
You are currently browsing the category archive for the ‘MDM’ category.
 This week I attended the SCAF conference in Jonkoping. SCAF is an abbreviation of the Swedish CATIA User Group. First of all, I was happy to be there as it was a “physical” conference, having the opportunity to discuss topics with the attendees outside the presentation time slot.
This week I attended the SCAF conference in Jonkoping. SCAF is an abbreviation of the Swedish CATIA User Group. First of all, I was happy to be there as it was a “physical” conference, having the opportunity to discuss topics with the attendees outside the presentation time slot.
It is crucial for me as I have no technical message. Instead, I am trying to make sense of the future through dialogues. What is sure is that the future will be based on new digital concepts, completely different from the traditional approach that we currently practice.
 My presentation, which you can find here on SlideShare, was again zooming in on the difference between a coordinated approach (current) and a connected approach (the future).
My presentation, which you can find here on SlideShare, was again zooming in on the difference between a coordinated approach (current) and a connected approach (the future).
The presentation explains the concepts of datasets, which I discussed in my previous blog post. Now, I focussed on how this concept can be discovered in the Dassault Systemes 3DExperience platform, combined with the must-go path for all companies to more systems thinking and sustainable products.
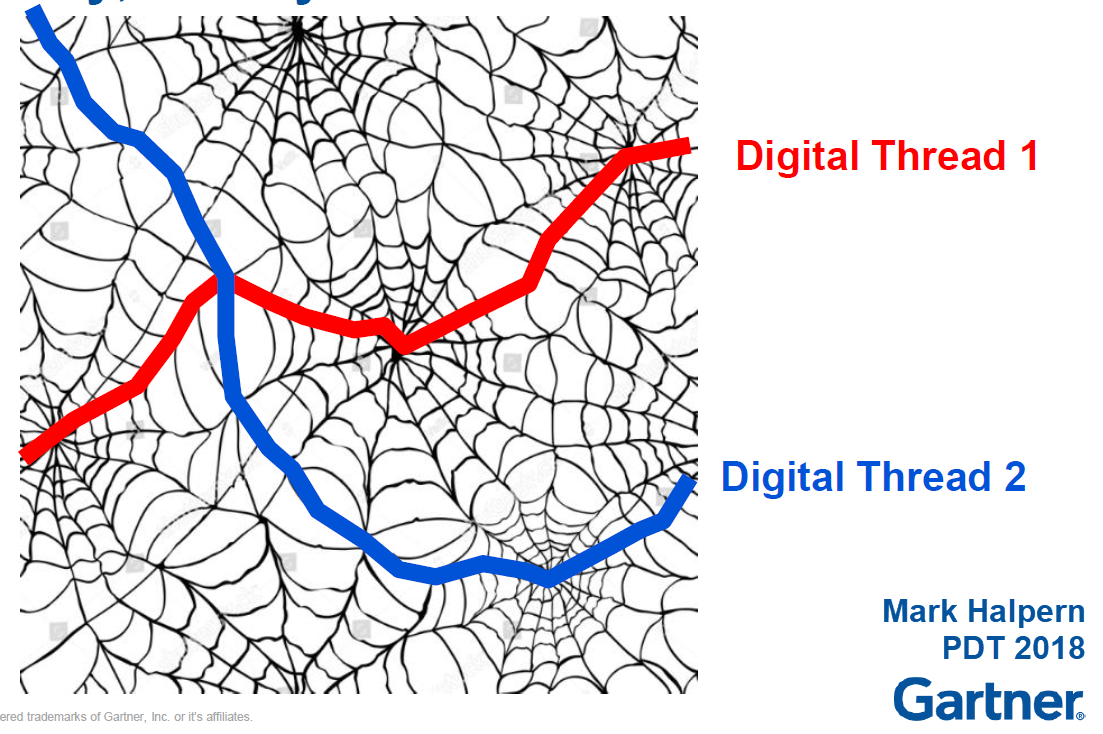 It was interesting to learn that the concept of connected datasets like the spider’s web in the image reflected the future concept for many of the attendees.
It was interesting to learn that the concept of connected datasets like the spider’s web in the image reflected the future concept for many of the attendees.
One of the demos during the conference illustrated that it is no longer about managing the product lifecycle through structures (EBOM/MBOM/SBOM).
Still, it is based on a collection of connected datasets – the path in the spider’s web.
It was interesting to talk with the present companies about their roadmap. How to become a digital enterprise is strongly influenced by their legacy culture and ways of working. Where to start to be connected is the main challenge for all.
 A final positive remark. The SCAF had renamed itself to SCAF (3DX), showing that even CATIA practices no longer can be considered as a niche – the future of business is to be connected.
A final positive remark. The SCAF had renamed itself to SCAF (3DX), showing that even CATIA practices no longer can be considered as a niche – the future of business is to be connected.
Now back to the thread that I am following on the series The road to model-based. Perhaps I should change the title to “The road to connected datasets, using models”. The statement for this week to discuss is:
Data-driven means that you need to have an enterprise architecture, data governance and a master data management (MDM) approach. So far, the traditional PLM vendors have not been active in the MDM domain as they believe their proprietary data model is leading. Read also this interesting McKinsey article: How enterprise architects need to evolve to survive in a digital world
Reliable data
If you have been following my story related to PLM transition: From a connected to a coordinated infrastructure might have seen the image below:

