
 In my previous post, I discovered that my header for this series is confusing. Although a future implementation of system lifecycle management (SLM/PLM) will rely on models, the most foundational change needed is a technical one to create a data-driven infrastructure for connected ways of working.
In my previous post, I discovered that my header for this series is confusing. Although a future implementation of system lifecycle management (SLM/PLM) will rely on models, the most foundational change needed is a technical one to create a data-driven infrastructure for connected ways of working.
My previous article discussed the concept of the dataset, which led to interesting discussions on LinkedIn and in my personal interactions. Also, this time Matthias Ahrens (HELLA) shared again a relevant but very academic article in this context – how to harmonize company information.
 For those who want to dive deeper into the concept of connected datasets, read this article: The euBusinessGraph ontology: A lightweight ontology for harmonizing basic company information.
For those who want to dive deeper into the concept of connected datasets, read this article: The euBusinessGraph ontology: A lightweight ontology for harmonizing basic company information.
The article illustrates that the topic is relevant for all larger enterprises (and it is not an easy topic).
This time I want to share my thoughts about the two statements from my introductory post, i.e.:
A model-based approach with connected datasets seems to be the way forward. Managing data in documents will become inefficient as they cannot contribute to any digital accelerator, like applying algorithms. Artificial Intelligence relies on direct access to qualified data.
A model-based approach with connected datasets
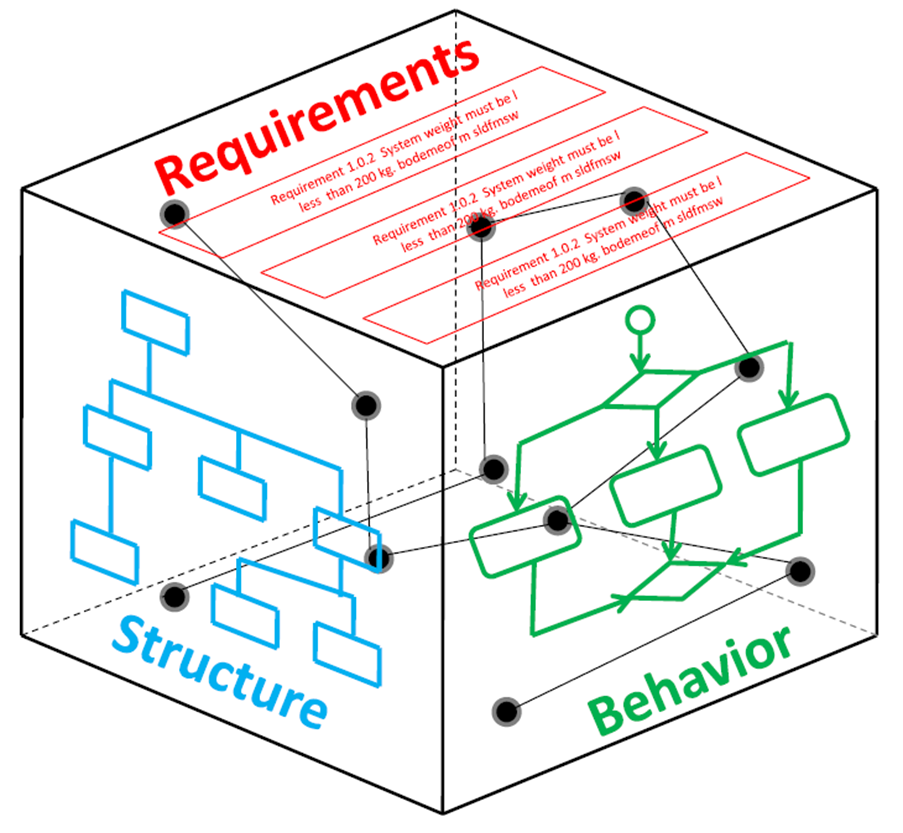 We discussed connected datasets in the previous post; now, let’s explore why models and datasets are related. In the traditional CAD-centric PLM domain, most people will associate the word model with a CAD model, to be more precise, the 3D CAD Model. However, there are many other types of models used related to product development, delivery and operations.
We discussed connected datasets in the previous post; now, let’s explore why models and datasets are related. In the traditional CAD-centric PLM domain, most people will associate the word model with a CAD model, to be more precise, the 3D CAD Model. However, there are many other types of models used related to product development, delivery and operations.
A model can be a:
Physical Model
- A smaller-scale object for the first analysis, e.g., a city or building model, an airplane model
Conceptual Model
- A conceptual model describes the entities and their relations, e.g., a Process Flow Diagram (PFD)
 A mathematical model describes a system concept using a mathematical language, e.g., weather or climate models. Modelica and MATLAB would fall in this category
A mathematical model describes a system concept using a mathematical language, e.g., weather or climate models. Modelica and MATLAB would fall in this category- A CGI (Computer Generated Imagery) or 3D CAD model is probably the most associated model in the mind of traditional PLM practitioners
- Functional and Logical Models describing the services and components of a system are crucial in an MBSE
Operational Model
- A model providing performance analysis based on (real-time) data coming from selected data sources. It could be an operational business model, an asset performance model; even my Garmin’s training performance model is such an operating model.
The list of all models above is not extensive nor academically defined. Moreover, some model term definitions might overlap, e.g., where would we classify software models or manufacturing models?
All models are a best-so-far approach to describing reality. Based on more accurate data from observations or measurements, the model comes closer to what happens in reality.
A model and its data
Never blame the model when there is a difference between what the model predicts and the observed reality. It is still a model. That’s why we need feedback loops from the actual physical world to the virtual world to fine-tune the model.
 Part of what we call Artificial Intelligence is nothing more than applying algorithms to a model. The more accurate data available, the more “intelligent” the artificial intelligence solution will be.
Part of what we call Artificial Intelligence is nothing more than applying algorithms to a model. The more accurate data available, the more “intelligent” the artificial intelligence solution will be.
