
After a summer holiday in the south of Greece, it is time to resume my activities. The south of Crete is largely an analogue environment, far from any digital hype.
 Tempted by LinkedIn posts, I noticed the summer was full of memories, with Martin Eigner sharing 40 years of PLM experience, Oleg Shilovitsky sharing 30 years of PDM Evolution, and Michael Finochario publishing posts on PLM vendors, CAD kernels, and more.
Tempted by LinkedIn posts, I noticed the summer was full of memories, with Martin Eigner sharing 40 years of PLM experience, Oleg Shilovitsky sharing 30 years of PDM Evolution, and Michael Finochario publishing posts on PLM vendors, CAD kernels, and more.
So where do I stand? While digesting all these historical experiences, I reflected on what we can learn from them and what we didn’t learn from them.
It started with technology.
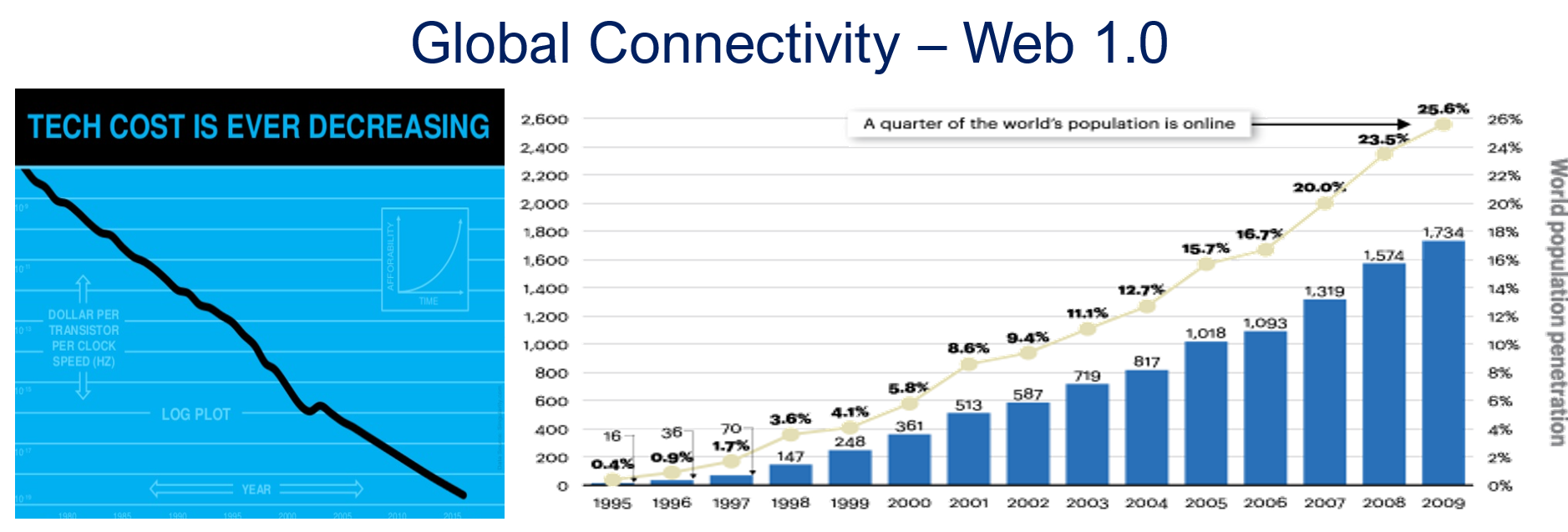
 From 1990 to 1999, I worked with mid-market companies, where data management was the most significant challenge. The introduction of MS Windows made data management more user-friendly, evolving from drawing management systems with version and status management capabilities.
From 1990 to 1999, I worked with mid-market companies, where data management was the most significant challenge. The introduction of MS Windows made data management more user-friendly, evolving from drawing management systems with version and status management capabilities.
Who remembers Automanager Workflow from Cyco, before SmarTeam came on the market?
For that reason, in the early days, PDM was an IT job. As the PDM system primarily dealt with engineering data, it was relatively easy to implement as an organizational change process. We transitioned from analogue to electronic in the department.
Connecting with other systems, particularly ERP, was a serious IT job and a financial challenge. Connecting with other systems, particularly ERP, was a serious IT job and a financial challenge. The rapid decline of IT components, combined with the rapid growth of global connectivity, has created new opportunities for collaboration.
As part of the Dassault/IBM/SmarTeam organization, I explained and taught these new capabilities worldwide.
 In 2008, my VirtualDutchman blog and coaching journey began, evolving from explanations of technology to modern methodologies, which led to organizational change and expectation management – skills not traditionally associated with IT.
In 2008, my VirtualDutchman blog and coaching journey began, evolving from explanations of technology to modern methodologies, which led to organizational change and expectation management – skills not traditionally associated with IT.
Then came digital transformation
With growing connectivity, smartphones and Web 2.0 technology have led to more PLM-like discussions. PLM vendors expanded their scope and developed capabilities beyond mechanical engineering.
 The expansion of capabilities was also the moment when the confusion about the term PLM reached its peak: a PLM strategy or a PLM system?
The expansion of capabilities was also the moment when the confusion about the term PLM reached its peak: a PLM strategy or a PLM system?
At the time, they were largely considered the same in discussions and advertisements..
Meanwhile, digital transformation was occurring at the marketing and sales levels – companies invested in direct communication with their customers through the web.
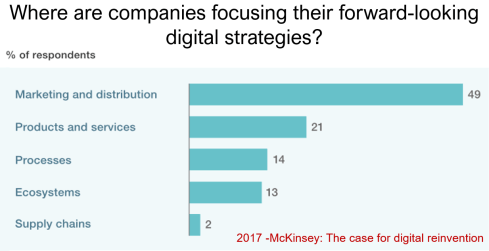
Meanwhile, the internal ways of working for R&D, engineering, and manufacturing did not change significantly. Still, they were following linear processes, and despite the existence of 3D CAD, the 2D drawing remained the primary carrier of legal information between engineering, manufacturing, and suppliers.
Note: the option where the most benefits could be achieved – connected supply chains – had the lowest focus in 2017 – something that would change with COVID-19.
Fundamental digital transformation in the PLM domain occurred gradually. ARAS came with its overlay approach (the platform), connecting various disciplines and enterprise systems. In contrast, Dassault Systèmes introduced its 3DEXPERIENCE platform, utilizing its own software brands as platform components.
The Aras overlay approach
Most PLM vendors rapidly countered Aras’ overlay approach with their low-code offerings based on Mendix, ThingWorx or Netvibes, to enable data flows beyond the traditional PDM scope. The Coordinated Digital Thread was born.
The good news is that PLM has now clearly become a strategy based on a federated system infrastructure. The single PLM system no longer exists, although many of us still use the term’ PLM system’ to refer to the main component of a PLM infrastructure – the System of Record.
Moving to a federated PLM infrastructure is already a challenge for companies, not because of the available technology, but first of all because of the legacy data and, closely related to that, legacy processes and people skills.