The challenge of a connected enterprise is that you want to connect different datasets, defined in various platforms, to support any type of context. We called this a digital thread or perhaps even better framed a digital web.
 This is new for most organizations because each discipline has been working most of the time in its own silo. They are producing readable information in neutral files – pdf drawings/documents. In cases where a discipline needs to deliver datasets, like in a PDM-ERP integration, we see IT-energy levels rising as integrations are an IT thing, right?
This is new for most organizations because each discipline has been working most of the time in its own silo. They are producing readable information in neutral files – pdf drawings/documents. In cases where a discipline needs to deliver datasets, like in a PDM-ERP integration, we see IT-energy levels rising as integrations are an IT thing, right?
Too much focus on IT
 In particular, SAP has always played the IT card (and is still playing it through their Siemens partnership). Historically, SAP claimed that all parts/items should be in their system. Thus, there was no need for a PDM interface, neglecting that the interface moment was now shifted to the designer in CAD.
In particular, SAP has always played the IT card (and is still playing it through their Siemens partnership). Historically, SAP claimed that all parts/items should be in their system. Thus, there was no need for a PDM interface, neglecting that the interface moment was now shifted to the designer in CAD.
And by using the name Material for what is considered a Part in the engineering world, they illustrated their lack of understanding of the actual engineering world.
There is more to “blame” to SAP when it comes to the PLM domain, or you can state PLM vendors did not yet understand what enterprise data means. Historically ERP systems were the first enterprise systems introduced in a company; they have been leading in a transactional “digital” world. The world of product development never has been a transactional process.
 SAP introduced the Master Data Management for their customers to manage data in heterogeneous environments. As you can imagine, the focus of SAP MDM was more on the transactional side of the product (also PIM) than on the engineering characteristics of a product.
SAP introduced the Master Data Management for their customers to manage data in heterogeneous environments. As you can imagine, the focus of SAP MDM was more on the transactional side of the product (also PIM) than on the engineering characteristics of a product.
I have no problem that each vendor wants to see their solution as the center of the world. This is expected behavior. However, when it comes to a single system approach, there is a considerable danger of vendor lock-in, a lack of freedom to optimize your business.
 In a modern digital enterprise (to be), the business processes and value streams should be driving the requirements for which systems to use. I was tempted to write “not the IT capabilities”; however, that would be a mistake. We need systems or platforms that are open and able to connect to other systems or platforms. The technology should be there, and more and more, we realize the future is based on connectivity between cloud solutions.
In a modern digital enterprise (to be), the business processes and value streams should be driving the requirements for which systems to use. I was tempted to write “not the IT capabilities”; however, that would be a mistake. We need systems or platforms that are open and able to connect to other systems or platforms. The technology should be there, and more and more, we realize the future is based on connectivity between cloud solutions.
In one of my first posts (part 2), I referred to five potential platforms for a connected enterprise. Each platform will have its own data model based on its legacy design, allowing it to service its core users in an optimized environment.
 When it comes to interactions between two or more platforms, for example, between PLM and ERP, between PLM and IoT, but also between IoT and ERP or IoT and CRM, these interactions should first be based on identified business processes and value streams.
When it comes to interactions between two or more platforms, for example, between PLM and ERP, between PLM and IoT, but also between IoT and ERP or IoT and CRM, these interactions should first be based on identified business processes and value streams.
The need for Master Data Management
 Defining horizontal business processes and value streams independent of the existing IT systems is the biggest challenge in many enterprises. Historically, we have been thinking around a coordinated way of working, meaning people shifting pieces of information between systems – either as files or through interfaces.
Defining horizontal business processes and value streams independent of the existing IT systems is the biggest challenge in many enterprises. Historically, we have been thinking around a coordinated way of working, meaning people shifting pieces of information between systems – either as files or through interfaces.
In the digital enterprise, the flow should be leading based on the stakeholders involved. Once people agree on the ideal flow, the implementation process can start.
Which systems are involved, and where do we need a connection between the two systems. Is the relationship bidirectional, or is it a push?
 The interfaces need to be data-driven in a digital enterprise; we do not want human interference here, slowing down or modifying the flow. This is the moment Master Data Management and Data Governance comes in.
The interfaces need to be data-driven in a digital enterprise; we do not want human interference here, slowing down or modifying the flow. This is the moment Master Data Management and Data Governance comes in.
When exchanging data, we need to trust the data in its context, and we should be able to use the data in another context. But, unfortunately, trust is hard to gain.
I can share an example of trust when implementing a PDM system linked to a Microsoft-friendly ERP system. Both systems we able to have Excel as an interface medium – the Excel columns took care of the data mapping between these two systems.
 In the first year, engineers produced the Excel with BOM information and manufacturing engineering imported the Excel into their ERP system. After a year, the manufacturing engineers proposed to automatically upload the Excel as they discovered the exchange process did not need their attention anymore – they learned to trust the data.
In the first year, engineers produced the Excel with BOM information and manufacturing engineering imported the Excel into their ERP system. After a year, the manufacturing engineers proposed to automatically upload the Excel as they discovered the exchange process did not need their attention anymore – they learned to trust the data.
How often have you seen similar cases in your company where we insist on a readable exchange format?
When you trust the process(es), you can trust the data. In a digital enterprise, you must assume that specific datasets are used or consumed in different systems. Therefore a single data mapping as in the Excel example won’t be sufficient
Master Data Management and standards?
 Some traditional standards, like the ISO 15926 or ISO 10303, have been designed to exchange process and engineering data – they are domain-specific. Therefore, they could simplify your master data management approach if your digitalization efforts are in that domain.
Some traditional standards, like the ISO 15926 or ISO 10303, have been designed to exchange process and engineering data – they are domain-specific. Therefore, they could simplify your master data management approach if your digitalization efforts are in that domain.
 To connect other types of data, it is hard to find a global standard that also encompasses different kinds of data or consumers. Think about the GS1 standard, which has more of a focus on the consumer-side of data management. When PLM meets PIM, this standard and Master Data Management will be relevant.
To connect other types of data, it is hard to find a global standard that also encompasses different kinds of data or consumers. Think about the GS1 standard, which has more of a focus on the consumer-side of data management. When PLM meets PIM, this standard and Master Data Management will be relevant.
Therefore I want to point to these two articles in this context:
 How enterprise architects need to evolve to survive in a digital world focusing on the transition of a coordinated enterprise towards a connected enterprise from the IT point of view. And a recent LinkedIn post, Web Ontology Language as a common standard language for Engineering Networks? by Matthias Ahrens exploring the concepts I have been discussing in this post.
How enterprise architects need to evolve to survive in a digital world focusing on the transition of a coordinated enterprise towards a connected enterprise from the IT point of view. And a recent LinkedIn post, Web Ontology Language as a common standard language for Engineering Networks? by Matthias Ahrens exploring the concepts I have been discussing in this post.
To me, it seems that standards are helpful when working in a coordinated environment. However, in a connected environment, we have to rely on master data management and data governance processes, potentially based on a clever IT infrastructure using graph databases to be able to connect anything meaningful and possibly artificial intelligence to provide quality monitoring.
Conclusion
Standards have great value in exchange processes, which happen in a coordinated business environment. To benefit from a connected business environment, we need an open and flexible IT infrastructure supported by algorithms (AI) to guarantee quality. Before installing the IT infrastructure, we should first have defined the value streams it should support.
What are your experiences with this transition?
My previous post introducing the concept of connected platforms created some positive feedback and some interesting questions. For example, the question from Maxime Gravel:
Thank you, Jos, for the great blog. Where do you see Change Management tool fit in this new Platform ecosystem?
is one of the questions I try to understand too. You can see my short comment in the comments here. However, while discussing with other experts in the CM-domain, we should paint the path forward. Because if we cannot solve this type of question, the value of connected platforms will be disputable.
 It is essential to realize that a digital transformation in the PLM domain is challenging. No company or vendor has the perfect blueprint available to provide an end-to-end answer for a connected enterprise. In addition, I assume it will take 10 – 20 years till we will be familiar with the concepts.
It is essential to realize that a digital transformation in the PLM domain is challenging. No company or vendor has the perfect blueprint available to provide an end-to-end answer for a connected enterprise. In addition, I assume it will take 10 – 20 years till we will be familiar with the concepts.
It takes a generation to move from drawings to 3D CAD. It will take another generation to move from a document-driven, linear process to data-driven, real-time collaboration in an iterative manner. Perhaps we can move faster, as the Automotive, Aerospace & Defense, and Industrial Equipment industries are not the most innovative industries at this time. Other industries or startups might lead us faster into the future.
![]() Although I prefer discussing methodology, I believe before moving into that area, I need to clarify some more technical points before moving forward. My apologies for writing it in such a simple manner. This information should be accessible for the majority of readers.
Although I prefer discussing methodology, I believe before moving into that area, I need to clarify some more technical points before moving forward. My apologies for writing it in such a simple manner. This information should be accessible for the majority of readers.
What means data-driven?
 I often mention a data-driven environment, but what do I mean precisely by that. For me, a data-driven environment means that all information is stored in a dataset that contains a single aspect of information in a standardized manner, so it becomes accessible by outside tools.
I often mention a data-driven environment, but what do I mean precisely by that. For me, a data-driven environment means that all information is stored in a dataset that contains a single aspect of information in a standardized manner, so it becomes accessible by outside tools.
A document is not a dataset, as often it includes a collection of datasets. Most of the time, the information it is exposed to is not standardized in such a manner a tool can read and interpret the exact content. We will see that a dataset needs an identifier, a classification, and a status.
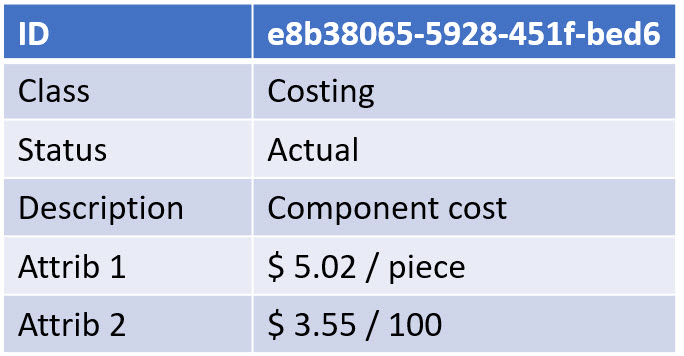 An identifier to be able to create a connection between other datasets – traceability or, in modern words, a digital thread.
An identifier to be able to create a connection between other datasets – traceability or, in modern words, a digital thread.
A classification as the classification identifier will determine the type of information the dataset contains and potential a set of mandatory attributes
A status to understand if the dataset is stable or still in work.
Examples of a data-driven approach – the item
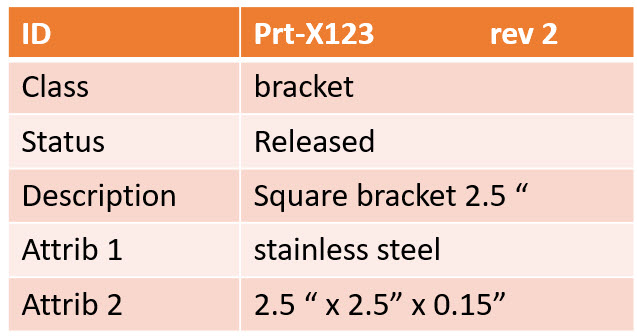 The most common dataset in the PLM world is probably the item (or part) in a Bill of Material. The identifier is the item number (ID + revision if revisions are used). Next, the classification will tell you the type of part it is.
The most common dataset in the PLM world is probably the item (or part) in a Bill of Material. The identifier is the item number (ID + revision if revisions are used). Next, the classification will tell you the type of part it is.
Part classification can be a topic on its own, and every industry has its taxonomy.
Finally, the status is used to identify if the dataset is shareable in the context of other information (released, in work, obsolete), allowing tools to expose only relevant information.
 In a data-driven manner, a part can occur in several Bill of Materials – an example of a single definition consumed in other places.
In a data-driven manner, a part can occur in several Bill of Materials – an example of a single definition consumed in other places.
When the part information changes, the accountable person has to analyze the relations to the part, which is easy in a data-driven environment. It is normal to find this functionality in a PDM or ERP system.
 When the part would change in a document-driven environment, the effort is much higher.
When the part would change in a document-driven environment, the effort is much higher.
First, all documents need to be identified where this part occurs. Then the impact of change needs to be managed in document versions, which will lead to other related changes if you want to keep the information correct.
Examples of a data-driven approach – the requirement
 Another example illustrating the benefits of a data-driven approach is implementing requirements management, where requirements become individual datasets. Often a product specification can contain hundreds of requirements, addressing the needs of different stakeholders.
Another example illustrating the benefits of a data-driven approach is implementing requirements management, where requirements become individual datasets. Often a product specification can contain hundreds of requirements, addressing the needs of different stakeholders.
In addition, several combinations of requirements need to be handled by other disciplines, mechanical, electrical, software, quality and legal, for example.
 As requirements need to be analyzed and ranked, a specification document would never be frozen. Trade-off analysis might lead to dropping or changing a single requirement. It is almost impossible to manage this all in a document, although many companies use Excel. The disadvantages of Excel are known, in particular in a dynamic environment.
As requirements need to be analyzed and ranked, a specification document would never be frozen. Trade-off analysis might lead to dropping or changing a single requirement. It is almost impossible to manage this all in a document, although many companies use Excel. The disadvantages of Excel are known, in particular in a dynamic environment.
The advantage of managing requirements as datasets is that they can be grouped. So, for example, they can be pushed to a supplier (as a specification).
Or requirements could be linked to test criteria and test cases, without the need to manage documents and make sure you work with them last updated document.
![]() As you will see, also requirements need to have an Identifier (to manage digital relations), a classification (to allow grouping) and a status (in work / released /dropped)
As you will see, also requirements need to have an Identifier (to manage digital relations), a classification (to allow grouping) and a status (in work / released /dropped)
Data-driven and Models – the 3D CAD model

3D PDF Model
When I launched my series related to the model-based approach in 2018, the first comments I got came from people who believed that model-based equals the usage of 3D CAD models – see Model-based – the confusion. 3D Models are indeed an essential part of a model-based infrastructure, as the 3D model provides an unambiguous definition of the physical product. Just look at how most vendors depict the aspects of a virtual product using 3D (wireframe) models.
Although we use a 3D representation at each product lifecycle stage, most companies do not have a digital continuity for the 3D representation. Design models are often too heavy for visualization and field services support. The connection between engineering and manufacturing is usually based on drawings instead of annotated models.
I wrote about modern PLM and Model-Based Definition, supported by Jennifer Herron from Action Engineering – read the post PLM and Model-Based Definition here.

If your company wants to master a data-driven approach, this is one of the most accessible learning areas. You will discover that connecting engineering and manufacturing requires new technology, new ways of working and much more coordination between stakeholders.
Implementing Model-Based Definition is not an easy process. However, it is probably one of the best steps to get your digital transformation moving. The benefits of connected information between engineering and manufacturing have been discussed in the blog post PLM and Model-Based Definition
 Essential to realize all these exciting capabilities linked to Industry 4.0 require a data-driven, model-based connection between engineering and manufacturing.
Essential to realize all these exciting capabilities linked to Industry 4.0 require a data-driven, model-based connection between engineering and manufacturing.
If this is not the case, the projected game-changers will not occur as they become too costly.
Data-driven and mathematical models
To manage complexity, we have learned that we have to describe the behavior in models to make logical decisions. This can be done in an abstract model, purely based on mathematical equations and relations. For example, suppose you look at climate models, weather models or COVID infections models.
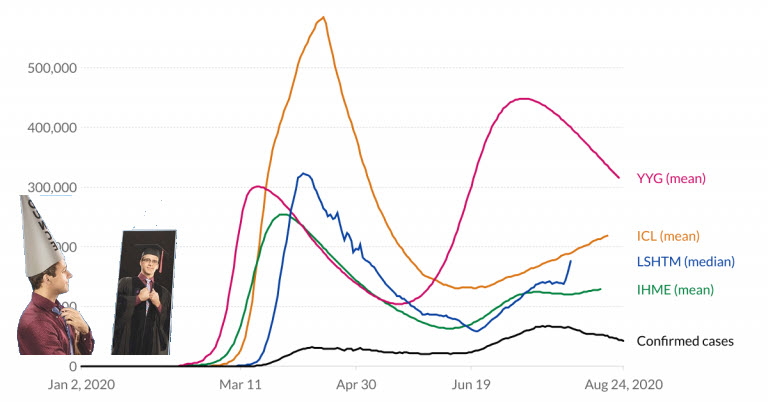
In that case, we see they all lead to discussions from so-called experts that believe a model should be 100 % correct and any exception shows the model is wrong.
It is not that the model is wrong; the expectations are false.
For less complex systems and products, we also use models in the engineering domain. For example, logical models and behavior models are all descriptive models that allow people to analyze the behavior of a product.
 For example, how software code impacts the product’s behavior. Usually, we speak about systems when software is involved, as the software will interact with the outside world.
For example, how software code impacts the product’s behavior. Usually, we speak about systems when software is involved, as the software will interact with the outside world.
There can be many models related to a product, and if you want to get an impression, look at this page from the SEBoK wiki: Types of Models. The current challenge is to keep the relations between these models by sharing parameters.
 The sharable parameters then again should be datasets in a data-driven environment. Using standardized diagrams, like SysML or UML, enables the used objects in the diagram to become datasets.
The sharable parameters then again should be datasets in a data-driven environment. Using standardized diagrams, like SysML or UML, enables the used objects in the diagram to become datasets.
I will not dive further into the modeling details as I want to remain at a high level.
Essential to realize digital models should connect to a data-driven infrastructure by sharing relevant datasets.
What does data-driven imply?
I want to conclude this time with some statements to elaborate on further in upcoming posts and discussions
- Data-driven does not imply there needs to be a single environment, a single database that contains all information. Like I mentioned in my previous post, it will be about managing connected datasets in a federated manner. It is not anymore about owned the data; it is about access to reliable data.
- Data-driven does not mean we do not need any documents anymore. Read electronic files for documents. Likely, document sets will still be the interface to non-connected entities, suppliers, and regulatory bodies. These document sets can be considered a configuration baseline.
- Data-driven means that we need to manage data in a much more granular manner. We have to look different at data ownership. It becomes more data accountability per role as the data can be used and consumed throughout the product lifecycle.
- Data-driven means that you need to have an enterprise architecture, data governance and a master data management (MDM) approach. So far, the traditional PLM vendors have not been active in the MDM domain as they believe their proprietary data model is leading. Read also this interesting McKinsey article: How enterprise architects need to evolve to survive in a digital world
- A model-based approach with connected datasets seems to be the way forward. Managing data in documents will become inefficient as they cannot contribute to any digital accelerator, like applying algorithms. Artificial Intelligence relies on direct access to qualified data.
- I don’t believe in Low-Code platforms that provide ad-hoc solutions on demand. The ultimate result after several years might be again a new type of spaghetti. On the other hand, standardized interfaces and protocols will probably deliver higher, long-term benefits. Remember: Low code: A promising trend or a Pandora’s Box?
- Configuration Management requires a new approach. The current methodology is very much based on hardware products with labor-intensive change management. However, the world of software products has different configuration management and change procedure. Therefore, we need to merge them in a single framework. Unfortunately, this cannot be the BOM framework due to the dynamics in software changes. An interesting starting point for discussion can be found here: Configuration management of industrial products in PDM/PLM
Conclusion
Again, a long post, slowly moving into the future with many questions and points to discuss. Each of the seven points above could be a topic for another blog post, a further discussion and debate.
After my summer holiday break in August, I will follow up. I hope you will join me in this journey by commenting and contributing with your experiences and knowledge.

