showing the past and the future data for PLM are not compatible
Value Creation through Synergies between PLM & Digital Transformation
![]() Daniel Dubreuil, Safran’s CDO for Products and Services gave an entertaining lecture related to Safran’s PLM journey and the introduction of new digital capabilities, moving from an inward PLM system towards a digital infrastructure supporting internal (model-based systems engineering / multiple BOMs) and external collaboration with their customers and suppliers introducing new business capabilities. Daniel gave a very precise walk-through with examples from the real world. The concluding slide: KEY SUCCESS FACTORS was a slide that we have seen so many times at PLM events.
Daniel Dubreuil, Safran’s CDO for Products and Services gave an entertaining lecture related to Safran’s PLM journey and the introduction of new digital capabilities, moving from an inward PLM system towards a digital infrastructure supporting internal (model-based systems engineering / multiple BOMs) and external collaboration with their customers and suppliers introducing new business capabilities. Daniel gave a very precise walk-through with examples from the real world. The concluding slide: KEY SUCCESS FACTORS was a slide that we have seen so many times at PLM events.

Apparently, the key success factors are known. However, most of the time one or more of these points are not possible to address due to various reasons. Then the question is: How to mitigate this risk as there will be issues ahead?
Bringing all the digital trends together. What’s next?
The day ended with a virtual Fire Place session between Peter Bilello and Martin Eigner, the audience did not see a fireplace however my augmented twitter feed did it for me:

Some interesting observations from this dialogue:
Peter: “Having studied physics is a good base for understanding PLM as you have to model things you cannot see” – As I studied physics I can agree.
Martin: “Germany is the center of knowledge for Mechanical, the US for Electronics and now China becoming the center for Electronics and Software” Interesting observation illustrating where the innovation will come from.
Both Peter and Martin spent serious time on the importance of multidisciplinary education. We are teaching people in silos, faculties work in silos. We all believe these silos must be broken down. It is hard to learn and experiment skills for the future. Where to start and lead?
Conclusion:
The PLM roadmap had some exciting presentations combined with CIMdata’s PLM update an excellent opportunity to learn and discuss reality. In particular for new methodologies and technologies beyond the hype. I want to thank CIMdata for the superb organization and allowing me to take part. Next week I will follow-up with a review of the PDT Europe conference part (Day 2)
In my earlier posts, I explored the incompatibility between current PLM practices and future needs for digital PLM. Digital PLM is one of the terms I am using for future concepts. Actually, in a digital enterprise, system borders become vague, it is more about connected platforms and digital services. Current PLM practices can be considered as Coordinated where the future for PLM is aimed at Connected information. See also Coordinated or Connected.
Moving from current PLM practices toward modern ways of working is a transformation for several reasons.
- First, the scope of current PLM implementation is most of the time focusing on engineering. Digital PLM aims to offer product information services along the product lifecycle.
- Second, because the information in current PLM implementations is mainly stored in documents – drawings still being the leading In advanced PLM implementations BOM-structures, the EBOM and MBOM are information structures, again relying on related specification documents, either CAD- or Office files.
So let’s review the transformation challenges related to moving from current PLM to Digital PLM
Current PLM – document management
The first PLM implementations were most of the time advanced cPDM implementations, targeting sharing CAD models and drawings. Deployments started with the engineering department with the aim to centralize product design information. Integrations with mechanical CAD systems had the major priority including engineering change processes. The multidisciplinary collaboration was enabled by introducing the concept of the Engineering Bill of Materials (EBOM). Every discipline, mechanical, electrical and sometimes (embedded) software teams, linked their information to the EBOM. The product release process was driven by the EBOM. If the EBOM is released, the product is fully specified and can be manufactured.
 Although people complain implementing PLM is complex, this type of implementation is relatively simple. The only added mental effort you are demanding from the PLM user is to work in a structured way and have a more controlled (rigid) way of working compared to a directory structure approach. For many people, this controlled way of working is already considered a limitation of their freedom. However, companies are not profitable because their employees are all artists working in full freedom. They become successful if they can deliver in some efficient way products with consistent quality. In a competitive, global market there is no room anymore for inefficient ways of working as labor costs are adding to the price.