Legacy is creating the inertia, not technology!
Next came the cloud – SaaS
 With the availability of cloud solutions that support real-time interactions between stakeholders, either within an enterprise or in a value chain, a new paradigm has emerged: the connected enterprise.
With the availability of cloud solutions that support real-time interactions between stakeholders, either within an enterprise or in a value chain, a new paradigm has emerged: the connected enterprise.
A connected enterprise no longer needs interfaces to transfer data from one system to another.
Instead, with apps and dashboards, combined data from different online sources is presented in a single, user-friendly working environment – A combination of the Systems of Record with the new environments – the Systems of Engagement.
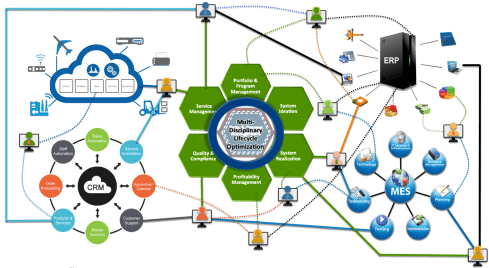
The technology used to create dashboards and apps is based on modern data-driven technologies and principles (ontologies, graph databases, and the semantic web). The Connected Digital Thread was born.
However, legacy systems play an essential role again, as some systems of engagement can be implemented in a complementary manner to the systems of record, allowing companies to work within an integrated technology model.
People will work in a particular mode, either coordinated or connected, but organizations can operate in both modes simultaneously. A story I have been sharing a lot – it is not about migrations but about an evolutionary approach towards an integrated technology model.
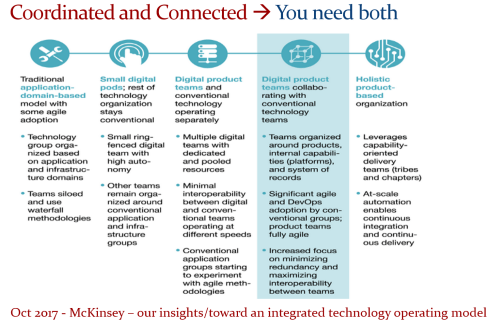
At this point, it becomes essential that business objectives drive the implementation of a PLM infrastructure. Of course, you hear me say we should start from the business; however, the big difference now is that a company should coordinate the technologies, systems, and tools it acquires to avoid isolated islands of information.
Follow Yousef Hooshmand‘s 5 + 1 business transformation steps.

 An open SaaS infrastructure enables a company to let data flow almost in real-time. There is a lot of discussion related to data quality and governance, and if you have missed it, please read these three articles I created together with Rob Feronne, the product Digital PLuMber:
An open SaaS infrastructure enables a company to let data flow almost in real-time. There is a lot of discussion related to data quality and governance, and if you have missed it, please read these three articles I created together with Rob Feronne, the product Digital PLuMber:
- Data Quality and Data Governance – A hype? (part 1)
- Data Quality and Data Governance – the WHY and HOW (part 2)

- Building the Future: Data Quality and Governance in the Digital Age (part 3)
There are some great insights in this dialogue and the associated LinkedIn comments.
Despite the increasing availability of technology, it is the legacy of people, processes, and culture that is hindering progress.
Rob Feronne had a shocking lightbulb moment 😲 in our discussion about the future of PLM, where the participants – see below – answered a question related to the importance of technology in our PLM domain – shocking also for me.
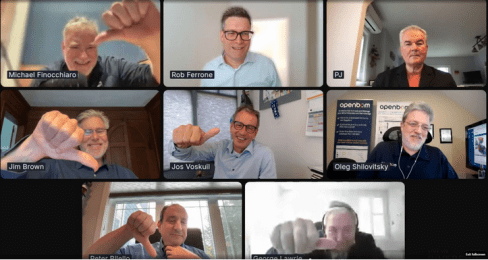
My thumb was up because modern technology matters! The question inspired Oleg Shilovitsky to write a whole blog post on this topic. If you’re truly shocked, read his post, where I agree with the content; the question is too simple to answer with a thumbs up/down.
 As technology has become more accessible than before, you no longer need an IT department to establish a PLM infrastructure. And then indeed, the people and process side needs and deserves much more attention..
As technology has become more accessible than before, you no longer need an IT department to establish a PLM infrastructure. And then indeed, the people and process side needs and deserves much more attention..
And now there is AI
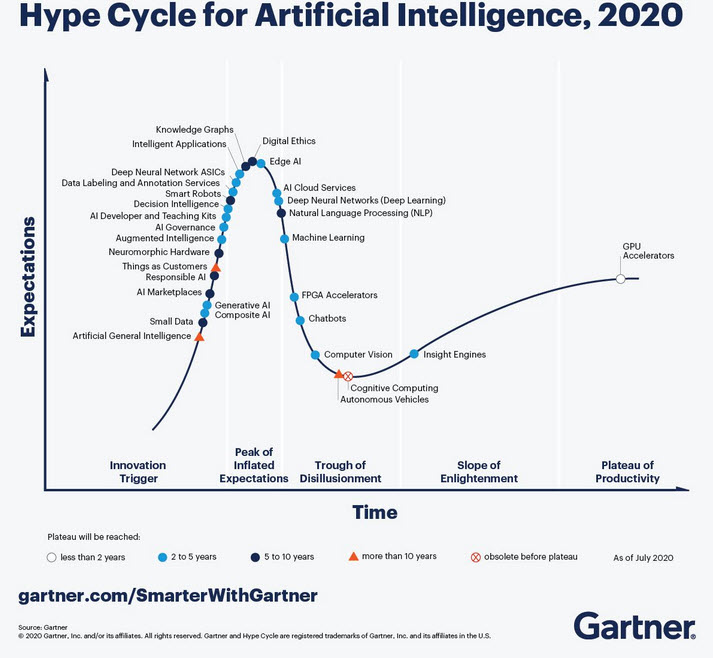 If you haven’t read anything about AI recently, you must be living in an isolated location. Regardless of the business discussions you are following, it is all about the potential of AI.
If you haven’t read anything about AI recently, you must be living in an isolated location. Regardless of the business discussions you are following, it is all about the potential of AI.
Although AI is not a new concept, the fact that various AI capabilities have now reached the end-user level is what drives the hype. Currently, I believe we are at the peak of the hype.
Last week, I participated in an interesting discussion in the series: The Future of PLM moderated by Michael Finochario, this time talking with the analysts. Click on the link to see Michael’s excellent summary and access to the recording of the event.