 By using data analysis complementary to the model, the model may get better and better through self-learning. Like our human brain, it starts with understanding the world (our model) and collecting experiences (improving our model).
By using data analysis complementary to the model, the model may get better and better through self-learning. Like our human brain, it starts with understanding the world (our model) and collecting experiences (improving our model).
There are two points I would like to highlight for this paragraph:
- A model is never 100 % the same as reality – so don’t worry about deviations. There will always be a difference between virtual predicted and physical measured – most of the time because reality has much more influencing parameters.
- The more qualified data we use in the model, the closer to reality – so focus on accurate (and the right) data for your model. Although, as most of the time, it is impossible to fully model a system, focus on the most significant data sources.
The ultimate goal: THE DIGITAL TWIN
The discussion related to data-driven and the usage of models might feel abstract and complex (and that’s the case). However the term “digital twin” is well known and even used in board rooms.
 The great benefits of a digital twin for business operations and for sustainability are promoted by many software vendors and consultancy firms.
The great benefits of a digital twin for business operations and for sustainability are promoted by many software vendors and consultancy firms.
My statement and reason for this series of blog posts: Digital Twins do not run on documents, you need to have a data-driven, model-based infrastructure to efficiently benefit from digital twin concepts.
 Unfortunate a reliable and sustainable implementation of a digital twin requires more than software – it is a learning journey to connect the right data to the right model.
Unfortunate a reliable and sustainable implementation of a digital twin requires more than software – it is a learning journey to connect the right data to the right model.
A puzzle every company has to solve as there is no 100 percent blueprint at this time.
Are Low Code platforms the answer?
I mentioned the importance of accurate data. Companies have different systems or even platforms managing enterprise data. The digital dream is that by combining datasets from different systems and platforms, we can provide to any user the needed information in real-time. My statement from my introductory post was:
I don’t believe in Low-Code platforms that provide ad-hoc solutions on demand. The ultimate result after several years might be again a new type of spaghetti. On the other hand, standardized interfaces and protocols will probably deliver higher, long-term benefits. Remember: Low code: A promising trend or a Pandora’s Box?
Let’s look into some of the low-code platform messages mentioned by Low-Code advocates:
You will have an increasingly hard time finding developers to keep up with global app development demands (reason #1 for PEGA)
![]() This statement reminded me of the early days of SmarTeam implementations. With a Data model Wizard, a Form Designer, and a Visual Basic COM API, you could create any kind of data management application with SmarTeam. By using its built-in behaviors for document lifecycle management, item lifecycle management, and CAD integrations combined with easy customizations.
This statement reminded me of the early days of SmarTeam implementations. With a Data model Wizard, a Form Designer, and a Visual Basic COM API, you could create any kind of data management application with SmarTeam. By using its built-in behaviors for document lifecycle management, item lifecycle management, and CAD integrations combined with easy customizations.
The sky was the limit to satisfy end users. No need for an experienced partner or to be a skilled programmer (this was 2003+). SmarTeam was a low-code platform the marketing department would say now.
 A lot of my activities between 2003 and 2010 were related fixing the problems related to flexibility, making sense (again) of customizations. I wrote about this in a 2015 post: The importance of a (PLM) data model sharing the experiences of “fixing” issues created to flexibility.
A lot of my activities between 2003 and 2010 were related fixing the problems related to flexibility, making sense (again) of customizations. I wrote about this in a 2015 post: The importance of a (PLM) data model sharing the experiences of “fixing” issues created to flexibility.