Although people complain implementing PLM is complex, this type of implementation is relatively simple. The only added mental effort you are demanding from the PLM user is to work in a structured way and have a more controlled (rigid) way of working compared to a directory structure approach. For many people, this controlled way of working is already considered a limitation of their freedom. However, companies are not profitable because their employees are all artists working in full freedom. They become successful if they can deliver in some efficient way products with consistent quality. In a competitive, global market there is no room anymore for inefficient ways of working as labor costs are adding to the price.
The way people work in this cPDM environment is coordinated, meaning based on business processes the various stakeholders agree to offer complete sets of information (read: documents) to contribute to the full product definition. If all contributions are consistent depends on the time and effort people spent to verify and validate their consistency. Often this is not done thoroughly and errors are only discovered during manufacturing or later in the field. Costly but accepted as it has always been the case.
Next Step PLM – coordinated document management / item-centric
When the awareness exists that data needs to flow through an organization in a consistent manner, the next step of PLM implementations comes into the picture. Here I would state we are really talking about PLM as the target is to share product data outside the engineering department.

The first logical extension for PLM is moving information from an EBOM view (engineering) toward a Manufacturing Bill of Materials (MBOM) view. The MBOM is aiming to represent the manufacturing definition of the product and becomes a placeholder to link with the ERP system and suppliers directly. Having an integrated EBOM / MBOM process with your ERP system is already a big step forward as it creates an efficient way of working to connect engineering and manufacturing.
As all the information is now related to the EBOM and MBOM, this approach is often called the item-centric approach. The Item (or Part) is the information carrier linked to its specification documents.
Managing the right version of the information in relation to a specific version of the product is called configuration management. And the better you have your configuration management processes in place, the more efficient and with high confidence you can deliver and support your products. Configuration Management is again a typical example where we are talking about a coordinated approach to managing products and documents.
Implementing this type of PLM requires already more complex as it needs different disciplines to agree on a collective process across various (enterprise) systems. ERP integrations are technically not complicated, it is the agreement on a leading process that makes it difficult as the holistic view is often failing.
Next, next step PLM – the Digital Thread
Continuing reading might give you the impression that the next step in PLM evolution is the digital thread. And this can be the case depending on your definition of the digital thread. Oleg Shilovitsky recently published an article: Digital Thread – A new catchy phrase to replace PLM? related to his observations from ConX18 illustrate that there are many viewpoints to this concept. And of course, some vendors promote their perfect fit based on their unique definition. In general, I would classify the idea of Digital Thread in two approaches:
The Digital Thread – coordinated
 In the Digital Thread – coordinated approach we are not revolutionizing the way of working in an enterprise. In the coordinated approach, the PLM environment is connected with another overlay, combining data from various disciplines into an environment where the dependencies are traceable. This can be the Aras overlay approach (here explained by Oleg Shilovitsky), the PTC Navigate approach or others, using a new extra layer to connect the various discipline data and create traceability in a more or less non-intrusive way. Similar concepts, but less intrusive can be done through Business Intelligence applications, although they are more read-only than a system approach.
In the Digital Thread – coordinated approach we are not revolutionizing the way of working in an enterprise. In the coordinated approach, the PLM environment is connected with another overlay, combining data from various disciplines into an environment where the dependencies are traceable. This can be the Aras overlay approach (here explained by Oleg Shilovitsky), the PTC Navigate approach or others, using a new extra layer to connect the various discipline data and create traceability in a more or less non-intrusive way. Similar concepts, but less intrusive can be done through Business Intelligence applications, although they are more read-only than a system approach.
The Digital Thread – connected
In the Digital Thread – connected approach the idea is that information is stored in an extremely granular way and shared among disciplines. Instead of the coordinated way, where every discipline can have its own data sources, here the target is to be data-driven (neutral/standard formats). I described this approach in the various aspects of the model-based enterprise. The challenge of a connected enterprise is the standardized data definition to make it available for all stakeholders.
 Working in a connected enterprise is extremely difficult, in particular for people educated in the old-fashioned ways of working. If you have learned to work with shared documents, like Google Docs or Office documents in sharing mode, you will understand the mental change you have to go through. Continuous sharing of the information instead of waiting until you feel your part is complete.