It was an interesting discussion for a little more than an hour, and the majority of our discussion was about the potential impact of AI on businesses. First, the impact AI can have on the traditional work of an analyst and next, the effects on the PLM domain.
 I believe we agreed that AI at this moment is mainly providing higher user efficiency and performance, very much aligned with the interesting research I have been reading in the MIT NANDA report with the title The GenAI Divide: STATE OF AI IN BUSINESS 2025
I believe we agreed that AI at this moment is mainly providing higher user efficiency and performance, very much aligned with the interesting research I have been reading in the MIT NANDA report with the title The GenAI Divide: STATE OF AI IN BUSINESS 2025
The report’s interesting findings included high adoption of tools but low transformation. Despite significant investment in Generative AI (GenAI), most organizations are not achieving meaningful business transformation.
- 95% of organizations report zero return on GenAI investments.
- Only 5% of integrated AI pilots generate millions in value.
- 80% of organizations have explored or piloted tools like ChatGPT, but these primarily enhance individual productivity.
- 60% of organizations evaluated enterprise-grade systems, but only 20% reached the pilot stage, and just 5% reached production.
- Key barriers include brittle workflows, a lack of contextual learning, and operational misalignment.
Therefore, the question is – Is current AI the next bubble?
In 2014, I wrote about the lack of digital transformation in the PLM domain, and two images (below) from a report by The Economist could be used again. The report can be found here: The Onrushing Wave.
Click on the image to read the 2013 predictions.

I realized that my current job, as a recreational therapist and firefighter at the time, was not at risk, and that some of the predictions from 10 years ago had become a reality. Who is still bothered by telemarketers or retail salespersons?
However, many of the AI symptoms mentioned in the MIT NANDA report are similar to the hype surrounding digital transformation.
The only reservation I have now – will it take a decade before we understand and demonstrate the value of AI, or are we accelerating?
In this context, the upcoming PLM Roadmap/PDT Europe conference on 5 – 6 November will be interesting, as here we will discuss reality.

For a few of you interested in more, there is the day before the conference, a (free) workshop where we will discuss with some thought leaders and experts from various companies how the future of PLM could look like – based on standards, AI tools and more. Click on the image below the conclusion.
Conclusion
The summertime was a nice moment to reflect, inspired by others in my network. What is clear is that there is a shift from technology towards people and change. The rapid expansion of AI tools, along with connected technologies, has created an overwhelming array of possibilities. Now it is time for business leadership to understand them and utilize them for significant business improvement, where the fear is that substantial change will always be slowed down by organizational inertia.

 In the past three weeks, between some short holidays, I had a discussion with
In the past three weeks, between some short holidays, I had a discussion with  Rob, I was curious whether there were any interesting comments from the readers that enhanced your understanding. For me,
Rob, I was curious whether there were any interesting comments from the readers that enhanced your understanding. For me,  It’s easy to imagine a Digital Thread, but building one that’s sustainable and delivers measurable value is a far more formidable challenge.
It’s easy to imagine a Digital Thread, but building one that’s sustainable and delivers measurable value is a far more formidable challenge.