Think first
 The challenge is that an enthusiastic team creates a (low code) solution rapidly. Immediate success is celebrated by the people involved. However, the future impact of this solution is often forgotten – we did the job, right?
The challenge is that an enthusiastic team creates a (low code) solution rapidly. Immediate success is celebrated by the people involved. However, the future impact of this solution is often forgotten – we did the job, right?
Documentation and a broader visibility are often lacking when implementing such a solution.
For example, suppose your product data is going to be consumed by another app. In that case, you need to make sure that the information you consume is accurate. On the other hand, perhaps the information was valid when you created the app.
 However, if your friendly co-worker has moved on to another job and someone with different data standards becomes responsible for the data you consume, the reliability might fail. So how do you guarantee its quality?
However, if your friendly co-worker has moved on to another job and someone with different data standards becomes responsible for the data you consume, the reliability might fail. So how do you guarantee its quality?
Easy tools have often led to spaghetti, starting from Clipper (the old days), Visual Basic (the less old days) to highly customizable systems (like Aras is promoting) and future low-code platforms (and Aras is there again).
 However, the strength of being highly flexible is also the weaknesses if not managed and understood correctly. In particular, in a digital enterprise architecture, you need skilled people who guarantee a reliable anchorage of the solution.
However, the strength of being highly flexible is also the weaknesses if not managed and understood correctly. In particular, in a digital enterprise architecture, you need skilled people who guarantee a reliable anchorage of the solution.
The HBR article When Low-Code/No-Code Development Works — and When It Doesn’t mentions the same point:
There are great benefits from LC/NC software development, but management challenges as well. Broad use of these tools institutionalizes the “shadow IT” phenomenon, which has bedeviled IT organizations for decades — and could make the problem much worse if not appropriately governed. Citizen developers tend to create applications that don’t work or scale well, and then they try to turn them over to IT. Or the person may leave the company, and no one knows how to change or support the system they developed.
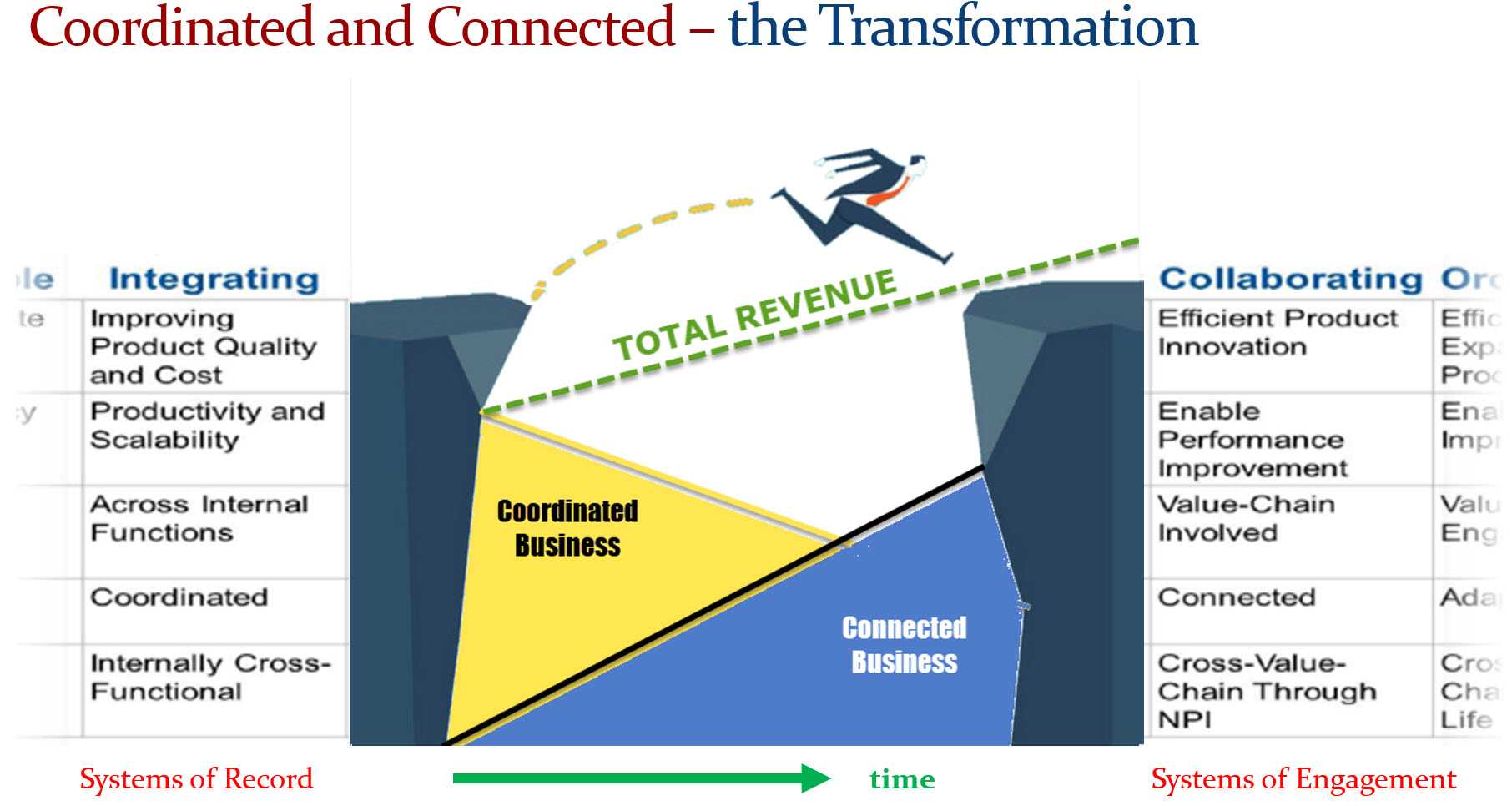
The fundamental difference: from coordinated to connected
For the moment, I remain skeptical about the low-code hype, because I have seen this kind of hype before. The most crucial point companies need to understand is that the coordinated world and the connected world are incompatible.
 Using new tools based on old processes and existing data is not a digital transformation. Instead, a focus on value streams and their needed (connected) data should lead to the design of a modern digital enterprise, not the optimization and connectivity between organizational siloes.
Using new tools based on old processes and existing data is not a digital transformation. Instead, a focus on value streams and their needed (connected) data should lead to the design of a modern digital enterprise, not the optimization and connectivity between organizational siloes.
Before buying a tool (a medicine) to reduce the current pains, imagine your future ways of working, discover what is possible with your existing infrastructure and identify the gaps.
Next, you need to analyze if these gaps are so significant that it requires a technology change. Probably it does, as historically, systems were not designed to share data horizontally in an organization.
![]() In this context, have a look at Lionel Grealou’s s article for Engineering.com:
In this context, have a look at Lionel Grealou’s s article for Engineering.com:
Data Readiness in the new age of digital collaboration.
Conclusion
We discussed the crucial relation between models and data. Models have only value if they acquire the right and accurate data (exercise 1).
Next, even the simplest development platforms, like low-code platforms, require brains and a long-term strategy (exercise 2) – nothing is simple at this moment in transformational times.
The next and final post in this series will focus on configuration management – a new approach is needed. I don’t have the answers, but I will share some thoughts

