
You are currently browsing the category archive for the ‘Data Quality’ category.
 In the past three weeks, between some short holidays, I had a discussion with Rob Ferrone, who you might know as
In the past three weeks, between some short holidays, I had a discussion with Rob Ferrone, who you might know as
“The original product Data PLuMber”.
Our discussion resulted in this concluding post and these two previous posts:
If you haven’t read them before, please take a moment to review them, to understand the flow of our dialogue and to get a full, holistic view of the WHY, WHAT and HOW of data quality and data governance.
A foundation required for any type of modern digital enterprise, with or without AI.
A first feedback round
 Rob, I was curious whether there were any interesting comments from the readers that enhanced your understanding. For me, Benedict Smith’s point in the discussion thread was an interesting one.
Rob, I was curious whether there were any interesting comments from the readers that enhanced your understanding. For me, Benedict Smith’s point in the discussion thread was an interesting one.
From this reaction, I like to quote:
To suggest it’s merely a lack of discipline is to ignore the evidence. We have some of the most disciplined engineers in the world. The problem isn’t the people; it’s the architecture they are forced to inhabit.
My contention is that we have been trying to solve a reasoning problem with record-keeping tools. We need to stop just polishing the records and start architecting for the reasoning. The “what” will only ever be consistently correct when the “why” finally has a home. 😎
Here, I realized that the challenge is not only about moving From Coordinated to Coordinated and Connected, but also that our existing record-keeping mindset drives the old way of thinking about data. In the long term, this will be a dead end.
What did you notice?
 Jos, indeed, Benedict’s point is great to have in mind for the future and in addition, I also liked the comment from Yousef Hooshmand, where he explains that a data-driven approach with a much higher data granularity automatically leads to a higher quality – I would quote Yousef:
Jos, indeed, Benedict’s point is great to have in mind for the future and in addition, I also liked the comment from Yousef Hooshmand, where he explains that a data-driven approach with a much higher data granularity automatically leads to a higher quality – I would quote Yousef:
The current landscapes are largely application-centric and not data-centric, so data is often treated as a second or even third-class citizen.
In contrast, a modern federated and semantic architecture is inherently data-centric. This shift naturally leads to better data quality with significantly less overhead. Just as important, data ownership becomes clearly defined and aligned with business responsibilities.
Take “weight” as a simple example: we often deal with “Target Weight,” “Calculated Weight,” and “Measured Weight.” In a federated, semantic setup, these attributes reside in the systems where their respective data owners (typically the business users) work daily, and are semantically linked in the background.
I believe the interesting part of this discussion is that people are thinking about data-driven concepts as a foundation for the paradigm, shifting from systems of record/systems of engagement to systems of reasoning. Additionally, I see how Yousef applies a data-centric approach in his current enterprise, laying the foundation for systems of reasoning.
What’s next?
Rob, your recommendations do not include a transformation, but rather an evolution to become better and more efficient – the typical work of a Product PLuMber, I would say. How about redesigning the way we work?
Bold visions and ideas are essential catalysts for transformations, but I’ve found that the execution of significant, strategic initiatives is often the failure mode.
One of my favourite quotes is:
“A complex system that works is invariably found to have evolved from a simple system that worked.”
John Gall, Systemantics (1975)
For example, I advocate this approach when establishing Digital Threads.
 It’s easy to imagine a Digital Thread, but building one that’s sustainable and delivers measurable value is a far more formidable challenge.
It’s easy to imagine a Digital Thread, but building one that’s sustainable and delivers measurable value is a far more formidable challenge.
Therefore, my take on Digital Thread as a Service is not about a plug-and-play Digital Thread, but the Service of creating valuable Digital Threads.
You achieve the solution by first making the Thread work and progressively ‘leaving a trail of construction’.
The caveat is that this can’t happen in isolation; it must be aligned with a data strategy, a set of principles, and a roadmap that are grounded in the organization’s strategic business imperatives.
Your answer relates a lot to Steef Klein’s comment when he discussed: “Industry 4.0: Define your Digital Thread ML-related roadmap – Carefully select your digital innovation steps.” You can read Steef’s full comment here: Your architectural Industry 4.0 future)
First, I liked the example value cases presented by Steef. They’re a reminder that all these technology-enabled strategies, whether PLM, Digital Thread, or otherwise, are just means to an end. That end is usually growth or financial performance (and hopefully, one day, people too).
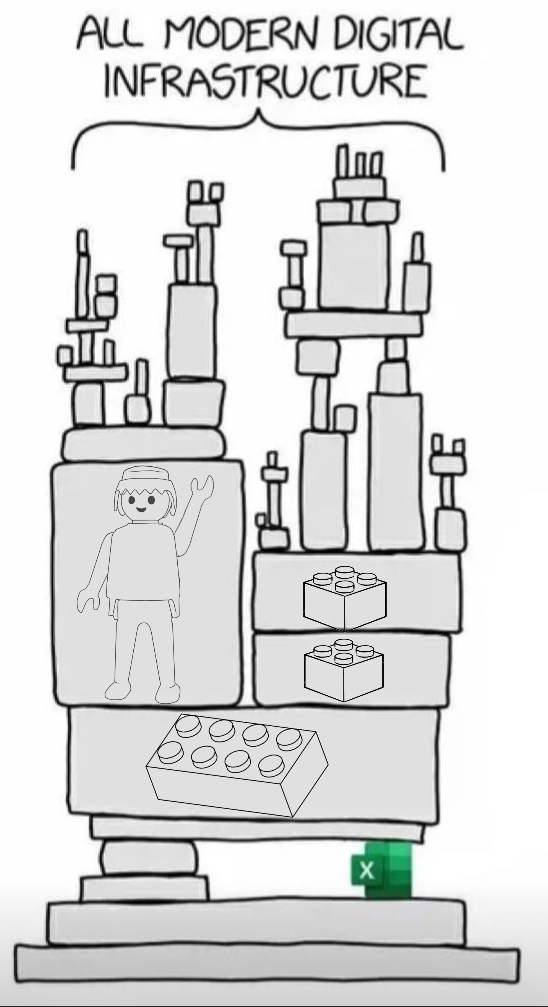 It is a bit like Lego, however. You can’t build imaginative but robust solutions unless there is underlying compatibility and interoperability.