 In the series learning from the past to understand the future, we have almost reached the current state of PLM before digitization became visible. In the last post, I introduced the value of having the MBOM preparation inside a PLM-system, so manufacturing engineering can benefit from early visibility and richer product context when preparing the manufacturing process.
In the series learning from the past to understand the future, we have almost reached the current state of PLM before digitization became visible. In the last post, I introduced the value of having the MBOM preparation inside a PLM-system, so manufacturing engineering can benefit from early visibility and richer product context when preparing the manufacturing process.
Does everyone need an MBOM?
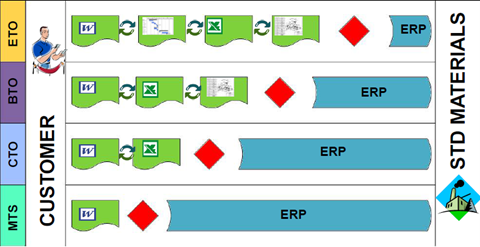 It is essential to realize that you do not need an EBOM and a separate MBOM in case of an Engineering To Order primary process. The target of ETO is to deliver a unique customer product with no time to lose. Therefore, engineering can design with a manufacturing process in mind.
It is essential to realize that you do not need an EBOM and a separate MBOM in case of an Engineering To Order primary process. The target of ETO is to deliver a unique customer product with no time to lose. Therefore, engineering can design with a manufacturing process in mind.
The need for an MBOM comes when:
- You are selling a specific product over a more extended period of time. The engineering definition, in that case, needs to be as little as possible dependent on supplier-specific parts.
- You are delivering your portfolio based on modules. Modules need to be as long as possible stable, therefore independent of where they are manufactured and supplier-specific parts. The better you can define your modules, the more customers you can reach over time.
- You are having multiple manufacturing locations around the world, allowing you to source locally and manufacture based on local plant-specific resources. I described these options in the previous post
 The challenge for all companies that want to move from ETO to BTO/CTO is the fact that they need to change their methodology – building for the future while supporting the past. This is typically something to be analyzed per company on how to deal with the existing legacy and installed base.
The challenge for all companies that want to move from ETO to BTO/CTO is the fact that they need to change their methodology – building for the future while supporting the past. This is typically something to be analyzed per company on how to deal with the existing legacy and installed base.
Configurable EBOM and MBOM
In some previous posts, I mentioned that it is efficient to have a configurable EBOM. This means that various options and variants are managed in the same EBOM-structure that can be filtered based on configuration parameters (date effectivity/version identifier/time baseline). A configurable EBOM is often called a 150 % EBOM
 The MBOM can also be configurable as a manufacturing plant might have almost common manufacturing steps for different product variants. By using the same process and filtered MBOM, you will manufacture the specific product version. In that case, we can talk about a 120 % MBOM
The MBOM can also be configurable as a manufacturing plant might have almost common manufacturing steps for different product variants. By using the same process and filtered MBOM, you will manufacture the specific product version. In that case, we can talk about a 120 % MBOM
Note: the freedom of configuration in the EBOM is generally higher than the options in the configurable MBOM.
The real business change for EBOM/MBOM
So far, we have discussed the EBOM/MBOM methodology. It is essential to realize this methodology only brings value when the organization will be adapted to benefit from the new possibilities. 
One of the recurring errors in PLM implementations is that users of the system get an extended job scope, without giving them the extra time to perform these activities. Meanwhile, other persons downstream might benefit from these activities. However, they will not complain. I realized that already in 2009, I mentioned such a case: Where is my PLM ROI, Mr. Voskuil?
Now let us look at the recommended business changes when implementing an EBOM/MBOM-strategy
- Working in a single, shared environment for engineering and manufacturing preparation is the first step to take.
Working in a PLM-system is not a problem for engineers who are used to the complexity of a PDM-system. For manufacturing engineers, a PLM-environment will be completely new. Manufacturing engineers might prepare their bill of process first in Excel and ultimately enter the complete details in their ERP-system. ERP-systems are not known for their user-friendliness. However, their interfaces are often so rigid that it is not difficult to master the process. Excel, on the other side, is extremely flexible but not connected to anything else.
 And now, this new PLM-system requires people to work in a more user-friendly environment with limited freedom. This is a significant shift in working methodology. This means manufacturing engineers need to be trained and supported over several months. Changing habits and keep people motivated takes energy and time. In reality, where is the budget for these activities? See my 2016 post: PLM and Cultural Change Management – too expensive?
And now, this new PLM-system requires people to work in a more user-friendly environment with limited freedom. This is a significant shift in working methodology. This means manufacturing engineers need to be trained and supported over several months. Changing habits and keep people motivated takes energy and time. In reality, where is the budget for these activities? See my 2016 post: PLM and Cultural Change Management – too expensive?
- From sequential to concurrent
Once your manufacturing engineers are able to work in a PLM-environment, they are able to start the manufacturing definition before the engineering definition is released. Manufacturing engineers can participate in design reviews having the information in their environment available. They can validate critical manufacturing steps and discuss with engineers potential changes that will reduce the complexity or cost for manufacturing. As these changes will be done before the product is released, the cost of change is much lower. After all, having engineering and manufacturing working partially in parallel will reduce time to market.
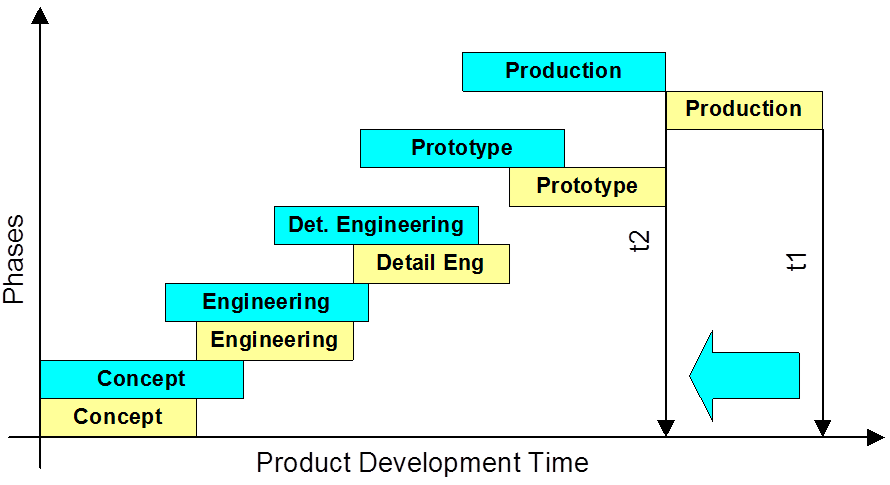
Reducing time to market by concurrent engineering
One of the leading business drivers for many companies is introducing products or enhancements to the market. Bringing engineering and manufacturing preparation together also means that the PLM-system can no longer be an engineering tool under the responsibility of the engineering department.
 The responsibility for PLM needs to be at a level higher in the organization to ensure well-balanced choices. A higher level in the organization automatically means more attention for business benefits and less attention for functions and features.
The responsibility for PLM needs to be at a level higher in the organization to ensure well-balanced choices. A higher level in the organization automatically means more attention for business benefits and less attention for functions and features.
From technology to methodology – interface issues?
The whole EBOM/MBOM-discussion often has become a discussion related to a PLM-system and an ERP-system. Next, the discussion diverted to how these two systems could work together, changing the mindset to the complexity of interfaces instead of focusing on the logical flow of information.
 In an earlier PI Event in München 2016, I lead a focus group related to the PLM and ERP interaction. The discussion was not about technology, all about focusing on what is the logical flow of information. From initial creation towards formal usage in a product definition (EBOM/MBOM).
In an earlier PI Event in München 2016, I lead a focus group related to the PLM and ERP interaction. The discussion was not about technology, all about focusing on what is the logical flow of information. From initial creation towards formal usage in a product definition (EBOM/MBOM).
What became clear from this workshop and other customer engagements is that people are often locked in their siloed way of thinking. Proposed information flows are based on system capabilities, not on the ideal flow of information. This is often the reason why a PLM/ERP-interface becomes complicated and expensive. System integrators do not want to push for organizational change, they prefer to develop an interface that adheres to the current customer expectations.
SAP has always been promoting that they do not need an interface between engineering and manufacturing as their data management starts from the EBOM. They forgot to mention that they have a difficult time (and almost no intention) to manage the early ideation and design phase. As a Dutch SAP country manager once told me: “Engineers are resources that do not want to be managed.” This remark says all about the mindset of ERP.

After overlooking successful PLM-implementations, I can tell the PLM-ERP interface has never been a technical issue once the methodology is transparent. A company needs to agree on logical data flow from ideation through engineering towards design is the foundation.
 It is not about owning data and where to store it in a single system. It is about federated data sets that exist in different systems and that are complementary but connected, requiring data governance and master data management.
It is not about owning data and where to store it in a single system. It is about federated data sets that exist in different systems and that are complementary but connected, requiring data governance and master data management.
The SAP-Siemens partnership
In the context of the previous paragraph, the messaging around the recently announced partnership between SAP and Siemens made me curious. Almost everyone has shared an opinion about the partnership. There is a lot of speculation, and many questions were imaginarily answered by as many blog posts in the field. Last week Stan Przybylinski shared CIMdata’s interpretations in a webinar Putting the SAP-Siemens Partnership In Context, which was, in my opinion, the most in-depth analysis I have seen.
For what it is worth, my analysis:
- First of all, the partnership is a merger of slide decks at this moment, aiming to show to a potential customer that in the SAP/Siemens-combination, you find everything you need. A merger of slides does not mean everything works together.

- It is a merger of two different worlds. You can call SAP a real data platform with connected data, where Siemens offering is based on the Teamcenter backbone providing a foundation for a coordinated approach. In the coordinated approach, the data flexibility is lower. For that reason, Mendix is crucial to make Siemens portfolio behave like a connected platform too.
You can read my doubts about having a coordinated and connected system working together (see image above). It was my #1 identified challenge for this decade: PLM 2020 – PLM the next decade (before COVID-19 became a pandemic and illustrated we need to work connected) - The fact that SAP will sell TC PLM and Siemens will sell SAP PPM seems like loser’s statement, meaning our SAP PLM is probably not good enough, or our TC PPM capabilities are not good enough. In reality, I believe they both should remain, and the partnership should work on logical data flows with data residing in two locations – the federated approach. This is how platforms reside next to each other instead of the single black hole.


- The fact that standard interfaces will be developed between the two systems is a subtle sales argument with relatively low value. As I wrote in the “from technology to methodology”-paragraph, the challenges are in the organizational change within companies. Technology is not the issue, although system integrators also need to make a living.
- What I believe makes sense is that both SAP and Siemens, have to realize their Industry 4.0 end-to-end capabilities. It is a German vision now for several years and it is an excellent vision to strive for. Now it is time to build the two platforms working together. This will be a significant technical challenge mainly for Siemens as its foundation is based on a coordinated backbone.
- The biggest challenge, not only for this partnership, is the organizational change within companies that want to build an end-to-end connected solution. In particular, in companies with a vast legacy, the targeted industries by the partnership, the chasm between coordinated legacy data and intended connected data is enormous. Technology will not fix it, perhaps smoothen the pain a little.