A recommended event and an exciting agenda and a good place to validate and share your thoughts.
I will be there and look forward to meeting you at this conference (unfortunate still virtually)


 A final positive remark. The SCAF had renamed itself to SCAF (3DX), showing that even CATIA practices no longer can be considered as a niche – the future of business is to be connected.
A final positive remark. The SCAF had renamed itself to SCAF (3DX), showing that even CATIA practices no longer can be considered as a niche – the future of business is to be connected.

 In particular, SAP has always played the IT card (and is still playing it through their
In particular, SAP has always played the IT card (and is still playing it through their 
 In a modern digital enterprise (to be), the business processes and value streams should be driving the requirements for which systems to use. I was tempted to write “not the IT capabilities”; however, that would be a mistake. We need systems or platforms that are open and able to connect to other systems or platforms. The technology should be there, and more and more, we realize the future is based on connectivity between cloud solutions.
In a modern digital enterprise (to be), the business processes and value streams should be driving the requirements for which systems to use. I was tempted to write “not the IT capabilities”; however, that would be a mistake. We need systems or platforms that are open and able to connect to other systems or platforms. The technology should be there, and more and more, we realize the future is based on connectivity between cloud solutions. When it comes to interactions between two or more platforms, for example, between PLM and ERP, between PLM and IoT, but also between IoT and ERP or IoT and CRM, these interactions should first be based on identified business processes and value streams.
When it comes to interactions between two or more platforms, for example, between PLM and ERP, between PLM and IoT, but also between IoT and ERP or IoT and CRM, these interactions should first be based on identified business processes and value streams. Defining horizontal business processes and value streams independent of the existing IT systems is the biggest challenge in many enterprises. Historically, we have been thinking around a coordinated way of working, meaning people shifting pieces of information between systems – either as files or through interfaces.
Defining horizontal business processes and value streams independent of the existing IT systems is the biggest challenge in many enterprises. Historically, we have been thinking around a coordinated way of working, meaning people shifting pieces of information between systems – either as files or through interfaces. The interfaces need to be data-driven in a digital enterprise; we do not want human interference here, slowing down or modifying the flow. This is the moment Master Data Management and Data Governance comes in.
The interfaces need to be data-driven in a digital enterprise; we do not want human interference here, slowing down or modifying the flow. This is the moment Master Data Management and Data Governance comes in. In the first year, engineers produced the Excel with BOM information and manufacturing engineering imported the Excel into their ERP system. After a year, the manufacturing engineers proposed to automatically upload the Excel as they discovered the exchange process did not need their attention anymore – they learned to trust the data.
In the first year, engineers produced the Excel with BOM information and manufacturing engineering imported the Excel into their ERP system. After a year, the manufacturing engineers proposed to automatically upload the Excel as they discovered the exchange process did not need their attention anymore – they learned to trust the data. Some traditional standards, like the
Some traditional standards, like the 