 However, this conference also created the opportunity to have a pre-conference workshop, where
However, this conference also created the opportunity to have a pre-conference workshop, where 
 Mark the date and this workshop in your agenda if you are able and willing to contribute. After the summer holidays, we will develop a more detailed agenda about the concepts to be discussed. Stay tuned to our LinkedIn feed at the end of August/beginning of September.
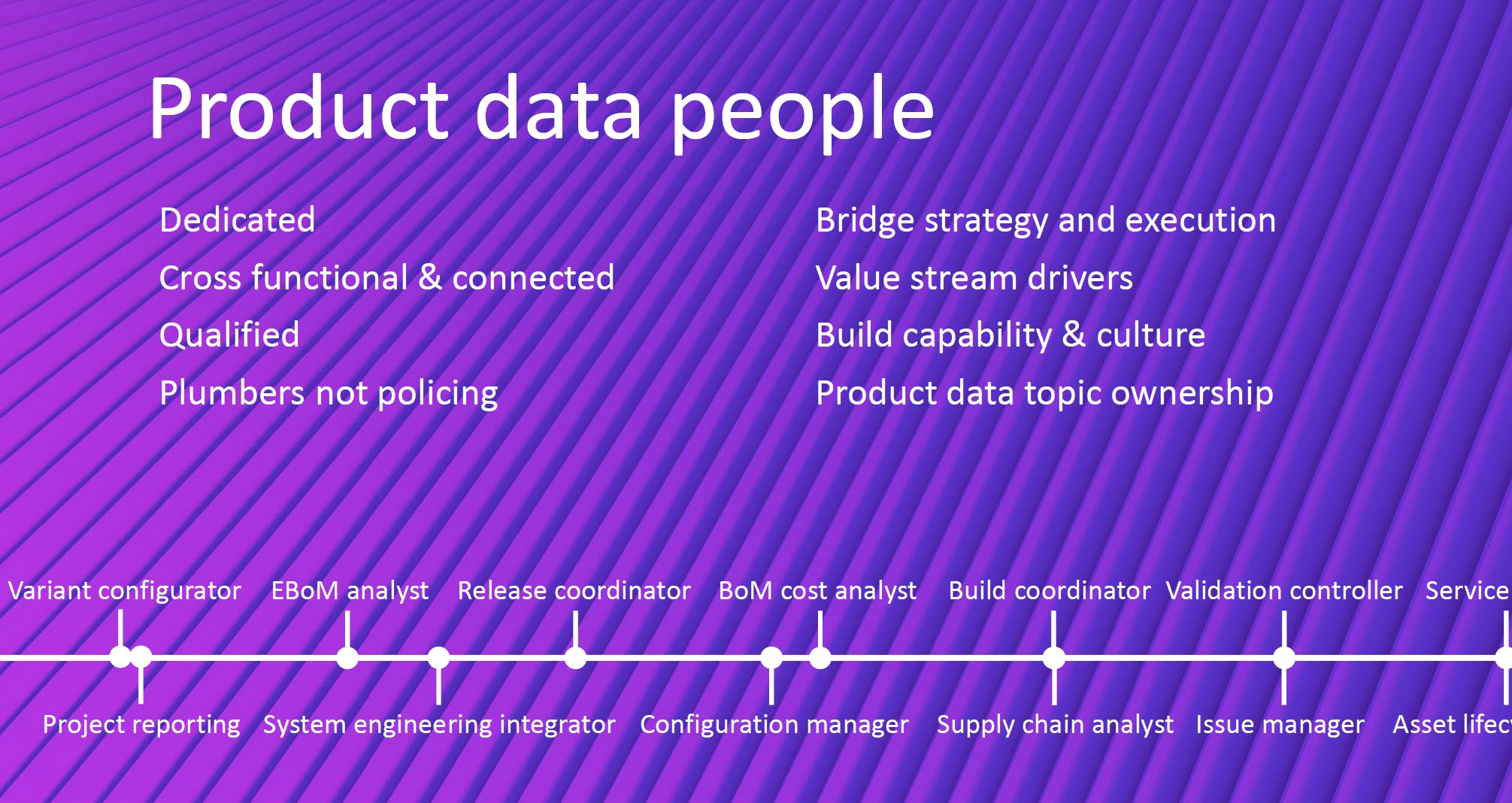
Mark the date and this workshop in your agenda if you are able and willing to contribute. After the summer holidays, we will develop a more detailed agenda about the concepts to be discussed. Stay tuned to our LinkedIn feed at the end of August/beginning of September.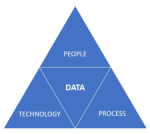 Data needs to be an integral, essential and valuable part of the product or service. Individuals become both consumers and producers of data, expected to input clean data, interpret dashboards, and act on insights. In a business where people collaborate across boundaries, ask questions, and share insight, data becomes a competitive asset.
Data needs to be an integral, essential and valuable part of the product or service. Individuals become both consumers and producers of data, expected to input clean data, interpret dashboards, and act on insights. In a business where people collaborate across boundaries, ask questions, and share insight, data becomes a competitive asset. Here it is critical that leaders truly believe in the value and set the tone, and because it rare to have everyone in the business care about the data as passionately as they do about the prime function of their unique role (e.g. designer);
Here it is critical that leaders truly believe in the value and set the tone, and because it rare to have everyone in the business care about the data as passionately as they do about the prime function of their unique role (e.g. designer);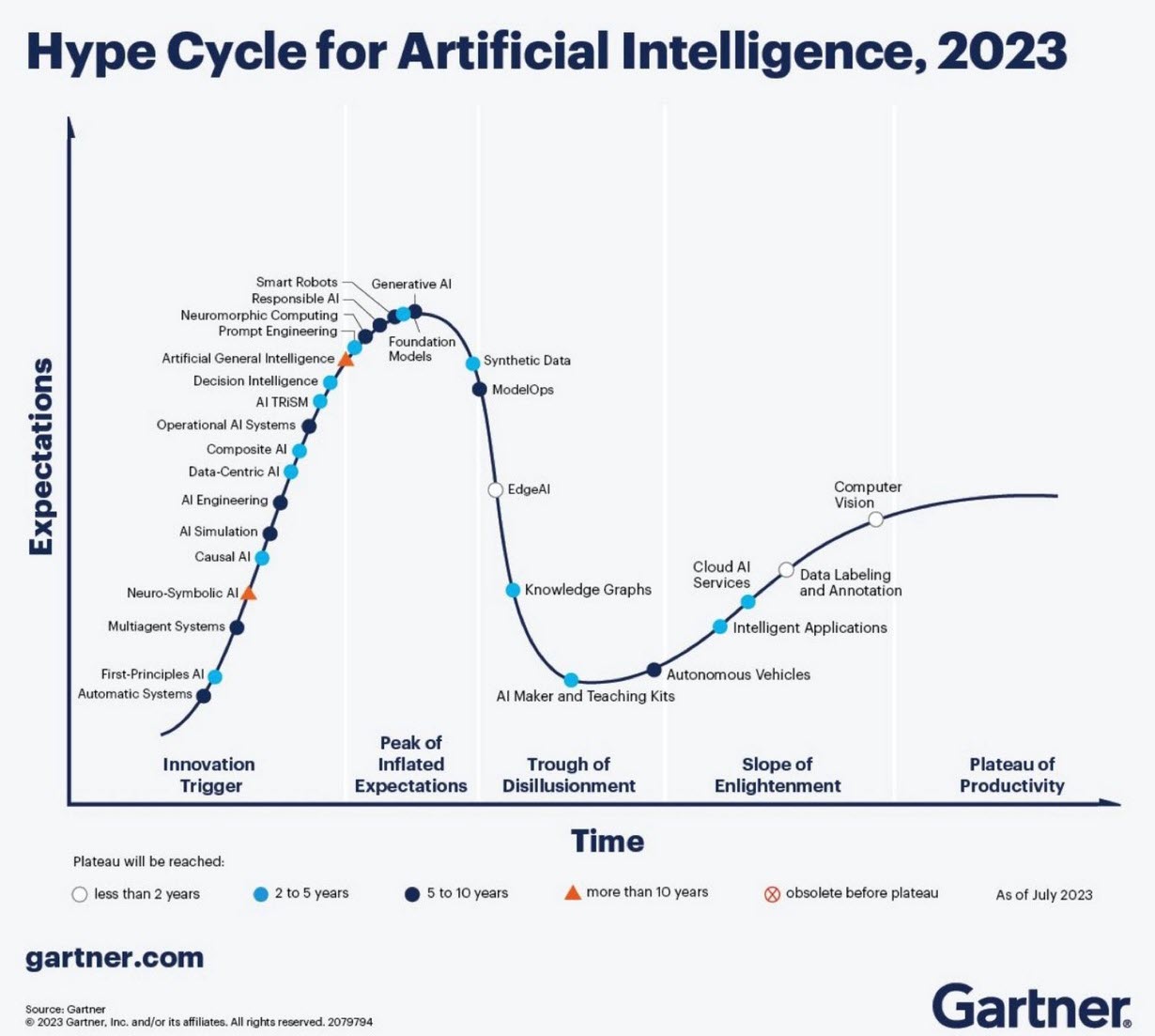