Conclusion
With this post, we have reached the foundation of the item-centric approach for PLM, where the EBOM and MBOM are managed in a real-time context. Organizational change is the biggest inhibitor to move forward. The SAP-Siemens partnership is a sales/marketing approach to create a simplified view for the future at C-level discussions.
Let us watch carefully what happens in reality.
Next time potentially the dimension of change management and configuration management in an item-centric approach.
Or perhaps Martijn Dullaart will show us the way before, following up on his tricky poll question
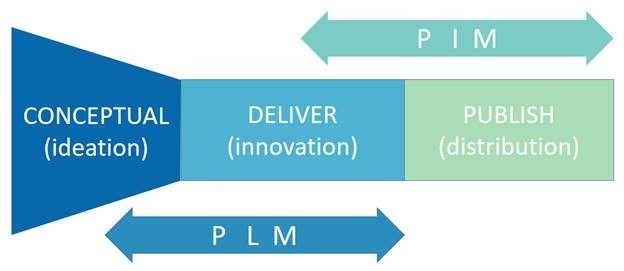 In recent years, more and more PLM customers approached me with questions related to the usage of product information for downstream publishing. To be fair, this is not my area of expertise for the moment. However, with the mindset of a connected enterprise, this topic will come up.
In recent years, more and more PLM customers approached me with questions related to the usage of product information for downstream publishing. To be fair, this is not my area of expertise for the moment. However, with the mindset of a connected enterprise, this topic will come up.
![]() For that reason, I have a strategic partnership with Squadra, a Dutch-based company, providing the same coaching model as TacIT; however, they have their roots in PIM and MDM.
For that reason, I have a strategic partnership with Squadra, a Dutch-based company, providing the same coaching model as TacIT; however, they have their roots in PIM and MDM.
Together we believe we can deliver a meaningful answer on the question: What are the complementary roles of PLM and PIM? In this post, our first joint introduction.
Note: The topic is not new. Already in 2005, Jim Brown from Tech-Clarity published a white-paper: The Complementary Roles of PIM and PLM. This all before digitization and connectivity became massive.
Let’s start with the abbreviations, the TLAs (Three-Letter-Acronyms) and their related domains
PLM – level 1
(Product Lifecycle Management – push)
For PLM, I want to stay close to the current definitions. It is the strategic approach to provide a governance infrastructure to deliver a product to the market. Starting from an early concept phase till manufacturing and in its extended definition also during its operational phase.
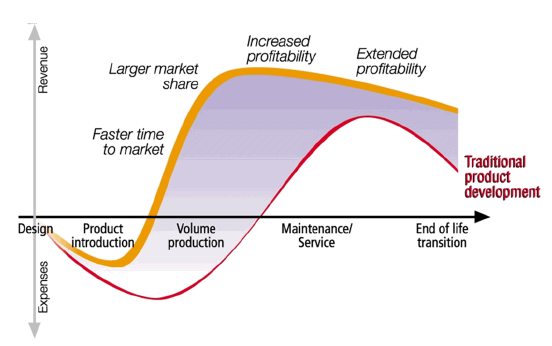 The focus with PLM is to reduce time to market by ensuring quality, cost, and delivery through more and more a virtual product definition, therefore being able to decide upfront for the best design choices, manufacturing options with the lowest cost. In the retail world, own-brand products are creating a need for PLM.
The focus with PLM is to reduce time to market by ensuring quality, cost, and delivery through more and more a virtual product definition, therefore being able to decide upfront for the best design choices, manufacturing options with the lowest cost. In the retail world, own-brand products are creating a need for PLM.
The above image is nicely summarizing the expected benefits of a traditional PLM implementation.
MDM (Master Data Management)
When product data is shared in an enterprise among multiple systems, there is a need for Master Data Management (MDM). Master Data Management focuses on a governance approach that information stored in various systems has the same meaning and shared values where relevant.
 MDM guards and streamlines the way master data is entered, processed, guarded, and changed within the company, resulting in one single version of the truth and enabling different departments and systems to stay synced regarding their crucial data.
MDM guards and streamlines the way master data is entered, processed, guarded, and changed within the company, resulting in one single version of the truth and enabling different departments and systems to stay synced regarding their crucial data.
Interestingly, in the not-so-digital world of PLM, you do not see PLM vendors working on an MDM-approach. They do not care about an end-to-end connected strategy yet. I wrote about this topic in 2017 here: Master Data Management and PLM.
PIM (Product Information Management)
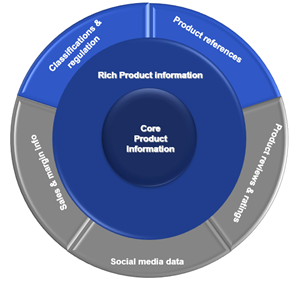 The need for PIM starts to become evident when selling products through various business channels. If you are a specialized machine manufacturer, your product information for potential customers might be very basic and based on a few highlights.
The need for PIM starts to become evident when selling products through various business channels. If you are a specialized machine manufacturer, your product information for potential customers might be very basic and based on a few highlights.
However, due to digitization and global connectivity, product information now becomes crucial to be available in real-time, wherever your customers are in the world.
In a competitive world, with an omnichannel strategy, you cannot survive without having your PIM streamlined and managed.
Product Innovation Platforms (PLM – Level 2 – Pull)
 With the introduction of Product Innovation Platforms as described by CIMdata and Gartner, the borders of PLM, PIM, and MDM might become vague, as they might be all part of the same platform, therefore reducing the immediate need for an MDM-environment. For example, companies like Propel, Stibo, and Oracle are building a joint PLM-PIM portfolio.
With the introduction of Product Innovation Platforms as described by CIMdata and Gartner, the borders of PLM, PIM, and MDM might become vague, as they might be all part of the same platform, therefore reducing the immediate need for an MDM-environment. For example, companies like Propel, Stibo, and Oracle are building a joint PLM-PIM portfolio.
Let’s dive more profound in the two scenarios that we meet the most in business, PLM driving PIM (my comfort zone) and PIM driving the need for PLM (Squadra’s s area of expertise).
PLM driving PIM
 Traditionally PLM (Product Lifecycle Management) has been focusing on several aspects of the product lifecycle. Here is an excellent definition for traditional PLM:
Traditionally PLM (Product Lifecycle Management) has been focusing on several aspects of the product lifecycle. Here is an excellent definition for traditional PLM:
PLM is a collection of best practices, dependent per industry to increase product revenue, reduce product-related costs and maximize the value of the product portfolio (source 2PLM)
This definition shows that PLM is a business strategy, not necessarily a system, but an infrastructure/approach to:
- ensure shorter time to market with the right quality (increasing product revenue)
- efficiently (reduce product-related costs – resources and scrap)
- deliver products that bring the best market revenue (maximize the value of the product portfolio)
The information handled by traditional PLM consists mostly of design data, i.e., specifications, manufacturing drawings, 3D Models, and Bill of Materials (physical part definitions) combined with version and revision management. In elaborate environments combined with processes supporting configuration management.
 PLM data is more focused on internal processes and quality than on targeting the company’s customers. Sometimes the 3D Design data is used as a base to create lightweight 3D graphics for quotations and catalogs, combining it with relevant sales data. Traditional marketing was representing the voice of the customer.
PLM data is more focused on internal processes and quality than on targeting the company’s customers. Sometimes the 3D Design data is used as a base to create lightweight 3D graphics for quotations and catalogs, combining it with relevant sales data. Traditional marketing was representing the voice of the customer.
PLM implementations are more and more providing an enterprise backbone for product data. As a result of this expansion, there is a wish to support sales and catalogs, more efficiently, sharing master data from creation till publishing, combining the product portfolio with sales and service information in a digital way.
In particular, due to globalization, there was a need to make information globally available in different languages without a significant overhead of resources to manage the data or manage the disconnect from the real product data.
 Companies that have realized the need for connected data understood that Product Master Data Management is more than only the engineering/manufacturing view. Product Master Data Management is also relevant to the sales and services view. Historically done by companies as a customized extension on their PLM-system, now more and more interfacing with specialized PIM-systems. Proprietary PLM-PIM interfaces exist. Hopefully, with digital transformation, a more standardized approach will appear.
Companies that have realized the need for connected data understood that Product Master Data Management is more than only the engineering/manufacturing view. Product Master Data Management is also relevant to the sales and services view. Historically done by companies as a customized extension on their PLM-system, now more and more interfacing with specialized PIM-systems. Proprietary PLM-PIM interfaces exist. Hopefully, with digital transformation, a more standardized approach will appear.
PIM driving the need for PLM
Because of changes in the retail market, the need for information in the publishing processes is also changing. Retailers also need to comply with new rules and legislation. The source of the required product information is often in the design process of the product.
 In parallel, there is an ongoing market trend to have more and more private label products in the (wholesale and retail) assortments. This means a growing number of retailers and wholesalers will become producers and will have their own Ideation and innovation process.
In parallel, there is an ongoing market trend to have more and more private label products in the (wholesale and retail) assortments. This means a growing number of retailers and wholesalers will become producers and will have their own Ideation and innovation process.
A good example is ingredients and recipe information in the food retail sector. This information needs to be provided now by suppliers or by their own brand department that owns the design process of the product. Similar to RoHS or REACH compliance in the industry.
Retail and Wholesale can tackle own brands reasonably well with their PIM systems (or Excels), making use of workflows and product statuses. However, over the years, the information demands have increased, and a need for more sophisticated lifecycle management has emerged and, therefore the need for PLM (in this case, PLM also stands for Private Label Management).
In the image below, illustrates a PLM layer and a PIM layer, all leading towards rich product information for the end-users (either B2B or B2C).
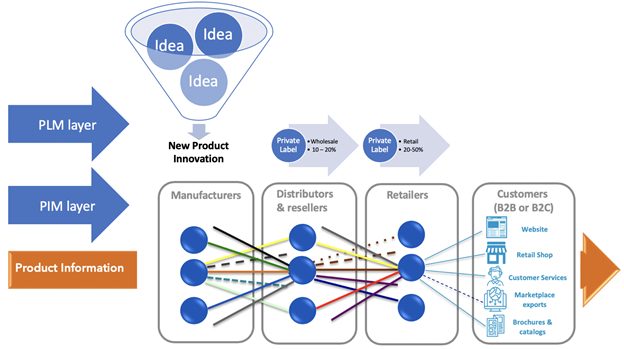
In the fast-moving consumer goods (FMCG) world, most innovative products are coming from manufacturers. They have pipelines with lots of ideas resulting in a limited number of sellable products. In the Wholesale and Retail business, the Private Label development process usually has a smaller funnel but a high pressure on time to market, therefore, a higher need for efficiency in the product data chain.
Technological changes, like 3D Printing, also change the information requirements in the retail and wholesale sectors. 3D printing can be used for creating spare parts on-demand, therefore changing the information flow in processes dramatically. Technical drawings and models that were created in the design process, used for mass production, are now needed in the retail process closer to the end customer.
These examples make it clear that more and more information is needed for publication in the sales process and therefore needs to be present in PIM systems. This information needs to be collected and available during the PLM release process. A seamless connection between the product release and sales processes will support the changing requirements and will reduce errors and rework in on data.
 PLM and PIM are two practices that need to go hand in hand like a relay baton in athletics. Companies that are using both tools must also organize themselves in a way that processes are integrated, and data governance is in place to keep things running smoothly.
PLM and PIM are two practices that need to go hand in hand like a relay baton in athletics. Companies that are using both tools must also organize themselves in a way that processes are integrated, and data governance is in place to keep things running smoothly.
Conclusion
Market changes and digital transformation force us to work in value streams along the whole product lifecycle ensuring quality and time to market. PLM and PIM will be connected domains in the future, to enable smooth product go-to-market. Important is the use of data standards (PLM and PIM should speak a common language) – best based on industry standards so that cross-company communication on product data is possible.
What do you think? Do you see PLM and PIM getting together too, in your business?
Please share in the comments.
At this moment we are in the middle of the year. Usually for me a quiet time and a good time to reflect on what has happened so far and to look forward.
Three themes triggered me to write this half-year:
- The changing roles of (PLM) consultancy
- The disruptive effect of digital transformation on legacy PLM
- The Model-driven approaches
A short summary per theme here with links to the original posts for those who haven’t followed the sequence.
The changing roles of (PLM) consultancy
Triggered by Oleg Shilovitsky’s post Why traditional PLM ranking is dead. PLM ranking 2.0 a discussion started related to the changing roles of PLM choice and the roles of a consultant. Oleg and I agreed that using the word dead in a post title is a way to catch extra attention. And as many people do not read more than the introduction, this is a way to frame ideas (not invented by us, look at your newspaper and social media posts). Please take your time and read this post till the end.
 Oleg and I concluded that the traditional PLM status reports provided by consultancy firms are no longer is relevant. They focus on the big vendors, in a status-quo and most of them are 80 % the same on their core PLM capabilities. The challenge comes in how to select a PLM approach for your company.
Oleg and I concluded that the traditional PLM status reports provided by consultancy firms are no longer is relevant. They focus on the big vendors, in a status-quo and most of them are 80 % the same on their core PLM capabilities. The challenge comes in how to select a PLM approach for your company.
Here Oleg and I differ in opinion. I am more looking at PLM from a business transformation point of view, how to improve your business with new ways of working. The role of a consultant is crucial here as the consultant can help to formalize the company’s vision and areas to focus on for PLM. The value of the PLM consultant is to bring experience from other companies instead of inventing new strategies per company. And yes, a consultant should get paid for this added value.
 Oleg believes more in the bottom-up approach where new technology will enable users to work differently and empower themselves to improve their business (without calling it PLM). More or less concluding there is no need for a PLM consultant as the users will decide themselves about the value of the selected technology. In the context of Oleg’s position as CEO/Co-founder of OpenBOM, it is a logical statement, fighting for the same budget.
Oleg believes more in the bottom-up approach where new technology will enable users to work differently and empower themselves to improve their business (without calling it PLM). More or less concluding there is no need for a PLM consultant as the users will decide themselves about the value of the selected technology. In the context of Oleg’s position as CEO/Co-founder of OpenBOM, it is a logical statement, fighting for the same budget.
The discussion ended during the PLMx conference in Hamburg, where Oleg and I met with an audience recorded by MarketKey. You can find the recording Panel Discussion: Digital Transformation and the Future of PLM Consulting here.
Unfortunate, like many discussions, no conclusion. My conclusion remains the same – companies need PLM coaching !
The related post to this topic are:
The disruptive effect of digital transformation on legacy PLM
A topic that I have discussed the past two years is that current PLM is not compatible with a modern data-driven PLM. Note: data-driven PLM is still “under-development”. Where in most companies the definition of the products is stored in documents / files, I believe that in order to manage the complexity of products, hardware and software in the future, there is a need to organize data related to models not to files. See also: From Item-centric to model-centric ?
 For a company it is extremely difficult to have two approaches in parallel as the first reaction is: “let’s convert the old data to the new environment”.
For a company it is extremely difficult to have two approaches in parallel as the first reaction is: “let’s convert the old data to the new environment”.
This statement has been proven impossible in most of the engagements I am involved in and here I introduced the bimodal approach as a way to keep the legacy going (mode 1) and scale-up for the new environment (mode 2).
A bimodal approach is sometimes acceptable when the PLM software comes from two different vendors. Sometimes this is also called the overlay approach – the old system remains in place and a new overlay is created to connect the legacy PLM system and potentially other systems like ALM or MBSE environments. For example some of the success stories for Aras complementing Siemens PLM.
 Like the bimodal approach the overlay approach creates the illusion that in the near future the old legacy PLM will disappear. I partly share that illusion when you consider the near future a period of 5 – 10+ years depending on the company’s active products. Faster is not realistic.
Like the bimodal approach the overlay approach creates the illusion that in the near future the old legacy PLM will disappear. I partly share that illusion when you consider the near future a period of 5 – 10+ years depending on the company’s active products. Faster is not realistic.
And related to bimodal, I now prefer to use the terminology used by McKinsey: our insights/toward an integrated technology operating model in the context of PLM.
The challenge is that PLM vendors are reluctant to support a bimodal approach for their own legacy PLM as then suddenly this vendor becomes responsible for all connectivity between mode 1 and mode 2 data – every vendors wants to sell only the latest.
I will elaborate on this topic during the PDT Europe conference in Stuttgart – Oct 25th . No posts on this topic this year (yet) as I am discussing, learning and collecting examples from the field. What kept me relative busy was the next topic:
The Model-driven approaches
 Most of my blogging time I spent on explaining the meaning behind a modern model-driven approach and its three main aspects: Model-Based Systems Engineering, Model-Based Definition and Digital Twins. As some of these aspects are still in the hype phase, it was interesting to see the two different opinions are popping up. On one side people claiming the world is still flat (2D), considering model-based approaches just another hype, caused by the vendors. There is apparently no need for digital continuity. If you look into the reactions from certain people, you might come to the conclusion it is impossible to have a dialogue, throwing opinions is not a discussion..
Most of my blogging time I spent on explaining the meaning behind a modern model-driven approach and its three main aspects: Model-Based Systems Engineering, Model-Based Definition and Digital Twins. As some of these aspects are still in the hype phase, it was interesting to see the two different opinions are popping up. On one side people claiming the world is still flat (2D), considering model-based approaches just another hype, caused by the vendors. There is apparently no need for digital continuity. If you look into the reactions from certain people, you might come to the conclusion it is impossible to have a dialogue, throwing opinions is not a discussion..
One of the reasons might be that people reacting strongly have never experienced model-based efforts in their life and just chime in or they might have a business reason not to agree to model-based approached as it does not align with their business? It is like the people benefiting from the climate change theory – will the vote against it when facts are known ? Just my thoughts.
 There is also another group, to which I am connected, that is quite active in learning and formalizing model-based approaches. This in order to move forward towards a digital enterprise where information is connected and flowing related to various models (behavior models, simulation models, software models, 3D Models, operational models, etc., etc.) . This group of people is discussing standards and how to use and enhance them. They discuss and analyze with arguments and share lessons learned. One of the best upcoming events in that context is the joined CIMdata PLM Road Map EMEA and the PDT Europe 2018 – look at the agenda following the image link and you should get involved too – if you really care.
There is also another group, to which I am connected, that is quite active in learning and formalizing model-based approaches. This in order to move forward towards a digital enterprise where information is connected and flowing related to various models (behavior models, simulation models, software models, 3D Models, operational models, etc., etc.) . This group of people is discussing standards and how to use and enhance them. They discuss and analyze with arguments and share lessons learned. One of the best upcoming events in that context is the joined CIMdata PLM Road Map EMEA and the PDT Europe 2018 – look at the agenda following the image link and you should get involved too – if you really care.