 In my
In my 
 In the document-based world, a lot of information could be stored in a single file. In a data-driven world, we should define a dataset that contains a specific piece of information, logically belonging together. If we are more precise, a part would have various related datasets that make up the definition of a part. These definitions could be:
In the document-based world, a lot of information could be stored in a single file. In a data-driven world, we should define a dataset that contains a specific piece of information, logically belonging together. If we are more precise, a part would have various related datasets that make up the definition of a part. These definitions could be: They might not be perfect or complete, but inventing your own new standard is a guarantee for legacy issues in the future. This remark is also valid for the software vendors in this domain. A proprietary data model might give you a competitive advantage.
They might not be perfect or complete, but inventing your own new standard is a guarantee for legacy issues in the future. This remark is also valid for the software vendors in this domain. A proprietary data model might give you a competitive advantage. In a data-driven environment, there is no data ownership anymore like you have for documents. The main reason that data ownership can no longer be used is that datasets can be consumed by anyone in the ecosystem. No longer only your department or the manufacturing or service department.
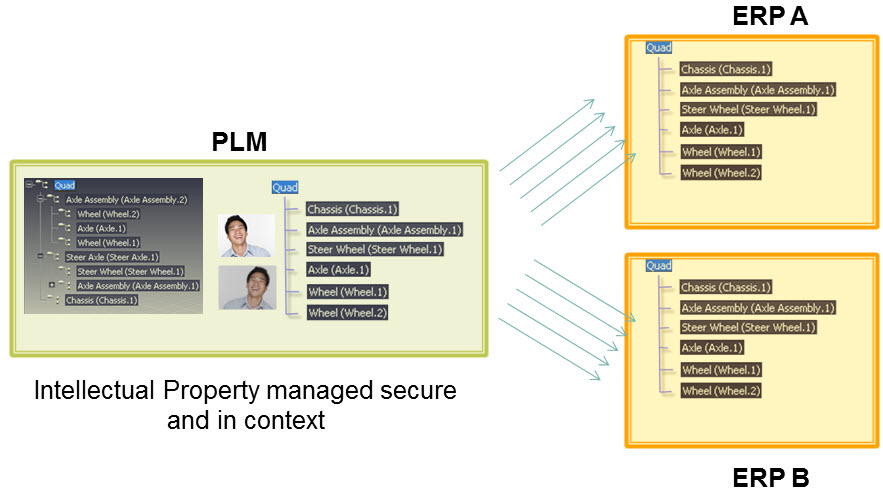
In a data-driven environment, there is no data ownership anymore like you have for documents. The main reason that data ownership can no longer be used is that datasets can be consumed by anyone in the ecosystem. No longer only your department or the manufacturing or service department. It is true that if your data set is too big, you have the challenge of exposing IP when connecting this dataset with others. Therefore, when building a data model, you should make it possible to have datasets pure for internal usage and datasets for sharing.
It is true that if your data set is too big, you have the challenge of exposing IP when connecting this dataset with others. Therefore, when building a data model, you should make it possible to have datasets pure for internal usage and datasets for sharing.

 Interestingly, the brain does not use the “single source of truth”-concept – there can be various “truths” inside a brain. This makes us human beings with all the good and the harmful effects of that.
Interestingly, the brain does not use the “single source of truth”-concept – there can be various “truths” inside a brain. This makes us human beings with all the good and the harmful effects of that.