Working in a connected enterprise is extremely difficult, in particular for people educated in the old-fashioned ways of working. If you have learned to work with shared documents, like Google Docs or Office documents in sharing mode, you will understand the mental change you have to go through. Continuous sharing of the information instead of waiting until you feel your part is complete.
In the software domain, companies are used to working this way and integrating data in a continuous stream. We have to learn to apply these practices also to a complete product lifecycle, where the product consists of hardware and software.
Still, the connect way of working is the vision that digital enterprises should aim for as it dramatically reduces the overhead of information conversion, overhead, and ambiguity. How we will implement in the context of PLM / Product Innovation is a learning process, where we should not be blocked by our echo chamber as Jan Bosch states in his latest post: Don’t Get Stuck In Your Company’s Echo Chamber
 Jan Bosch is coming from the software world, promoting the Software-Centric Systems conference SC2 as a conference to open up your mind. I recommend you to take part in upcoming PLM-related events: CIMdata’s PLM roadmap Europe combined with PDT Europe on 24/25th October in Stuttgart, or if you are living in the US there is the upcoming PI PLMx CHICAGO 2018 on Nov 5/6th.
Jan Bosch is coming from the software world, promoting the Software-Centric Systems conference SC2 as a conference to open up your mind. I recommend you to take part in upcoming PLM-related events: CIMdata’s PLM roadmap Europe combined with PDT Europe on 24/25th October in Stuttgart, or if you are living in the US there is the upcoming PI PLMx CHICAGO 2018 on Nov 5/6th.
Conclusion
Learning and understanding are crucial and take time. A digital transformation has many aspects to learn – keep in mind the difference between coordinated (relatively easy) and connected (extraordinarily challenging but promising). Unfortunately there is no populist way to become digital.
Note:
If you want to continue learning, please read this post – The True Impact of Industry 4.0 Revealed -and its internal links to reference information from Martijn Dullaart – so relevant.

What I want to discuss this time is the challenging transformation related to product data that needs to take place.
 The top image of this post illustrates the current PLM world on the left, and on the right, the potential future positioning of PLM in a digital enterprise. How the right side will behave is still vague – it can be a collection of platforms or a vast collection of small services, all contributing to the performance of the company. Some vendors might dream all these capabilities are defined in one system of systems, like the human body; all functions are available and connected.
The top image of this post illustrates the current PLM world on the left, and on the right, the potential future positioning of PLM in a digital enterprise. How the right side will behave is still vague – it can be a collection of platforms or a vast collection of small services, all contributing to the performance of the company. Some vendors might dream all these capabilities are defined in one system of systems, like the human body; all functions are available and connected.
Coordinated or connected?
This is THE big question for a future digital enterprise. In the current PLM approach, there are governance structures that allow people to share data along the product lifecycle in a structured way.
These governance structures can be project breakdown structures, where with a phase-gate approach, the full delivery is guided. Deliverables related to tasks and gates will make sure information is stored and available for every stakeholder. For example, a well-known process in the automotive industry, the Advanced Product Quality Process ( APQP process) is a standardized approach to make sure parts or products are introduced with the right quality for the customer.
Deliverables at any stage in the process can be reviewed or consumed by another stakeholder. The result is most of the time a collection of approved documents (Office-type, Design & Test files) stored centrally. This is what I would call a coordinated data approach.
In complex environments, besides the project governance, there will be product structures and Bill of Materials, where each object in such a structure will be the placeholder for related information. In case of a product structure it can be its specifications per component, in case of a Bill of Materials, it can be its design specification (usually in CAD models) and its manufacturing specifications, in case of an MBOM.