And if you are looking into your agenda for a wider, less geeky type of conference, consider the PI PLMx CHICAGO 2018 conference on Nov 5 and 6. The agenda provides a wider range of sessions, however I am sure you can find the people interested in discussing model-based learnings there too, in particular in this context Stream 2: Supporting the Digital Value Chain
My related posts to model-based this year were:
- Model-Based – an introduction
- Why Model-Based? The 3D CAD Model
- Model-Based – The Confusion
- Model-Based: Systems Engineering (MBSE)
- Model-Based – Connecting Engineering and Manufacturing
- Model-Based – The Digital Twin
- Model-Based: Digital Twin – the PLM side
Conclusion
![]() I spent a lot of time demystifying some of PLM-related themes. The challenge remains, like in the non-PLM world, that it is hard to get educated by blog posts as you might get over-informed by (vendor-related) posts all surfing somewhere on the hype curve. Do not look at the catchy title – investigate and take time to understand HOW things will this work for you or your company. There are enough people explaining WHAT they do, but HOW it fit in a current organization needs to be solved first. Therefore the above three themes.
I spent a lot of time demystifying some of PLM-related themes. The challenge remains, like in the non-PLM world, that it is hard to get educated by blog posts as you might get over-informed by (vendor-related) posts all surfing somewhere on the hype curve. Do not look at the catchy title – investigate and take time to understand HOW things will this work for you or your company. There are enough people explaining WHAT they do, but HOW it fit in a current organization needs to be solved first. Therefore the above three themes.

 This is my concluding post related to the various aspects of the model-driven enterprise. We went through Model-Based Systems Engineering (MBSE) where the focus was on using models (functional / logical / physical / simulations) to define complex product (systems). Next we discussed Model Based Definition / Model-Based Enterprise (MBD/MBE), where the focus was on data continuity between engineering and manufacturing by using the 3D Model as a master for design, manufacturing and eventually service information.
This is my concluding post related to the various aspects of the model-driven enterprise. We went through Model-Based Systems Engineering (MBSE) where the focus was on using models (functional / logical / physical / simulations) to define complex product (systems). Next we discussed Model Based Definition / Model-Based Enterprise (MBD/MBE), where the focus was on data continuity between engineering and manufacturing by using the 3D Model as a master for design, manufacturing and eventually service information.
And last time we looked at the Digital Twin from its operational side, where the Digital Twin was applied for collecting and tuning physical assets in operation, which is not a typical PLM domain to my opinion.
Now we will focus on two areas where the Digital Twin touches aspects of PLM – the most challenging one and the most over-hyped areas I believe. These two areas are:
- The Digital Twin used to virtually define and optimize a new product/system or even a system of systems. For example, defining a new production line.
- The Digital Twin used to be the virtual replica of an asset in operation. For example, a turbine or engine.
Digital Twin to define a new Product/System
There might be some conceptual overlap if you compare the MBSE approach and the Digital Twin concept to define a new product or system to deliver. For me the differentiation would be that MBSE is used to master and define a complex system from the R&D point of view – unknown solution concepts – use hardware or software? Unknown constraints to be refined and optimized in an iterative manner.
 In the Digital Twin concept, it is more about a defining a system that should work in the field. How to combine various systems into a working solution and each of the systems has already a pre-defined set of behavioral / operational parameters, which could be 3D related but also performance related.
In the Digital Twin concept, it is more about a defining a system that should work in the field. How to combine various systems into a working solution and each of the systems has already a pre-defined set of behavioral / operational parameters, which could be 3D related but also performance related.
You would define and analyze the new solution virtual to discover the ideal solution for performance, costs, feasibility and maintenance. Working in the context of a virtual model might take more time than traditional ways of working, however once the models are in place analyzing the solution and optimizing it takes hours instead of weeks, assuming the virtual model is based on a digital thread, not a sequential process of creating and passing documents/files. Virtual solutions allow a company to optimize the solution upfront instead of costly fixing during delivery, commissioning and maintenance.
 Why aren’t we doing this already? It takes more skilled engineers instead of cheaper fixers downstream. The fact that we are used to fixing it later is also an inhibitor for change. Management needs to trust and understand the economic value instead of trying to reduce the number of engineers as they are expensive and hard to plan.
Why aren’t we doing this already? It takes more skilled engineers instead of cheaper fixers downstream. The fact that we are used to fixing it later is also an inhibitor for change. Management needs to trust and understand the economic value instead of trying to reduce the number of engineers as they are expensive and hard to plan.
 In the construction industry, companies are discovering the power of BIM (Building Information Model) , introduced to enhance the efficiency and productivity of all stakeholders involved. Massive benefits can be achieved if the construction of the building and its future behavior and maintenance can be optimized virtually compared to fixing it in an expensive way in reality when issues pop up.
In the construction industry, companies are discovering the power of BIM (Building Information Model) , introduced to enhance the efficiency and productivity of all stakeholders involved. Massive benefits can be achieved if the construction of the building and its future behavior and maintenance can be optimized virtually compared to fixing it in an expensive way in reality when issues pop up.
The same concept applies to process plants or manufacturing plants where you could virtually run the (manufacturing) process. If the design is done with all the behavior defined (hardware-in-the-loop simulation and software-in-the-loop) a solution has been virtually tested and rapidly delivered with no late discoveries and costly fixes.
 Of course it requires new ways of working. Working with digital connected models is not what engineering learn during their education time – we have just started this journey. Therefore organizations should explore on a smaller scale how to create a full Digital Twin based on connected data – this is the ultimate base for the next purpose.
Of course it requires new ways of working. Working with digital connected models is not what engineering learn during their education time – we have just started this journey. Therefore organizations should explore on a smaller scale how to create a full Digital Twin based on connected data – this is the ultimate base for the next purpose.
Digital Twin to match a product/system in the field
 When you are after the topic of a Digital Twin through the materials provided by the various software vendors, you see all kinds of previews what is possible. Augmented Reality, Virtual Reality and more. All these presentations show that clicking somewhere in a 3D Model Space relevant information pops-up. Where does this relevant information come from?
When you are after the topic of a Digital Twin through the materials provided by the various software vendors, you see all kinds of previews what is possible. Augmented Reality, Virtual Reality and more. All these presentations show that clicking somewhere in a 3D Model Space relevant information pops-up. Where does this relevant information come from?
Most of the time information is re-entered in a new environment, sometimes derived from CAD but all the metadata comes from people collecting and validating data. Not the type of work we promote for a modern digital enterprise. These inefficiencies are good for learning and demos but in a final stage a company cannot afford silos where data is collected and entered again disconnected from the source.
The main problem: Legacy PLM information is stored in documents (drawings / excels) and not intended to be shared downstream with full quality.
Read also: Why PLM is the forgotten domain in digital transformation.
If a company has already implemented an end-to-end Digital Twin to deliver the solution as described in the previous section, we can understand the data has been entered somewhere during the design and delivery process and thanks to a digital continuity it is there.
 How many companies have done this already? For sure not the companies that are already a long time in business as their current silos and legacy processes do not cater for digital continuity. By appointing a Chief Digital Officer, the journey might start, the biggest risk the Chief Digital Officer will be running another silo in the organization.
How many companies have done this already? For sure not the companies that are already a long time in business as their current silos and legacy processes do not cater for digital continuity. By appointing a Chief Digital Officer, the journey might start, the biggest risk the Chief Digital Officer will be running another silo in the organization.
So where does PLM support the concept of the Digital Twin operating in the field?
For me, the IoT part of the Digital Twin is not the core of a PLM. Defining the right sensors, controls and software are the first areas where IoT is used to define the measurable/controllable behavior of a Digital Twin. This topic has been discussed in the previous section.
The second part where PLM gets involved is twofold:
- Processing data from an individual twin
- Processing data from a collection of similar twins
Processing data from an individual twin
 Data collected from an individual twin or collection of twins can be analyzed to extract or discover failure opportunities. An R&D organization is interested in learning what is happening in the field with their products. These analyses lead to better and more competitive solutions.
Data collected from an individual twin or collection of twins can be analyzed to extract or discover failure opportunities. An R&D organization is interested in learning what is happening in the field with their products. These analyses lead to better and more competitive solutions.
Predictive maintenance is not necessarily a part of that. When you know that certain parts will fail between 10.000 and 20.000 operating hours, you want to optimize the moment of providing service to reduce downtime of the process and you do not want to replace parts way too early.