 Rob, did you receive any feedback related to part 1? I spoke with a company that emphasized the importance of data quality; however, they were more interested in applying plasters, as they consider a broader approach too disruptive to their current business. Do you see similar situations?
Rob, did you receive any feedback related to part 1? I spoke with a company that emphasized the importance of data quality; however, they were more interested in applying plasters, as they consider a broader approach too disruptive to their current business. Do you see similar situations? Honestly, not much feedback. Data Governance isn’t as sexy or exciting as discussions on Designing, Engineering, Manufacturing, or PLM Technology. HOWEVER, as the saying goes, all roads lead to Rome, and all Digital Engineering discussions ultimately lead to data.
Honestly, not much feedback. Data Governance isn’t as sexy or exciting as discussions on Designing, Engineering, Manufacturing, or PLM Technology. HOWEVER, as the saying goes, all roads lead to Rome, and all Digital Engineering discussions ultimately lead to data.
 Designing effective data governance involves tailoring foundational elements, including data stewardship, standards, lineage, metadata, glossaries, and quality rules. These elements must reflect the realities of operations, striking a balance between trade-offs such as speed versus rigor or openness versus control.
Designing effective data governance involves tailoring foundational elements, including data stewardship, standards, lineage, metadata, glossaries, and quality rules. These elements must reflect the realities of operations, striking a balance between trade-offs such as speed versus rigor or openness versus control.


 AI also offers enormous potential for data quality and governance. From live monitoring to proactive guidance, adopting this approach will become a much easier business strategy. One can imagine AI forming the core of a company’s Digital Thread—no longer requiring rigidly hardwired systems and data flows, but instead intelligently comparing team data and flagging misalignments.
AI also offers enormous potential for data quality and governance. From live monitoring to proactive guidance, adopting this approach will become a much easier business strategy. One can imagine AI forming the core of a company’s Digital Thread—no longer requiring rigidly hardwired systems and data flows, but instead intelligently comparing team data and flagging misalignments. Experts define quality rules (completeness, consistency, relationship integrity), and AI enables automated anomaly detection. Initially, humans triage issues, but over time, as trust in AI grows, more of the process can be automated. Eventually, no oversight may be needed; alerts could be sent directly to those empowered to act, whether human or AI.
Experts define quality rules (completeness, consistency, relationship integrity), and AI enables automated anomaly detection. Initially, humans triage issues, but over time, as trust in AI grows, more of the process can be automated. Eventually, no oversight may be needed; alerts could be sent directly to those empowered to act, whether human or AI.

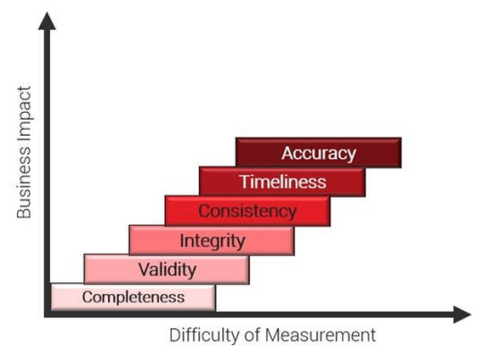
 While defining quality is one challenge, detecting issues is another. Data quality problems vary in severity and detection difficulty, and their importance can shift depending on the development stage. It’s vital not to prioritize one measure over others, e.g., having timely data doesn’t guarantee that it has been validated.
While defining quality is one challenge, detecting issues is another. Data quality problems vary in severity and detection difficulty, and their importance can shift depending on the development stage. It’s vital not to prioritize one measure over others, e.g., having timely data doesn’t guarantee that it has been validated. Data governance typically evolves; it’s challenging to implement from the start. Organizations must understand their operations before they can govern data effectively.
Data governance typically evolves; it’s challenging to implement from the start. Organizations must understand their operations before they can govern data effectively.

 Human behavior is primarily emotional. A lesson valuable in the PLM domain and
Human behavior is primarily emotional. A lesson valuable in the PLM domain and 