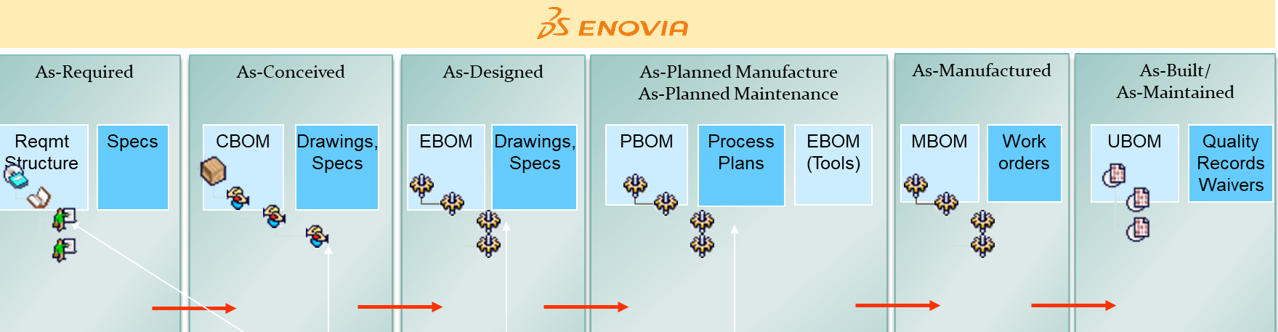
An example of structures used in Enovia
Although these structures contain information about the product composition themselves, the related information makes the content understandable/realizable.
Again it is a coordinated approach, and most PLM systems and implementations are focused on providing these structures.
Sometimes with their own system only – you need to follow the vendor portfolio to get the full benefit or sometimes, the system is positioned as an overlay to existing systems in the company, therefore less invasive.

Presentation from Martin Eigner – explaining the overlay concept based on Aras
Providing a single version of the truth is often associated with this approach. The question is: Is the green bin on the left the single version of the truth?
The Coordinated – Single Version of the Truth – problem
 The challenge of a coordinated approach is that there is no thorough consistency in checking if the data delivered is representing the real truth. Through serious review procedures, we do our best to make sure every deliverable has the required content and quality. As information inside these deliverables is not connected to the outside world, there will be discrepancies between reality and what has been stored. Still, we feel comfortable enough as an organization to pretend we know where the risks are. Until the costly impossible happens!
The challenge of a coordinated approach is that there is no thorough consistency in checking if the data delivered is representing the real truth. Through serious review procedures, we do our best to make sure every deliverable has the required content and quality. As information inside these deliverables is not connected to the outside world, there will be discrepancies between reality and what has been stored. Still, we feel comfortable enough as an organization to pretend we know where the risks are. Until the costly impossible happens!
The connected enterprise
The ultimate dream of a digital enterprise is that everything relevant is connected in context. This means no more documents or files but a very granular information model for linking data and keeping it in context. We can apply algorithms and automation to connected data and use Artificial Intelligence to make sense of massive amounts of data.
 Connected data allows us to share combined sets of information that are relevant to a particular role. Real-time dashboarding is one of the benefits of such an infrastructure. There are still a lot of challenges with this approach. How do we know which information is valid in the context of other information? What are the rules that describe a valid product or project baseline at a particular time?
Connected data allows us to share combined sets of information that are relevant to a particular role. Real-time dashboarding is one of the benefits of such an infrastructure. There are still a lot of challenges with this approach. How do we know which information is valid in the context of other information? What are the rules that describe a valid product or project baseline at a particular time?
Although all data is stored as unique information objects in a network of information, we cannot apply the old mechanisms for a coordinated approach all the time. Generated reports from a connected environment can still serve as baselines or records related to a specific state, such as when the design was approved for manufacturing, we can generate approved Product Baselines structures or Bill of Materials structures.
However, this linearity in the lifecycle for passing information through an enterprise will not exist anymore. It might be there are various design alternatives, and the delivery process is already part of the design phase. Through integrated virtual simulation and testing, we reach a state where the product satisfies the market for that moment, and the delivery process is known at the same time
Almost immediately and based on first experiences in the field, new features can be added virtually, tested and validated for the next stage. We need to design new PLM infrastructures that can support this granularity and, therefore, complexity.
The connected – Single Version of the Truth – problem
 The concepts I described related to the connected enterprise made me realize that this is analog to how the brain works. Our brain is a giant network of connected information, dynamically maintaining associations, having different abstraction levels and always pretending there is one truth.