The R&D part related to predictive maintenance could be that R&D develops sensors inside this serviceable part that signal the need for maintenance in a much smaller time from – maintenance needed within 100 hours instead of a bandwidth of 10.000 hours. Or R&D could develop new parts that need less service and guarantee a longer up-time.
For an R&D department the information from an individual Digital Twin might be only relevant if the Physical Twin is complex to repair and downtime for each individual too high. Imagine a jet engine, a turbine in a power plant or similar. Here a Digital Twin will allow service and R&D to prepare maintenance and simulate and optimize the actions for the physical world before.

The five potential platforms of a digital enterprise
The second part where R&D will be interested in, is in the behavior of similar products/systems in the field combined with their environmental conditions. In this way, R&D can discover improvement points for the whole range and give incremental innovation. The challenge for this R&D organization is to find a logical placeholder in their PLM environment to collect commonalities related to the individual modules or components. This is not an ERP or MES domain.
![]() Concepts of a logical product structure are already known in the oil & gas, process or nuclear industry and in 2017 I wrote about PLM for Owners/Operators mentioning Bjorn Fidjeland has always been active in this domain, you can find his concepts at plmPartner here or as an eLearning course at SharePLM.
Concepts of a logical product structure are already known in the oil & gas, process or nuclear industry and in 2017 I wrote about PLM for Owners/Operators mentioning Bjorn Fidjeland has always been active in this domain, you can find his concepts at plmPartner here or as an eLearning course at SharePLM.
To conclude:
- This post is way too long (sorry)
- PLM is not dead – it evolves into one of the crucial platforms for the future – The Product Innovation Platform
- Current BOM-centric approach within PLM is blocking progress to a full digital thread
More to come after the holidays (a European habit) with additional topics related to the digital enterprise
 As I am preparing my presentation for the upcoming PDT Europe 2017 conference in Gothenburg, I was reading relevant experiences to a data-driven approach. During PDT Europe conference we will share and discuss the continuous transformation of PLM to support the Lifecycle Model-Based Enterprise.
As I am preparing my presentation for the upcoming PDT Europe 2017 conference in Gothenburg, I was reading relevant experiences to a data-driven approach. During PDT Europe conference we will share and discuss the continuous transformation of PLM to support the Lifecycle Model-Based Enterprise.
One of the direct benefits is that a model-based enterprise allows information to be shared without the need to have documents to be converted to a particular format, therefore saving costs for resources and bringing unprecedented speed for information availability, like what we are used having in a modern digital society.
For me, a modern digital enterprise relies on data coming from different platforms/systems and the data needs to be managed in such a manner that it can serve as a foundation for any type of app based on federated data.
This statement implies some constraints. It means that data coming from various platforms or systems must be accessible through APIs / Microservices or interfaces in an almost real-time manner. See my post Microservices, APIs, Platforms and PLM Services. Also, the data needs to be reliable and understandable for machine interpretation. Understandable data can lead to insights and predictive analysis. Reliable and understandable data allows algorithms to execute on the data.
 Classical ECO/ECR processes can become highly automated when the data is reliable, and the company’s strategy is captured in rules. In a data-driven environment, there will be much more granular data that requires some kind of approval status. We cannot do this manually anymore as it would kill the company, too expensive and too slow. Therefore, the need for algorithms.
Classical ECO/ECR processes can become highly automated when the data is reliable, and the company’s strategy is captured in rules. In a data-driven environment, there will be much more granular data that requires some kind of approval status. We cannot do this manually anymore as it would kill the company, too expensive and too slow. Therefore, the need for algorithms.
What is understandable data?
I tried to avoid as long as possible academic language, but now we have to be more precise as we enter the domain of master data management. I was triggered by this recent post from Gartner: Gartner Reveals the 2017 Hype Cycle for Data Management. There are many topics in the hype cycle, and it was interesting to see Master Data Management is starting to be taken seriously after going through inflated expectations and disillusionment.

This was interesting as two years ago we had a one-day workshop preceding PDT Europe 2015, focusing on Master Data Management in the context of PLM. The attendees at that workshop coming from various companies agreed that there was no real MDM for the engineering/manufacturing side of the business. MDM was more or less hijacked by SAP and other ERP-driven organizations.
Looking back, it is clear to me why in the PLM space MDM was not a real topic at that time. We were still too much focusing and are again too much focusing on information stored in files and documents. The only area touched by MDM was the BOM, and Part definitions as these objects also touch the ERP- and After Sales- domain.
Actually, there are various MDM concepts, and I found an excellent presentation from Christopher Bradley explaining the different architectures on SlideShare: How to identify the correct Master Data subject areas & tooling for your MDM initiative. In particular, I liked the slide below as it comes close to my experience in the process industry

Here we see two MDM architectures, the one of the left driven from ERP. The one on the right could be based on the ISO-15926 standard as the process industry has worked for over 25 years to define a global exchange standard and data dictionary. The process industry was able to reach such a maturity level due to the need to support assets for many years across the lifecycle and the relatively stable environment. Other sectors are less standardized or so much depending on new concepts that it would be hard to have an industry-specific master.
PLM as an Application Specific Master?
 If you would currently start with an MDM initiative in your company and look for providers of MDM solution, you will discover that their values are based on technology capabilities, bringing data together from different enterprise systems in a way the customer thinks it should be organized. More a toolkit approach instead of an industry approach. And in cases, there is an industry approach it is sporadic that this approach is related to manufacturing companies. Remember my observation from 2015: manufacturing companies do not have MDM activities related to engineering/manufacturing because it is too complicated, too diverse, too many documents instead of data.
If you would currently start with an MDM initiative in your company and look for providers of MDM solution, you will discover that their values are based on technology capabilities, bringing data together from different enterprise systems in a way the customer thinks it should be organized. More a toolkit approach instead of an industry approach. And in cases, there is an industry approach it is sporadic that this approach is related to manufacturing companies. Remember my observation from 2015: manufacturing companies do not have MDM activities related to engineering/manufacturing because it is too complicated, too diverse, too many documents instead of data.
Now with modern digital PLM, there is a need for MDM to support the full digital enterprise. Therefore, when you combine the previous observations with a recent post on Engineering.com from Tom Gill: PLM Initiatives Take On Master Data Transformation I started to come to a new hypotheses:
For companies with a model-based approach that has no MDM in place, the implementation of their Product Innovation Platform (modern PLM) should be based on the industry-specific data definition for this industry.
Tom Gill explains in his post the business benefits and values of using the PLM as the source for an MDM approach. In particular, in modern PLM environments, the PLM data model is not only based on the BOM. PLM now encompasses the full lifecycle of a product instead of initially more an engineering view. Modern PLM systems, or as CIMdata calls them Product Innovation Platforms, manage a complex data model, based on a model-driven approach. These entities are used across the whole lifecycle and therefore could be the best start for an industry-specific MDM approach. Now only the industries have to follow….
 Once data is able to flow, there will be another discussion: Who is responsible for which attributes. Bjørn Fidjeland from plmPartner recently wrote: Who owns what data when …? The content of his post is relevant, I only would change the title: Who is responsible for what data when as I believe in a modern digital enterprise there is no ownership anymore – it is about sharing and responsibilities
Once data is able to flow, there will be another discussion: Who is responsible for which attributes. Bjørn Fidjeland from plmPartner recently wrote: Who owns what data when …? The content of his post is relevant, I only would change the title: Who is responsible for what data when as I believe in a modern digital enterprise there is no ownership anymore – it is about sharing and responsibilities
Conclusion
Where MDM in the past did not really focus on engineering data due to the classical document-driven approach, now in modern PLM implementations, the Master Data Model might be based on the industry-specific data elements, managed and controlled coming from the PLM data model
Do you follow my thoughts / agree ?
 In my earlier post The weekend after PDT Europe I wrote about the first day of this interesting conference. We ended that day with some food for thought related to a bimodal PLM approach. Now I will take you through the highlights of day 2.
In my earlier post The weekend after PDT Europe I wrote about the first day of this interesting conference. We ended that day with some food for thought related to a bimodal PLM approach. Now I will take you through the highlights of day 2.
Interoperability and openness in the air (aerospace)
I believe Airbus and Boeing are one of the most challenged companies when it comes to PLM. They have to cope with their stakeholders and massive amount of suppliers involved, constrained by a strong focus on safety and quality. And as airplanes have a long lifetime, the need to keep data accessible and available for over 75 years are massive challenges. The morning was opened by presentations from Anders Romare (Airbus) and Brian Chiesi (Boeing) where they confirmed they could switch the presenter´s role between them as the situations in Airbus and Boeing are so alike.
![]() Anders Romare started with a presentation called: Digital Transformation through an e2e PLM backbone, where he explained the concept of extracting data from the various silo systems in the company (CRM, PLM, MES, ERP) to make data available across the enterprise. In particular in their business transformation towards digital capabilities Airbus needed and created a new architecture on top of the existing business systems, focusing on data (“Data is the new oil”).
Anders Romare started with a presentation called: Digital Transformation through an e2e PLM backbone, where he explained the concept of extracting data from the various silo systems in the company (CRM, PLM, MES, ERP) to make data available across the enterprise. In particular in their business transformation towards digital capabilities Airbus needed and created a new architecture on top of the existing business systems, focusing on data (“Data is the new oil”).
In order to meet a data-driven environment, Airbus extracts and normalizes data from their business systems and provides a data lake with integrated data on top of which various apps can run to offer digital services to existing and new stakeholders on any type of device. The data-driven environment allows people to have information in context and almost real-time available to make right decisions. Currently, these apps run on top of this data layer.