 Companies now face regulatory pressure such as
Companies now face regulatory pressure such as 
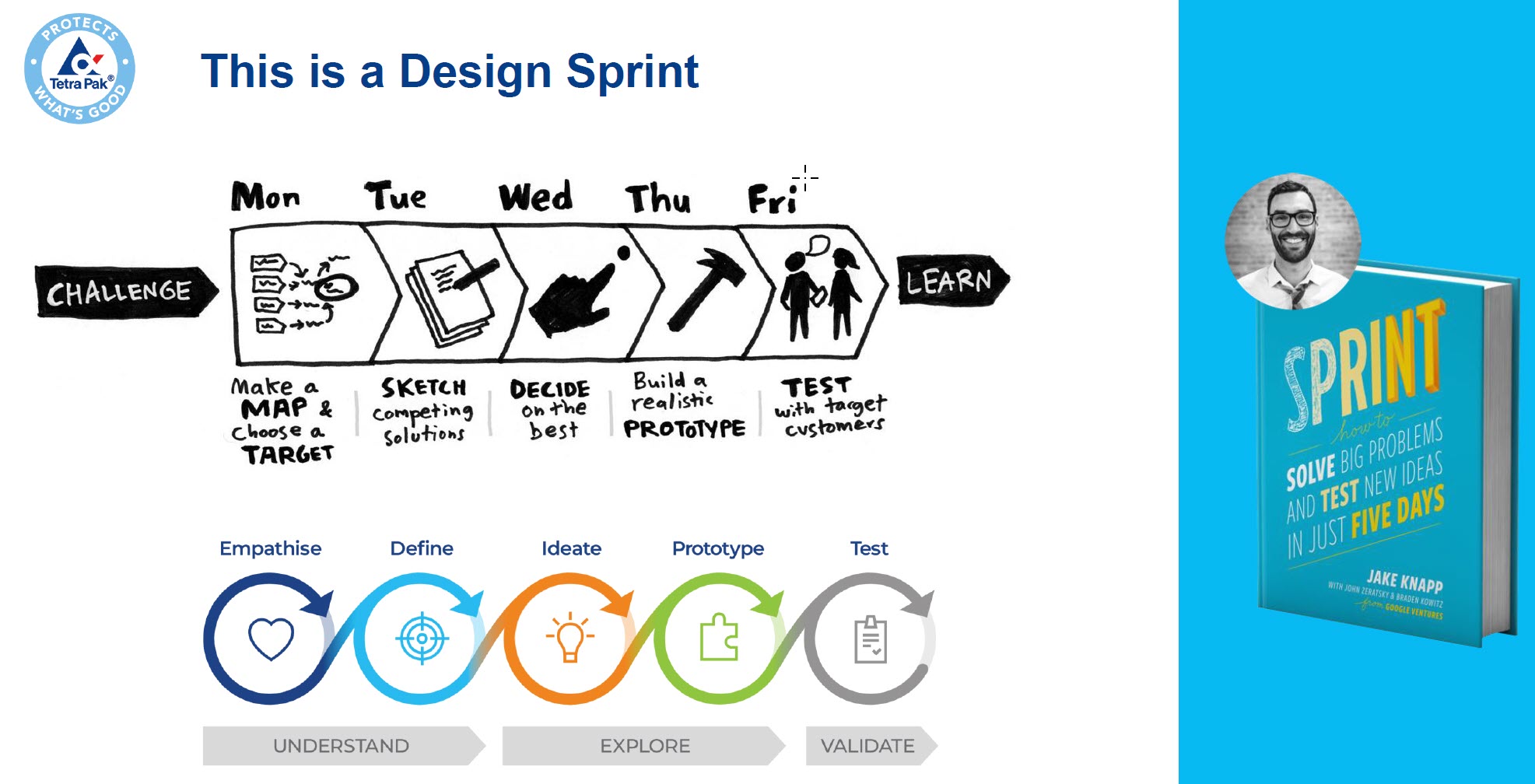
 I noticed discomfort in smaller, closed-company sessions, some attendees said, “We’re far from that vision. ”
I noticed discomfort in smaller, closed-company sessions, some attendees said, “We’re far from that vision. ” 