The concepts I described related to the connected enterprise made me realize that this is analog to how the brain works. Our brain is a giant network of connected information, dynamically maintaining associations, having different abstraction levels and always pretending there is one truth.
If you want to understand a potential model of the brain, please read On Intelligence from Jeff Hawkins. With the possible upcoming of the Quantum Computer, we might be able to create performing brain models.
In my earlier post: Are we blocking our future, I referred to the book; The Idiot Brain: What Your Head is Really Up To from Dean Burnett, where Dean is stating that due to the complexity of stored information, our brain continuously adapts “non-compliant” information to make sure the owner of the brain feels comfortable.
 What we think that is the truth might be just the creation from the brain, combining the positive parts into a compelling story and suppressing or deleting information that does not fit. Although it sounds absurd, I believe if we are able to create a connected digital enterprise, we will face the same symptoms. Due to the complexity of connected information, we are looking for the best suitable version, and as all became so complex, ordinary human beings will no longer be able to distinguish this.
What we think that is the truth might be just the creation from the brain, combining the positive parts into a compelling story and suppressing or deleting information that does not fit. Although it sounds absurd, I believe if we are able to create a connected digital enterprise, we will face the same symptoms. Due to the complexity of connected information, we are looking for the best suitable version, and as all became so complex, ordinary human beings will no longer be able to distinguish this.
Conclusion:
As part of the preparation for the upcoming PDT Europe 2018, I was investigating the topics coordinated and connected enterprises to discover potential transformation steps. We all need to explore the future with an open mind, and the challenge is: WHERE and HOW FAST can we transform from coordinated to connected? I am curious if you have experiences or thoughts on this topic.
 As I am preparing my presentation for the upcoming PDT Europe 2017 conference in Gothenburg, I was reading relevant experiences to a data-driven approach. During PDT Europe conference we will share and discuss the continuous transformation of PLM to support the Lifecycle Model-Based Enterprise.
As I am preparing my presentation for the upcoming PDT Europe 2017 conference in Gothenburg, I was reading relevant experiences to a data-driven approach. During PDT Europe conference we will share and discuss the continuous transformation of PLM to support the Lifecycle Model-Based Enterprise.
One of the direct benefits is that a model-based enterprise allows information to be shared without the need to have documents to be converted to a particular format, therefore saving costs for resources and bringing unprecedented speed for information availability, like what we are used having in a modern digital society.
For me, a modern digital enterprise relies on data coming from different platforms/systems and the data needs to be managed in such a manner that it can serve as a foundation for any type of app based on federated data.
This statement implies some constraints. It means that data coming from various platforms or systems must be accessible through APIs / Microservices or interfaces in an almost real-time manner. See my post Microservices, APIs, Platforms and PLM Services. Also, the data needs to be reliable and understandable for machine interpretation. Understandable data can lead to insights and predictive analysis. Reliable and understandable data allows algorithms to execute on the data.
 Classical ECO/ECR processes can become highly automated when the data is reliable, and the company’s strategy is captured in rules. In a data-driven environment, there will be much more granular data that requires some kind of approval status. We cannot do this manually anymore as it would kill the company, too expensive and too slow. Therefore, the need for algorithms.
Classical ECO/ECR processes can become highly automated when the data is reliable, and the company’s strategy is captured in rules. In a data-driven environment, there will be much more granular data that requires some kind of approval status. We cannot do this manually anymore as it would kill the company, too expensive and too slow. Therefore, the need for algorithms.
What is understandable data?
I tried to avoid as long as possible academic language, but now we have to be more precise as we enter the domain of master data management. I was triggered by this recent post from Gartner: Gartner Reveals the 2017 Hype Cycle for Data Management. There are many topics in the hype cycle, and it was interesting to see Master Data Management is starting to be taken seriously after going through inflated expectations and disillusionment.

This was interesting as two years ago we had a one-day workshop preceding PDT Europe 2015, focusing on Master Data Management in the context of PLM. The attendees at that workshop coming from various companies agreed that there was no real MDM for the engineering/manufacturing side of the business. MDM was more or less hijacked by SAP and other ERP-driven organizations.