Now imagine information captured by these apps could be stored or directed back in the original architecture supporting the standard processes. This would be a real example of the bimodal approach as discussed on day 1. As a closing remark Anders also stated that three years ago digital transformation was not really visible at Airbus, now it is a must.
 Next Brian Chiesi from Boeing talked about Data Standards: A strategic lever for Boeing Commercial Airplanes. Brian talked about the complex landscape at Boeing. 2500 Applications / 5000 Servers / 900 changes annually (3 per day) impacting 40.000 users. There is a lot of data replication because many systems need their own proprietary format. Brian estimated that if 12 copies exist now, in the ideal world 2 or 3 will do. Brian presented a similar future concept as Airbus, where the traditional business systems (Systems Engineering, PLM, MRP, ERP, MES) are all connected through a service backbone. This new architecture is needed to address modern technology capabilities (social / mobile / analytics / cloud /IoT / Automation / ,,)
Next Brian Chiesi from Boeing talked about Data Standards: A strategic lever for Boeing Commercial Airplanes. Brian talked about the complex landscape at Boeing. 2500 Applications / 5000 Servers / 900 changes annually (3 per day) impacting 40.000 users. There is a lot of data replication because many systems need their own proprietary format. Brian estimated that if 12 copies exist now, in the ideal world 2 or 3 will do. Brian presented a similar future concept as Airbus, where the traditional business systems (Systems Engineering, PLM, MRP, ERP, MES) are all connected through a service backbone. This new architecture is needed to address modern technology capabilities (social / mobile / analytics / cloud /IoT / Automation / ,,)

Interesting part of this architecture is that Boeing aims to exchange data with the outside world (customers / regulatory/supply chain /analytics / manufacturing) through industry standard interfaces to have an optimal flow of information. Standardization would lead to a reduction of customized applications, minimize costs of integration and migration, break the obsolescence cycle and enable future technologies. Brian knows that companies need to pull for standards, vendors will deliver. Boeing will be pushing for standards in their contracts and will actively work together with five major Aerospace & Defense companies to define required PLM capabilities and have a unified voice to PLM solutions providers.
My conclusion on these to Aerospace giants is they express the need to adapt to move to modern digital businesses, no longer the linear approach from the classic airplane programs. Incremental innovation in various domains is the future. The existing systems need to be there to support their current fleet for many, many years to come. The new data-driven layer needs to be connected through normalization and standardization of data. For the future focus on standards is a must.
 Simon Floyd from Microsoft talked about The Impact of Digital Transformation in the Manufacturing Enterprise where he talked us through Digital Transformation, IoT, and analytics in the product lifecycle, clarified by examples from the Rolls Royce turbine engine. A good and compelling story which could be used by any vendor explaining digital transformation and the relation to IoT. Next, Simon walked through the Microsoft portfolio and solution components to support a modern digital enterprise based on various platform services. At the end, Simon articulated how for example ShareAspace based on Microsoft infrastructure and technology can be an interface between various PLM environments through the product lifecycle.
Simon Floyd from Microsoft talked about The Impact of Digital Transformation in the Manufacturing Enterprise where he talked us through Digital Transformation, IoT, and analytics in the product lifecycle, clarified by examples from the Rolls Royce turbine engine. A good and compelling story which could be used by any vendor explaining digital transformation and the relation to IoT. Next, Simon walked through the Microsoft portfolio and solution components to support a modern digital enterprise based on various platform services. At the end, Simon articulated how for example ShareAspace based on Microsoft infrastructure and technology can be an interface between various PLM environments through the product lifecycle.
Simon’s presentation was followed by a panel discussion where the theme was: When is history and legacy an asset and barriers of entry and When does it become a burden and an invitation to future competitors.
 Mark Halpern (Gartner) mentioned here again the bimodal thinking. Aras is bimodal. The classical PLM vendors running in mode 1 will not change radically and the new vendors, the mode 2 types will need time to create credibility. Other companies mentioned here PropelPLM (PLM on Salesforce platform) or OnShape will battle the next five years to become significant and might disrupt.
Mark Halpern (Gartner) mentioned here again the bimodal thinking. Aras is bimodal. The classical PLM vendors running in mode 1 will not change radically and the new vendors, the mode 2 types will need time to create credibility. Other companies mentioned here PropelPLM (PLM on Salesforce platform) or OnShape will battle the next five years to become significant and might disrupt.
Simon Floyd(Microsoft) mentioned that in order to keep innovation within Microsoft, they allow for startups within in the company, with no constraints in the beginning to Microsoft. This to keep disruption inside you company instead of being disrupted from outside. Another point mentioned was that Tesla did not want to wait till COTS software would be available for their product development and support platform. Therefore they develop parts themselves. Are we going back to the early days of IT ?
Interesting trend I believe too, in case the building blocks for such solution architecture are based on open (standardized ?) services.
Data Quality
After the lunch, the conference was split in three streams where I was participating in the “Creating and managing information quality stream.” As I discussed in my presentation from day 1, there is a need for accurate data, starting a.s.a.p. as the future of our businesses will run on data as we learned from all speakers (and this is not a secret – still many companies do not act).
![]() In the context of data quality, Jean Brange from Boost presented the ISO 8000 framework for data and information quality management. This standard is now under development and will help companies to address their digital needs. The challenge of data quality is that we need to store data with the right syntax and semantic to be used and in addition, it needs to be pragmatic: what are we going to store that will have value. And then the challenge of evaluating the content. Empty fields can be discovered, however, how do you qualify the quality of field with a value. The ISO 8000 framework is a framework, like ISO 9000 (product quality) that allow companies to work in a methodological way towards acceptable and needed data quality.
In the context of data quality, Jean Brange from Boost presented the ISO 8000 framework for data and information quality management. This standard is now under development and will help companies to address their digital needs. The challenge of data quality is that we need to store data with the right syntax and semantic to be used and in addition, it needs to be pragmatic: what are we going to store that will have value. And then the challenge of evaluating the content. Empty fields can be discovered, however, how do you qualify the quality of field with a value. The ISO 8000 framework is a framework, like ISO 9000 (product quality) that allow companies to work in a methodological way towards acceptable and needed data quality.

![]() Magnus Färneland from Eurostep addressed the topic of data quality and the foundation for automation based on the latest developments done by Eurostep on top of their already rich PLCS data model. The PLCS data model is an impressive model as it already supports all facets of product lifecycle from design, through development and operations. By introducing soft typing, EuroStep allows a more detailed tuning of the data model to ensure configuration management. When at which stage of the lifecycle is certain information required (and becomes mandatory) ? Consistent data quality enforced through business process logic.
Magnus Färneland from Eurostep addressed the topic of data quality and the foundation for automation based on the latest developments done by Eurostep on top of their already rich PLCS data model. The PLCS data model is an impressive model as it already supports all facets of product lifecycle from design, through development and operations. By introducing soft typing, EuroStep allows a more detailed tuning of the data model to ensure configuration management. When at which stage of the lifecycle is certain information required (and becomes mandatory) ? Consistent data quality enforced through business process logic.
The conference ended with Marc Halpern making a plea for Take Control of Your Product Data or Lose Control of Your Revenue, where Marc painted the future (horror) scenario that due to digital transformation the real “big fish” will be the digital business ecosystem owner and that once you are locked in with a vendor, these vendors can uplift their prices to save their own business without any respect for your company’s business model. Marc gave some examples where some vendor raised prices with the subscription model up to 40 %. Therefore even when you are just closing a new agreement with a vendor, you should negotiate a price guarantee and a certain bandwidth for increase. And on top of that you should prepare an exit strategy – prepare data for migration and have backups using standards. Marc gave some examples of billions extra cost related to data quality and loss. It can hurt !! Finally, Marc ended with recommendations for master data management and quality as a needed company strategy.

 Gerard Litjens from CIMdata as closing speaker gave a very comprehensive overview of The Internet of Thing – What does it mean for PLM ? based on CIMdata’ s vision. As all vendors in this space explain the relation between IoT and PLM differently, it was a good presentation to be used as a base for the discussion: how does IoT influence our PLM landscape. Because of the length of this blog post, I will not further go into these details – it is worth obtaining this overview.
Gerard Litjens from CIMdata as closing speaker gave a very comprehensive overview of The Internet of Thing – What does it mean for PLM ? based on CIMdata’ s vision. As all vendors in this space explain the relation between IoT and PLM differently, it was a good presentation to be used as a base for the discussion: how does IoT influence our PLM landscape. Because of the length of this blog post, I will not further go into these details – it is worth obtaining this overview.
Concluding: PDT2016 is a crucial PLM conference for people who are interested in the details of PLM. Other conferences might address high-level customer stories, at PDT2016 it is about the details and sharing the advantages of using standards. Standards are crucial for a data-driven environment where business platforms with all their constraints will be the future. And I saw more and more companies are working with standards in a pragmatic manner, observing the benefits and pushing for more data standards – it is not just theory.
See you next year ?
In my series describing the best practices related to a (PLM) data model, I described the general principles, the need for products and parts, the relation between CAD documents and the EBOM, the topic of classification and now the sensitive relation between EBOM and MBOM.
First some statements to set the scene:
- The EBOM represents the engineering (design) view of a product, structured in a way that it represents the multidisciplinary view of the functional definition of the product. The EBOM combined with its related specification documents, models, drawings, annotations should give a 100 % clear definition of the product.
- The MBOM represents the manufacturing view of a product, structured in a way that represents the way the product is manufactured. This structure is most of the time not the same as the EBOM, due to the manufacturing process and purchasing of parts.

A (very) simplified picture illustrating the difference between an EBOM and a MBOM. If the Car was a diesel there would be also embedded software in both BOMs (currently hidden)
For many years, the ERP systems have claimed ownership of the MBOM for two reasons
- Historically the MBOM was the starting point for production. Where the engineering department often worked with a set of tools, the ERP system was the system where data was connected and used to have a manufacturing plan and real-time execution

- To accommodate a more advanced integration with PDM systems, ERP vendors began to offer an EBOM capability also in their system as PDM systems often worked around the EBOM.

These two approaches made it hard to implement “real” PLM where (BOM) data is flowing through an organization instead of stored in a single system.
By claiming ownership of the BOM by ERP, some problems came up:
- A disconnect between the iterative engineering domain and the execution driven ERP domain. The EBOM is under continuous change (unless you have a simple or the ultimate product) and these changes are all related to upstream information, specifications, requirements, engineering changes and design changes. An ERP system is not intended for handling iterative processes, therefore forcing the user to work in a complex environment or trying to fix the issue through heavy customization on the ERP side.

- Global manufacturing and outsourced manufacturing introduced a new challenge for ERP-centric implementations. This would require all manufacturing sites also the outsourced manufacturers the same capabilities to transfer an EBOM into a local MBOM. And how do you capitalize the IP from your products when information is handled in a dispersed environment?



The solution to this problem is to extend your PDM implementation towards a “real” PLM implementation providing the support for EBOM, MBOM, and potential plant specific MBOM. All in a single system / user-experience designed to manage change and to allow all users to work in a global collaborative way around the product. MBOM information then will then be pushed when needed to the (local) ERP system, managing the execution.