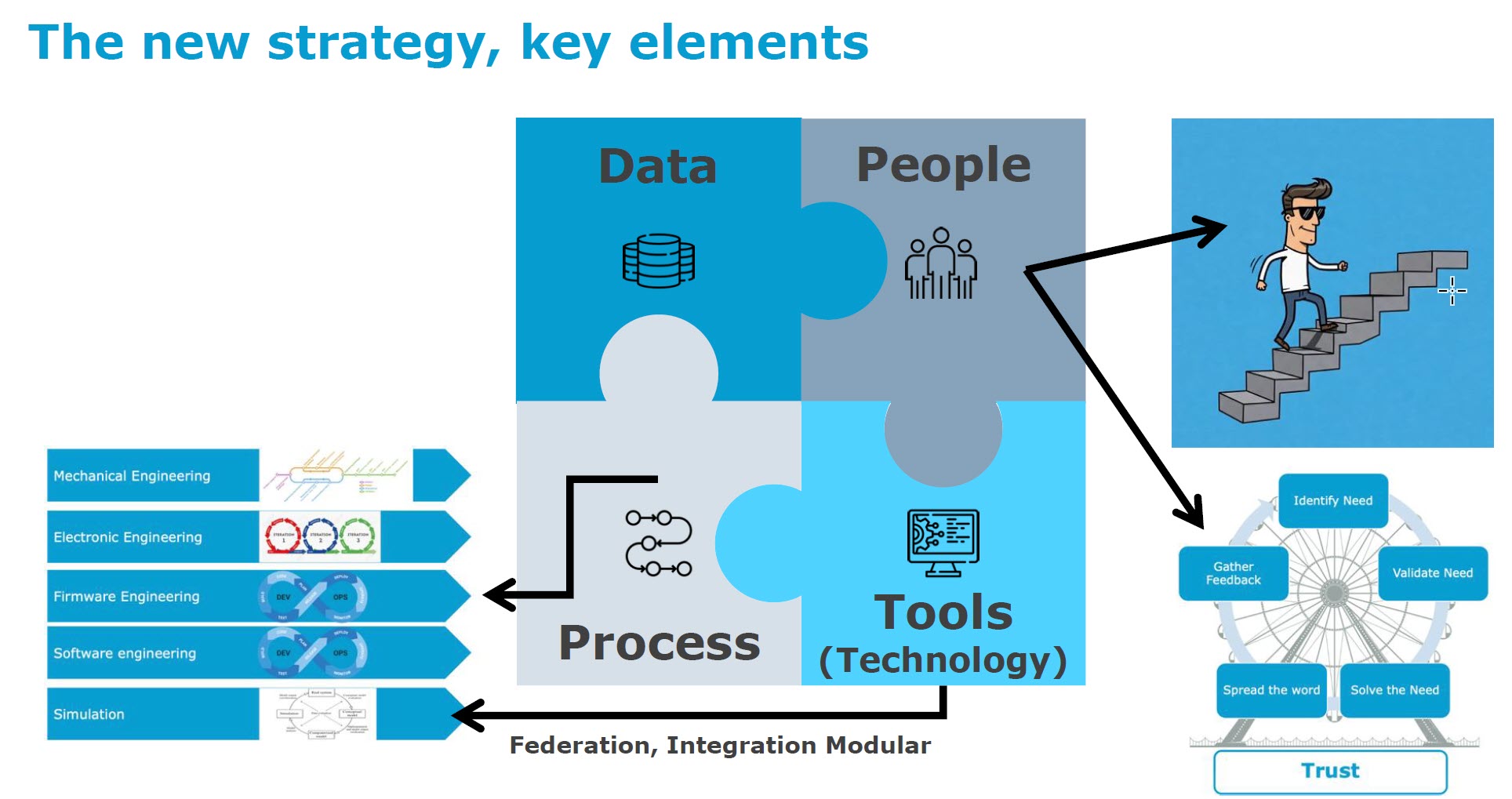






 If you are connected to the LinkedIn posts in my PLM feed, you might have the impression that everyone is gearing up for modern PLM. Articles often created with AI support spark vivid discussions. Before diving into them with my perspective, I want to set the scene by explaining what I mean by modern PLM and traditional PLM.
If you are connected to the LinkedIn posts in my PLM feed, you might have the impression that everyone is gearing up for modern PLM. Articles often created with AI support spark vivid discussions. Before diving into them with my perspective, I want to set the scene by explaining what I mean by modern PLM and traditional PLM.
 The coordinated approach fits people working within their authoring tools and, through integrations, sharing data. The PLM system becomes a system of record, and working in a system of record is not designed to be user-friendly.
The coordinated approach fits people working within their authoring tools and, through integrations, sharing data. The PLM system becomes a system of record, and working in a system of record is not designed to be user-friendly. When I talk about modern PLM, it is no longer about a single system. Modern PLM starts from a business strategy implemented by a data-driven infrastructure. The strategy part remains a challenge at the board level: how do you translate PLM capabilities into business benefits – the WHY?
When I talk about modern PLM, it is no longer about a single system. Modern PLM starts from a business strategy implemented by a data-driven infrastructure. The strategy part remains a challenge at the board level: how do you translate PLM capabilities into business benefits – the WHY?


 Despite the considerable legacy pressure there are already companies implementing a coordinated and connected approach. An excellent description of a potential approach comes from
Despite the considerable legacy pressure there are already companies implementing a coordinated and connected approach. An excellent description of a potential approach comes from  So far in this article, I have not mentioned AI as the solution to all our challenges. I see an analogy here with the introduction of the smartphone. 2008 was the moment that platforms were introduced, mainly for consumers. Airbnb, Uber, Amazon, Spotify, and Netflix have appeared and disrupted the traditional ways of selling products and services.
So far in this article, I have not mentioned AI as the solution to all our challenges. I see an analogy here with the introduction of the smartphone. 2008 was the moment that platforms were introduced, mainly for consumers. Airbnb, Uber, Amazon, Spotify, and Netflix have appeared and disrupted the traditional ways of selling products and services. In our PLM domain, it took more than 10 years for platforms to become a topic of discussion for businesses. The 2015 PLM Roadmap/PDT conference was the first step in discussing the Product Innovation Platform – see my
In our PLM domain, it took more than 10 years for platforms to become a topic of discussion for businesses. The 2015 PLM Roadmap/PDT conference was the first step in discussing the Product Innovation Platform – see my 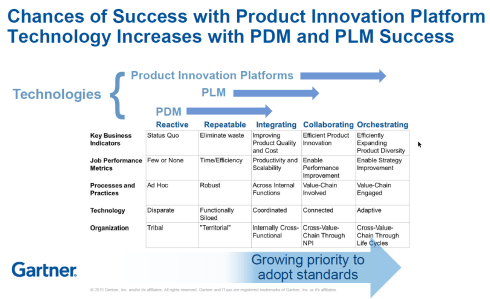





 The intention is, as mentioned, to share experiences and discuss challenges within the group. It will be a private group where people can discuss openly to avoid any business conflicts. The plan is to start with an initial kick-off Zoom meeting in June the date still to be fixed.
The intention is, as mentioned, to share experiences and discuss challenges within the group. It will be a private group where people can discuss openly to avoid any business conflicts. The plan is to start with an initial kick-off Zoom meeting in June the date still to be fixed.
 In the last two weeks, I have had mixed discussions related to PLM, where I realized the two different ways people can look at PLM. Are implementing PLM capabilities driven by a cost-benefit analysis and a business case? Or is implementing PLM capabilities driven by strategy providing business value for a company?
In the last two weeks, I have had mixed discussions related to PLM, where I realized the two different ways people can look at PLM. Are implementing PLM capabilities driven by a cost-benefit analysis and a business case? Or is implementing PLM capabilities driven by strategy providing business value for a company?