Looking back, it is clear to me why in the PLM space MDM was not a real topic at that time. We were still too much focusing and are again too much focusing on information stored in files and documents. The only area touched by MDM was the BOM, and Part definitions as these objects also touch the ERP- and After Sales- domain.
Actually, there are various MDM concepts, and I found an excellent presentation from Christopher Bradley explaining the different architectures on SlideShare: How to identify the correct Master Data subject areas & tooling for your MDM initiative. In particular, I liked the slide below as it comes close to my experience in the process industry

Here we see two MDM architectures, the one of the left driven from ERP. The one on the right could be based on the ISO-15926 standard as the process industry has worked for over 25 years to define a global exchange standard and data dictionary. The process industry was able to reach such a maturity level due to the need to support assets for many years across the lifecycle and the relatively stable environment. Other sectors are less standardized or so much depending on new concepts that it would be hard to have an industry-specific master.
PLM as an Application Specific Master?
 If you would currently start with an MDM initiative in your company and look for providers of MDM solution, you will discover that their values are based on technology capabilities, bringing data together from different enterprise systems in a way the customer thinks it should be organized. More a toolkit approach instead of an industry approach. And in cases, there is an industry approach it is sporadic that this approach is related to manufacturing companies. Remember my observation from 2015: manufacturing companies do not have MDM activities related to engineering/manufacturing because it is too complicated, too diverse, too many documents instead of data.
If you would currently start with an MDM initiative in your company and look for providers of MDM solution, you will discover that their values are based on technology capabilities, bringing data together from different enterprise systems in a way the customer thinks it should be organized. More a toolkit approach instead of an industry approach. And in cases, there is an industry approach it is sporadic that this approach is related to manufacturing companies. Remember my observation from 2015: manufacturing companies do not have MDM activities related to engineering/manufacturing because it is too complicated, too diverse, too many documents instead of data.
Now with modern digital PLM, there is a need for MDM to support the full digital enterprise. Therefore, when you combine the previous observations with a recent post on Engineering.com from Tom Gill: PLM Initiatives Take On Master Data Transformation I started to come to a new hypotheses:
For companies with a model-based approach that has no MDM in place, the implementation of their Product Innovation Platform (modern PLM) should be based on the industry-specific data definition for this industry.
Tom Gill explains in his post the business benefits and values of using the PLM as the source for an MDM approach. In particular, in modern PLM environments, the PLM data model is not only based on the BOM. PLM now encompasses the full lifecycle of a product instead of initially more an engineering view. Modern PLM systems, or as CIMdata calls them Product Innovation Platforms, manage a complex data model, based on a model-driven approach. These entities are used across the whole lifecycle and therefore could be the best start for an industry-specific MDM approach. Now only the industries have to follow….
 Once data is able to flow, there will be another discussion: Who is responsible for which attributes. Bjørn Fidjeland from plmPartner recently wrote: Who owns what data when …? The content of his post is relevant, I only would change the title: Who is responsible for what data when as I believe in a modern digital enterprise there is no ownership anymore – it is about sharing and responsibilities
Once data is able to flow, there will be another discussion: Who is responsible for which attributes. Bjørn Fidjeland from plmPartner recently wrote: Who owns what data when …? The content of his post is relevant, I only would change the title: Who is responsible for what data when as I believe in a modern digital enterprise there is no ownership anymore – it is about sharing and responsibilities
Conclusion
Where MDM in the past did not really focus on engineering data due to the classical document-driven approach, now in modern PLM implementations, the Master Data Model might be based on the industry-specific data elements, managed and controlled coming from the PLM data model
Do you follow my thoughts / agree ?

Hi Jos, Knowing your background in methodology and education, I wanted to share a longer article with you: “What is…
Interesting reflection, Jos. In my experience, the situation you describe is very recognizable. At the company where I work, sustainability…
[…] (The following post from PLM Green Global Alliance cofounder Jos Voskuil first appeared in his European PLM-focused blog HERE.) […]
[…] recent discussions in the PLM ecosystem, including PSC Transition Technologies (EcoPLM), CIMPA PLM services (LCA), and the Design for…
Jos, all interesting and relevant. There are additional elements to be mentioned and Ontologies seem to be one of the…