Note 1: Pushing the MBOM to ERP does not mean a one-time big bang. When manufacturing parts are defined and sourced, there will already be a part definition in the ERP system too, as logistical information must come from ERP. The final push to ERP is, therefore, more a release to ERP combined with execution information (when / related to which order).
In this scenario, the MBOM will be already in ERP containing engineering data complemented with manufacturing data. Therefore from the PLM side we talk more about sharing BOM information instead of owning. Certain disciplines have the responsibility for particular properties of the BOM, but no single ownership.
Note 2: The whole concept of EBOM and MBOM makes only sense if you have to deliver repetitive products. For a one-off product, more a project, the engineering process will have the manufacturing already in mind. No need for a transition between EBOM and MBOM, it would only slow down the delivery.
Now let´s look at some EBOM-MBOM specifics
EBOM phantom assemblies
 When extracting an EBOM directly from a 3D CAD structure, there might be subassemblies in the EBOM due to a logical grouping of certain items. You do not want to see these phantom assemblies in the MBOM as they only complicate the structuring of the MBOM or lead to phantom activities. In an EBOM-MBOM transition these phantom assemblies should disappear and the underlying end items should be linked to the higher level.
When extracting an EBOM directly from a 3D CAD structure, there might be subassemblies in the EBOM due to a logical grouping of certain items. You do not want to see these phantom assemblies in the MBOM as they only complicate the structuring of the MBOM or lead to phantom activities. In an EBOM-MBOM transition these phantom assemblies should disappear and the underlying end items should be linked to the higher level.
EBOM materials
In the EBOM, there might be materials like a rubber tube with a certain length, a strip with a certain length, etc. These materials cannot be purchased in these exact dimensions. Part of the EBOM to MBOM transition is to translate these EBOM items (specifying the exact material) into purchasable MBOM items combined with a fitting operation.
EBOM end-items (make)
For make end-items, there are usually approved manufacturers defined and it is desirable to have multiple manufacturers (certified through the AML) for make end-items, depending on cost, capacity and where the product needs to be manufactured. Therefore, a make end-item in the EBOM will not appear in a resolved MBOM.
EBOM end-items (buy)
For buy end-items, there is usually a combination of approved manufacturers (AML) combined with approved vendors (AVL). The approved manufacturers are defined by engineering, based on part specifications. Approved vendors are defined by manufacturing combined with purchasing based on the approved manufacturers and logistical or commercial conditions
Are EBOM items and MBOM items different?
 There is a debate if EBOM items should/could appear in an MBOM or that EBOM items are only in the EBOM and connected to resolved items in the MBOM. Based on the previous descriptions of the various EBOM items, you can conclude that a resolved MBOM does not contain EBOM items anymore in case of multiple sourcing. Only when you have a single manufacturer for an EBOM item, the EBOM item could appear in the MBOM. Perhaps this is current in your company, but will this stay the same in the future?
There is a debate if EBOM items should/could appear in an MBOM or that EBOM items are only in the EBOM and connected to resolved items in the MBOM. Based on the previous descriptions of the various EBOM items, you can conclude that a resolved MBOM does not contain EBOM items anymore in case of multiple sourcing. Only when you have a single manufacturer for an EBOM item, the EBOM item could appear in the MBOM. Perhaps this is current in your company, but will this stay the same in the future?
It is up to your business process and type of product which direction you choose. Coming back to one-off products, here is does not make sense to have multiple manufacturers. In that case, you will see that the EBOM item behaves at the same time as an MBOM item.
What about part numbering?
 Luckily I reached the 1000 words so let´s be short on this debate. In case you want an automated flow of information between PLM and ERP, it is important that shared data is connected through a unique identifier.
Luckily I reached the 1000 words so let´s be short on this debate. In case you want an automated flow of information between PLM and ERP, it is important that shared data is connected through a unique identifier.
Automation does no need intelligent numbering. Therefore giving parts in the PLM system and the ERP system a unique, meaningless number you ensure guaranteed digital connectivity.
If you want to have additional attributes on the PLM or ERP side that describe the part with a number relevant for human identification on the engineering side or later at the manufacturing side (labeling), this all can be solved.
An interesting result of this approach is that a revision of a part is no longer visible on the ERP side (unless you insist). Each version of the MBOM parts is pointing to a unique version of an MBOM part in ERP, providing an error free sharing of data.
Conclusion
Life can be simple if you generalize and if there was no past, no legacy and no ownership of data thinking. The transition of EBOM to MBOM is the crucial point where the real PLM vision is applied. If there is no data sharing on MBOM level, there are two silos, the characteristic of the old linear past.
(See also: From a linear world to a circular and fast)
What do you think? Is more complexity needed?

I will be soon discussing these topics at the PDT2015 in Stockholm on October 13-14. Will you be there ?
And for Dutch/Belgium readers – October 8th in Bunnik:

Op 8 oktober ben ik op het BIM Open 2015 Congres in Bunnik waar ik de overeenkomsten tussen PLM en BIM zal bespreken en wat de constructie industrie kan leren van PLM
 In my previous post describing the various facets of the EBOM, I mentioned several times classification as an important topic related to the PLM data model. Classification is crucial to support people to reuse information and, in addition, there are business processes that are only relevant for a particular class of information, so it is not only related to search/reuse support.
In my previous post describing the various facets of the EBOM, I mentioned several times classification as an important topic related to the PLM data model. Classification is crucial to support people to reuse information and, in addition, there are business processes that are only relevant for a particular class of information, so it is not only related to search/reuse support.
In 2008, I wrote a post about classification, you can read it here. Meanwhile, the world has moved on, and I believe more modern classification methods exist.
Why classification ?
 First of all classification is used to structure information and to support retrieval of the information at a later moment, either for reuse or for reference later in the product lifecycle. Related to reuse, companies can save significant money when parts are reused. It is not only the design time or sourcing time that is reduced. Additional benefits are lower risks for errors (fewer discoveries), reduced process and approval time (human overhead), reduced stock (if applicable), and more volume discount (if applicable) and reduced End-Of-Life handling.
First of all classification is used to structure information and to support retrieval of the information at a later moment, either for reuse or for reference later in the product lifecycle. Related to reuse, companies can save significant money when parts are reused. It is not only the design time or sourcing time that is reduced. Additional benefits are lower risks for errors (fewer discoveries), reduced process and approval time (human overhead), reduced stock (if applicable), and more volume discount (if applicable) and reduced End-Of-Life handling.
An interesting discussion about reuse started by Joe Barkai can also be found on LinkedIn here, including interesting comments
Classification can also be used to control access to certain information (mainly document classification), or classification can be used to make sure certain processes are followed, e.g. export control, hazardous materials, budget approvals, etc. Although I will speak mainly about part classification in this post, classification can be used for any type of information in the PLM data model.
Classification standards
 Depending on the industry you are working in, there are various classification standards for parts. When I worked in the German-speaking countries (the DACH-länder) the most discussed classification at that time was DIN4000 (Sachmerkmal-liste), a must have standard for many of the small and medium sized manufacturing companies. The DIN 4000 standard had a predefined part hierarchy and did not describe the necessary properties per class. I haven’t met a similar standard in other countries at that time.
Depending on the industry you are working in, there are various classification standards for parts. When I worked in the German-speaking countries (the DACH-länder) the most discussed classification at that time was DIN4000 (Sachmerkmal-liste), a must have standard for many of the small and medium sized manufacturing companies. The DIN 4000 standard had a predefined part hierarchy and did not describe the necessary properties per class. I haven’t met a similar standard in other countries at that time.
Another very generic classification I have seen are the UNSPC standard, again a hierarchical classification supporting everything in the universe but no definition of attributes.
 Other classification standards like ISO13399, RosettaNET, ISO15926 and IFC exist to support collaboration and/or the supply chain. When you want to exchange data with other disciplines or partners. The advantage of a standard definition (with attributes) is that you can exchange data with less human processing (saving labor costs and time – the benefit of a digital enterprise).
Other classification standards like ISO13399, RosettaNET, ISO15926 and IFC exist to support collaboration and/or the supply chain. When you want to exchange data with other disciplines or partners. The advantage of a standard definition (with attributes) is that you can exchange data with less human processing (saving labor costs and time – the benefit of a digital enterprise).
I will not go deeper into the various standards here as I am not the expert for all the standards. Every industry has its own classification standards, a hierarchical standard, and if more advanced the hierarchy is also supported by attributes related to each class. But let´s go into the data model part.
Classification and data model
 The first lesson I learned when implementing PLM was that you should not build your classification hard-coded into the PLM, data model. When working with SmarTeam is was very easy to define part classes and attributes to inherit. Some customers had more than 300 classes represented in their data model just for parts. You can imagine that it looks nice in a demo. However when it comes to reality, a hard-coded classification becomes a pain in the model. (left image, one of the bad examples from the past)
The first lesson I learned when implementing PLM was that you should not build your classification hard-coded into the PLM, data model. When working with SmarTeam is was very easy to define part classes and attributes to inherit. Some customers had more than 300 classes represented in their data model just for parts. You can imagine that it looks nice in a demo. However when it comes to reality, a hard-coded classification becomes a pain in the model. (left image, one of the bad examples from the past)
1 – First of all, classification should be dynamic, easy to extend.
2 – The second problem however with a hard-coded classification was that once a part is defined for the first time the information object has a fixed class. Later changes need a lot of work (relinking of information / approval processes for the new information).
3 – Finally, the third point against a hard-coded classification is that it is likely that parts will be classified according to different classifications at the same time. The image bellow shows such a multiple classification.

So the best approach is to have a generic part definition in your data model and perhaps a few subtypes. Companies tend to differentiate still between hardware (mechanical / electrical) parts and software parts.
Next a part should be assigned at least to one class, and the assignment to this class would bring more attributes to the part. Most of the PLM systems that support classification have the ability to navigate through a class hierarchy and find similar parts.
When parts are relevant for ERP they might belong to a manufacturing parts class, which add particular attributes required for a smooth PLM – ERP link. Manufacturing part types can be used as templates for ERP to be completed.
This concept is also shared by Ed Lopategui as commented to my earlier post about EBOM Part types. Ed states:
Think part of the challenge moving forward is we’ve always handled these as parts under different methodologies, which requires specific data structures for each, etc. The next gen take on all this needs to be more malleable perhaps. So there are just parts. Be they service or make/buy or some combination – say a long lead functional standard part and they would acquire the properties, synchronizations, and behaviors accordingly. People have trouble picking the right bucket, and sometimes the buckets change. Let the infrastructure do the work. That would help the burden of multiple transitions, where CAD BOM to EBOM to MBOM to SBOM eventually ends up in a chain of confusion.
I fully agree with his statement and consider this as the future trend of modern PLM: Shared data that will be enriched by different usage through the lifecycle.
Why don’t we classify all data in PLM?
There are two challenges for classification in general.
- The first one is that the value of classification only becomes visible in the long-term, and I have seen several young companies that were only focusing on engineering. No metadata in the file properties, no part-centric data management structure and several years later they face the lack of visibility what has been done in the past. Only if one of the engineers remembers a similar situation, there is a chance of reuse.
- The second challenge is that through a merger or acquisition suddenly the company has to manage two classifications. If the data model was clean (no hard-coded subclasses) there is hope to merge the information together. Otherwise, it might become a painful activity to discover similarities.
SO THINK AHEAD EVEN IF YOU DO NOT SEE THE NEED NOW !
Modern search based applications
There are ways to improve classification and reuse by using search-based application which can index archives and try to find similarity in properties / attributes. Again if the engineers never filled the properties in the CAD model, there is little to nothing to recover as I experienced in a customer situation. My PLM US peer, Dick Bourke, wrote several articles about search-based applications and classification for engineering.com, which are interesting to read if you want to learn more: Useful Search Applications for Finding Engineering Data
So much to discuss on this topic, however I reached my 1000 words again ![]()
Conclusion
Classification brings benefits for reuse and discovery of information although benefits are long-term. Think long-term too when you define classifications. Keep the data model simple and add attributes groups to parts based on functional classifications. This enables a data-driven PLM implementation where the power is in the attributes not longer in the part number. In the future, search-based applications will offer a quick start to classify and structure data.

Hi Jos, Knowing your background in methodology and education, I wanted to share a longer article with you: “What is…
Interesting reflection, Jos. In my experience, the situation you describe is very recognizable. At the company where I work, sustainability…
[…] (The following post from PLM Green Global Alliance cofounder Jos Voskuil first appeared in his European PLM-focused blog HERE.) […]
[…] recent discussions in the PLM ecosystem, including PSC Transition Technologies (EcoPLM), CIMPA PLM services (LCA), and the Design for…
Jos, all interesting and relevant. There are additional elements to be mentioned and Ontologies seem to be one of the…