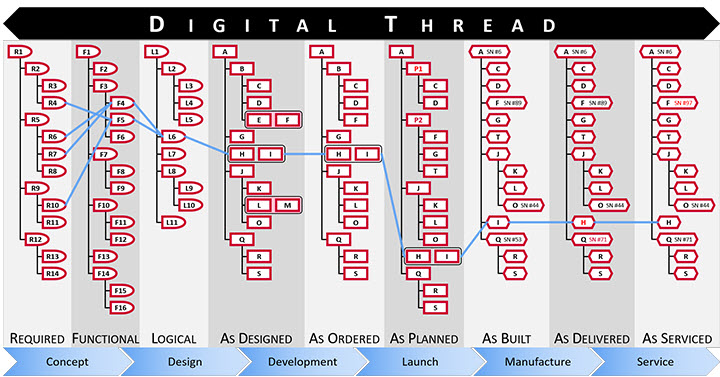
 For traceability and disconnected information exchanges, the left side will be there for many years to come. Systems of Record are needed for data exchange with disconnected suppliers, disconnected regulatory bodies and probably crucial for configuration management.
For traceability and disconnected information exchanges, the left side will be there for many years to come. Systems of Record are needed for data exchange with disconnected suppliers, disconnected regulatory bodies and probably crucial for configuration management.


 The different datasets defining a solution also challenge traditional configuration management processes.
The different datasets defining a solution also challenge traditional configuration management processes.  One of the ideas I am currently exploring is that we need a new layer on top of the current configuration management processes extending the validation to software and services. For example, instead of describing every validated configuration, a company might implement the regular configuration management processes for its hardware.
One of the ideas I am currently exploring is that we need a new layer on top of the current configuration management processes extending the validation to software and services. For example, instead of describing every validated configuration, a company might implement the regular configuration management processes for its hardware.


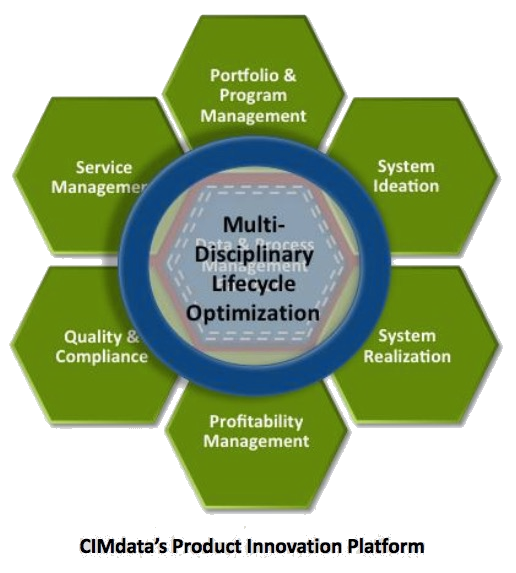
 From these characteristics, it is clear that the underlying infrastructure of a platform must be based on a multitenant SaaS infrastructure, still allowing local data to be connected and shielded for performance or IP reasons.
From these characteristics, it is clear that the underlying infrastructure of a platform must be based on a multitenant SaaS infrastructure, still allowing local data to be connected and shielded for performance or IP reasons.

 A practice we have seen in the construction industry before cloud connectivity became available. However, a so-called end-to-end solution working on PowerPoint implemented in real life requires a lot of human intervention.
A practice we have seen in the construction industry before cloud connectivity became available. However, a so-called end-to-end solution working on PowerPoint implemented in real life requires a lot of human intervention. It might be tempting as a platform provider to add all imaginable data elements to their platform infrastructure as much as possible. The challenge with this approach is whether all data should be stored in a central data environment (preferably cloud) or federated. And what about filtering IP?
It might be tempting as a platform provider to add all imaginable data elements to their platform infrastructure as much as possible. The challenge with this approach is whether all data should be stored in a central data environment (preferably cloud) or federated. And what about filtering IP?