 The biggest obstacle I have discovered is that people relate PLM to a system or, even worse, to an engineering tool. This 20-year-old misunderstanding probably comes from the fact that in the past, implementing PLM was more an IT activity – providing the best support for engineers and their data – than a business-driven set of capabilities needed to support the product lifecycle.
The biggest obstacle I have discovered is that people relate PLM to a system or, even worse, to an engineering tool. This 20-year-old misunderstanding probably comes from the fact that in the past, implementing PLM was more an IT activity – providing the best support for engineers and their data – than a business-driven set of capabilities needed to support the product lifecycle. At the management level, the financial data coming from the ERP system drives the business. ERP systems are transactional and can provide real-time data about the company’s performance. C-level management wants to be sure they can see what is happening, so there is a massive focus on implementing the best ERP system.
At the management level, the financial data coming from the ERP system drives the business. ERP systems are transactional and can provide real-time data about the company’s performance. C-level management wants to be sure they can see what is happening, so there is a massive focus on implementing the best ERP system. Why would you invest in PLM? Although the ERP engine will slow down without proper PLM, the complexity of PLM compared to ERP is a reason for management to look at the costs, as the PLM benefits are hard to grasp and depend on so much more than just execution.
Why would you invest in PLM? Although the ERP engine will slow down without proper PLM, the complexity of PLM compared to ERP is a reason for management to look at the costs, as the PLM benefits are hard to grasp and depend on so much more than just execution. It is clear that when we accept the modern definition of PLM, we should be considering product lifecycle management as the management of the product lifecycle (as
It is clear that when we accept the modern definition of PLM, we should be considering product lifecycle management as the management of the product lifecycle (as  I cannot believe that, although perhaps not fully understood, the importance of a data-driven approach will be discussed at many strategic board meetings. A data-driven approach is needed to implement a digital thread as the foundation for enhanced business models based on digital twins and to ensure data quality and governance supporting AI initiatives.
I cannot believe that, although perhaps not fully understood, the importance of a data-driven approach will be discussed at many strategic board meetings. A data-driven approach is needed to implement a digital thread as the foundation for enhanced business models based on digital twins and to ensure data quality and governance supporting AI initiatives.
 The real benefits come from doing things differently, and technology allows you to do it differently. However, this requires people to work differently, too, and this is the most common mistake in transformational projects.
The real benefits come from doing things differently, and technology allows you to do it differently. However, this requires people to work differently, too, and this is the most common mistake in transformational projects. People are squeezed into an ideal performance without taking them on the journey. For that reason, it is essential to build a compelling story that motivates individuals to join the transformation. Assisting companies in building compelling story lines is one of the areas where I specialize.
People are squeezed into an ideal performance without taking them on the journey. For that reason, it is essential to build a compelling story that motivates individuals to join the transformation. Assisting companies in building compelling story lines is one of the areas where I specialize.



Hi Jos, Knowing your background in methodology and education, I wanted to share a longer article with you: “What is…
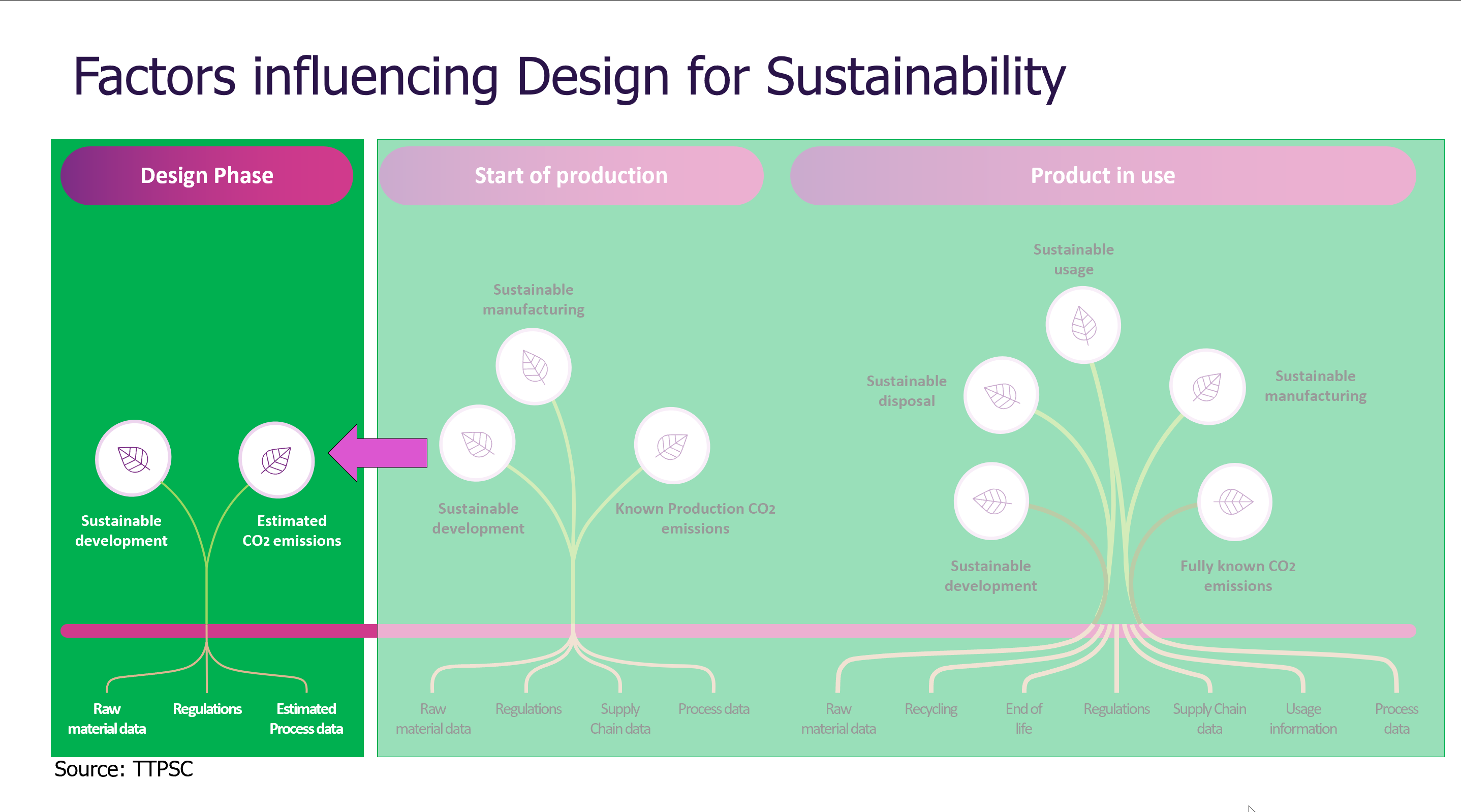
Interesting reflection, Jos. In my experience, the situation you describe is very recognizable. At the company where I work, sustainability…
[…] (The following post from PLM Green Global Alliance cofounder Jos Voskuil first appeared in his European PLM-focused blog HERE.) […]
[…] recent discussions in the PLM ecosystem, including PSC Transition Technologies (EcoPLM), CIMPA PLM services (LCA), and the Design for…
Jos, all interesting and relevant. There are additional elements to be mentioned and Ontologies seem to be one of the…