 I have learned from my 25+ years of experience with systems that the original design of a product combined with the vendor’s culture defines the future roadmap. So even if a PLM vendor would rewrite all their software to become data-driven, the ways of working, the assumptions will be based on past experiences.
I have learned from my 25+ years of experience with systems that the original design of a product combined with the vendor’s culture defines the future roadmap. So even if a PLM vendor would rewrite all their software to become data-driven, the ways of working, the assumptions will be based on past experiences. The recent PDT conferences were an example of this, mainly the 2020 Fall conference. Several Aerospace & Defense PLM Action groups reported their progress.
The recent PDT conferences were an example of this, mainly the 2020 Fall conference. Several Aerospace & Defense PLM Action groups reported their progress. I do not believe in the toolkit approach where every company can build its own data model based on its current needs. I have seen this flexibility with SmarTeam in the early days. However, it became an upgrade risk when new, overlapping capabilities were introduced, not matching the past.
I do not believe in the toolkit approach where every company can build its own data model based on its current needs. I have seen this flexibility with SmarTeam in the early days. However, it became an upgrade risk when new, overlapping capabilities were introduced, not matching the past. In addition, a flexible toolkit still requires a robust data model design done by experienced people who have learned from their mistakes.
In addition, a flexible toolkit still requires a robust data model design done by experienced people who have learned from their mistakes. It is essential to realize that a digital transformation in the PLM domain is challenging. No company or vendor has the perfect blueprint available to provide an end-to-end answer for a connected enterprise. In addition, I assume it will take 10 – 20 years till we will be familiar with the concepts.
It is essential to realize that a digital transformation in the PLM domain is challenging. No company or vendor has the perfect blueprint available to provide an end-to-end answer for a connected enterprise. In addition, I assume it will take 10 – 20 years till we will be familiar with the concepts. I often mention a data-driven environment, but what do I mean precisely by that. For me, a data-driven environment means that all information is stored in a dataset that contains a single aspect of information in a standardized manner, so it becomes accessible by outside tools.
I often mention a data-driven environment, but what do I mean precisely by that. For me, a data-driven environment means that all information is stored in a dataset that contains a single aspect of information in a standardized manner, so it becomes accessible by outside tools.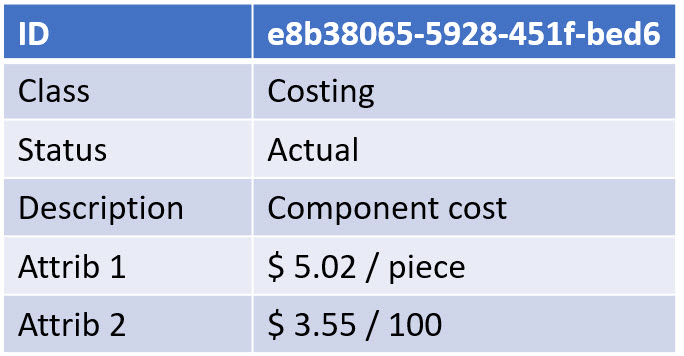
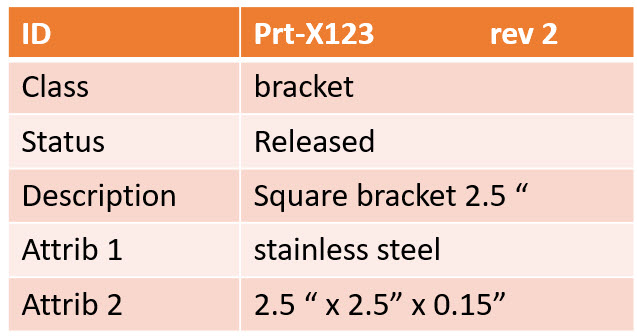







 Now, thanks to digitalization, we can connect and format information in real-time. Now we can provide every stakeholder in the company’s business to have almost real-time visibility on what is happening (if allowed). We have seen the benefits of platformization, where the benefits come from real-time connectivity within an ecosystem.
Now, thanks to digitalization, we can connect and format information in real-time. Now we can provide every stakeholder in the company’s business to have almost real-time visibility on what is happening (if allowed). We have seen the benefits of platformization, where the benefits come from real-time connectivity within an ecosystem. Vendors have already shared their PowerPoints, movies, and demos from how the future would be in the ideal world using their software. The reality, however, is that implementing such solutions requires new business models, a new type of organization and probably new skills.
Vendors have already shared their PowerPoints, movies, and demos from how the future would be in the ideal world using their software. The reality, however, is that implementing such solutions requires new business models, a new type of organization and probably new skills. 
 I hope that some of my readers can help us all further on the path of connected PLM (with a model-based approach). This series of posts will be based on the max size per post (avg 1500 words) and the ideas and contributes coming from you and me.
I hope that some of my readers can help us all further on the path of connected PLM (with a model-based approach). This series of posts will be based on the max size per post (avg 1500 words) and the ideas and contributes coming from you and me.




 It took us more than fifty years to get rid of vellum drawings. It took us more than twenty years to introduce 3D CAD for design and engineering. Still primarily relying on drawings. It will take us for sure one generation to switch from document-based engineering to model-based engineering.
It took us more than fifty years to get rid of vellum drawings. It took us more than twenty years to introduce 3D CAD for design and engineering. Still primarily relying on drawings. It will take us for sure one generation to switch from document-based engineering to model-based engineering.
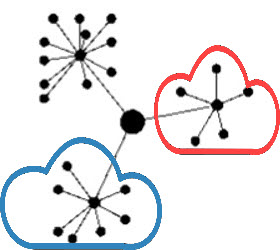

 Making a prototype was, depending on the complexity of the product, the interpretation of the drawings and manufacturability of a product, not always that easy. After a first release, further modifications to the product definition were often marked on the manufacturing drawings using a red pencil. Terms like blueprint and redlining come from the age of paper drawings.
Making a prototype was, depending on the complexity of the product, the interpretation of the drawings and manufacturability of a product, not always that easy. After a first release, further modifications to the product definition were often marked on the manufacturing drawings using a red pencil. Terms like blueprint and redlining come from the age of paper drawings.


 Still, (electronic) drawings were the contractual deliverable when interacting with suppliers and manufacturing. As students were more and more trained with the 3D CAD tools, the traditional art of the draftsman disappeared.
Still, (electronic) drawings were the contractual deliverable when interacting with suppliers and manufacturing. As students were more and more trained with the 3D CAD tools, the traditional art of the draftsman disappeared.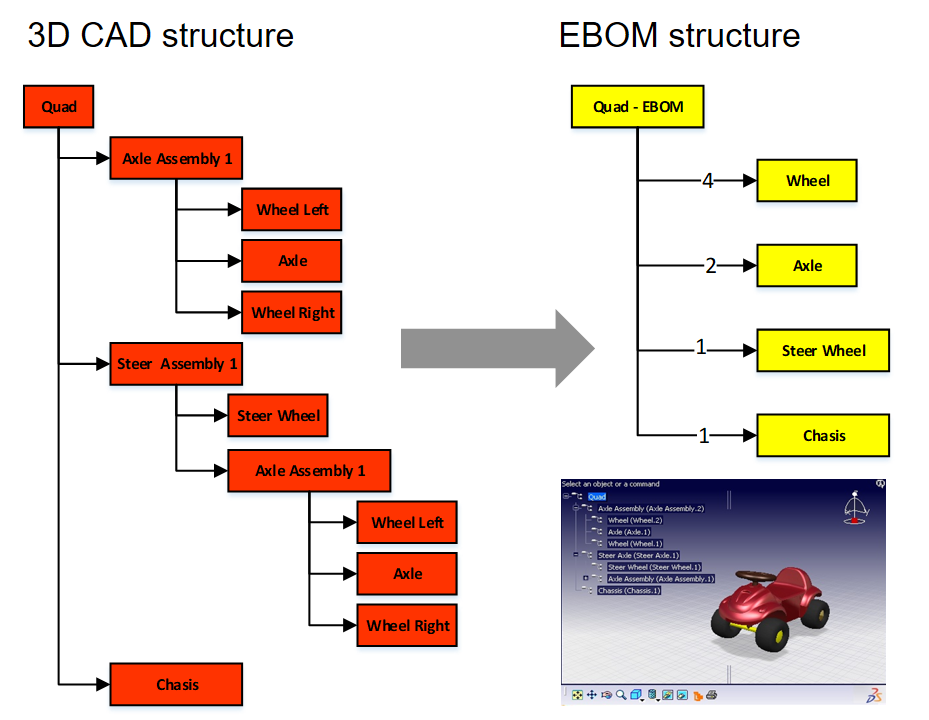



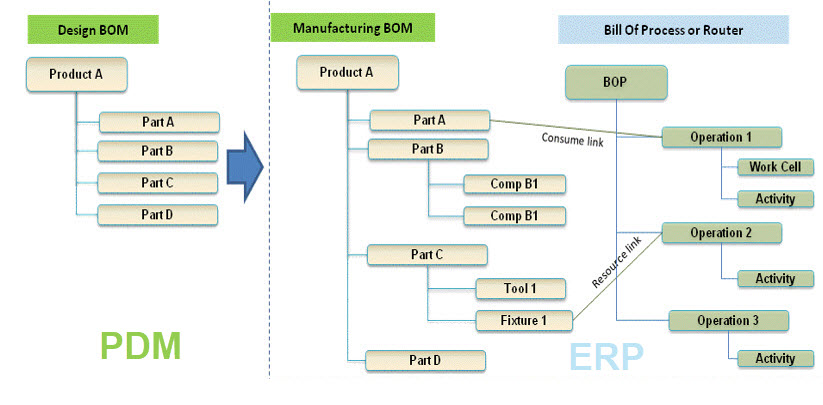



Interesting reflection, Jos. In my experience, the situation you describe is very recognizable. At the company where I work, sustainability…
[…] (The following post from PLM Green Global Alliance cofounder Jos Voskuil first appeared in his European PLM-focused blog HERE.) […]
[…] recent discussions in the PLM ecosystem, including PSC Transition Technologies (EcoPLM), CIMPA PLM services (LCA), and the Design for…
Jos, all interesting and relevant. There are additional elements to be mentioned and Ontologies seem to be one of the…
Jos, as usual, you've provided a buffet of "food for thought". Where do you see AI being trained by a…