It is a bit like Lego, however. You can’t build imaginative but robust solutions unless there is underlying compatibility and interoperability.
It would be a wobbly castle made from a mix of Playmobil, Duplo, Lego and wood blocks (you can tell I have been doing childcare this summer – click on the image to see the details).
As the lines blur between products, services, and even companies themselves, effective collaboration increasingly depends on a shared data language, one that can be understood not just by people, but by the microservices and machines driving automation across ecosystems.
Discussing the future?
 I think that for those interested in this discussion, I would like to point to the upcoming PLM Roadmap/PDT Europe 2025 conference on November 5th and 6th in Paris, where some of the thought leaders in these concepts will be presenting or attending. The detailed agenda is expected to be published after the summer holidays.
I think that for those interested in this discussion, I would like to point to the upcoming PLM Roadmap/PDT Europe 2025 conference on November 5th and 6th in Paris, where some of the thought leaders in these concepts will be presenting or attending. The detailed agenda is expected to be published after the summer holidays.
 However, this conference also created the opportunity to have a pre-conference workshop, where Håkan Kårdén and I wanted to have an interactive discussion with some of these thought leaders and practitioners from the field.
However, this conference also created the opportunity to have a pre-conference workshop, where Håkan Kårdén and I wanted to have an interactive discussion with some of these thought leaders and practitioners from the field.
![]() Sponsored by the Arrowhead fPVN project, we were able to book a room at the conference venue in the afternoon of November 4th. You can find the announcement and more details of the workshop here in Hakan’s post:. Shape the Future of PLM – Together.
Sponsored by the Arrowhead fPVN project, we were able to book a room at the conference venue in the afternoon of November 4th. You can find the announcement and more details of the workshop here in Hakan’s post:. Shape the Future of PLM – Together.
Last year at the PLM Roadmap PDT Europe conference in Gothenburg, I saw a presentation of the Arrowhead fPVN project. You can read more here: The long week after the PLM Roadmap/PDT Europe 2024 conference.
And, as you can see from the acknowledged participants below, we want to discuss and understand more concepts and their applications – and for sure, the application of AI concepts will be part of the discussion.

 Mark the date and this workshop in your agenda if you are able and willing to contribute. After the summer holidays, we will develop a more detailed agenda about the concepts to be discussed. Stay tuned to our LinkedIn feed at the end of August/beginning of September.
Mark the date and this workshop in your agenda if you are able and willing to contribute. After the summer holidays, we will develop a more detailed agenda about the concepts to be discussed. Stay tuned to our LinkedIn feed at the end of August/beginning of September.
And the people?
Rob, we just came from a human-centric PLM conference in Jerez – the Share PLM 2025 summit – where are the humans in this data-driven world?
You can’t have a data-driven strategy in isolation. A business operating system comprises the coordinated interaction of people, processes, systems, and data, aligned to the lifecycle of products and services. Strategies should be defined at each layer, for instance, whether the system landscape is federated or monolithic, with each strategy reinforcing and aligning with the broader operating system vision.
In terms of the people layer, a data strategy is only as good as the people who shape, feed, and use it. Systems don’t generate clean data; people do. If users aren’t trained, motivated, or measured on quality, the strategy falls apart.
 Data needs to be an integral, essential and valuable part of the product or service. Individuals become both consumers and producers of data, expected to input clean data, interpret dashboards, and act on insights. In a business where people collaborate across boundaries, ask questions, and share insight, data becomes a competitive asset.
Data needs to be an integral, essential and valuable part of the product or service. Individuals become both consumers and producers of data, expected to input clean data, interpret dashboards, and act on insights. In a business where people collaborate across boundaries, ask questions, and share insight, data becomes a competitive asset.
There are risks; however, a system-driven approach can clash with local flexibility/agility.
People who previously operated on instinct or informal processes may now need to justify actions with data. And if the data is poor or the outputs feel misaligned, people will quickly disengage, reverting to offline workarounds or intuition.
 Here it is critical that leaders truly believe in the value and set the tone, and because it rare to have everyone in the business care about the data as passionately as they do about the prime function of their unique role (e.g. designer);
Here it is critical that leaders truly believe in the value and set the tone, and because it rare to have everyone in the business care about the data as passionately as they do about the prime function of their unique role (e.g. designer);
therefore there needs to be product data professionals in the mix – people who care, notice what’s wrong, and know how to fix it across silos.
Conclusion
- Our discussions on data quality and governance revealed a crucial insight: this is not a technical journey, but a human one. While the industry is shifting from systems of record to systems of reasoning, many organizations are still trapped in record-keeping mindsets and fragmented architectures. Better tools alone won’t fix the issue—we need better ownership, strategy, and engagement.
- True data quality isn’t about being perfect; it’s about the right maturity, at the right time, for the right decisions. Governance, too, isn’t a checkbox—it’s a foundation for trust and continuity. The transition to a data-centric way of working is evolutionary, not revolutionary—requiring people who understand the business, care about the data, and can work across silos.
The takeaway? Start small, build value early, and align people, processes, and systems under a shared strategy. And if you’re serious about your company’s data, join the dialogue in Paris this November.
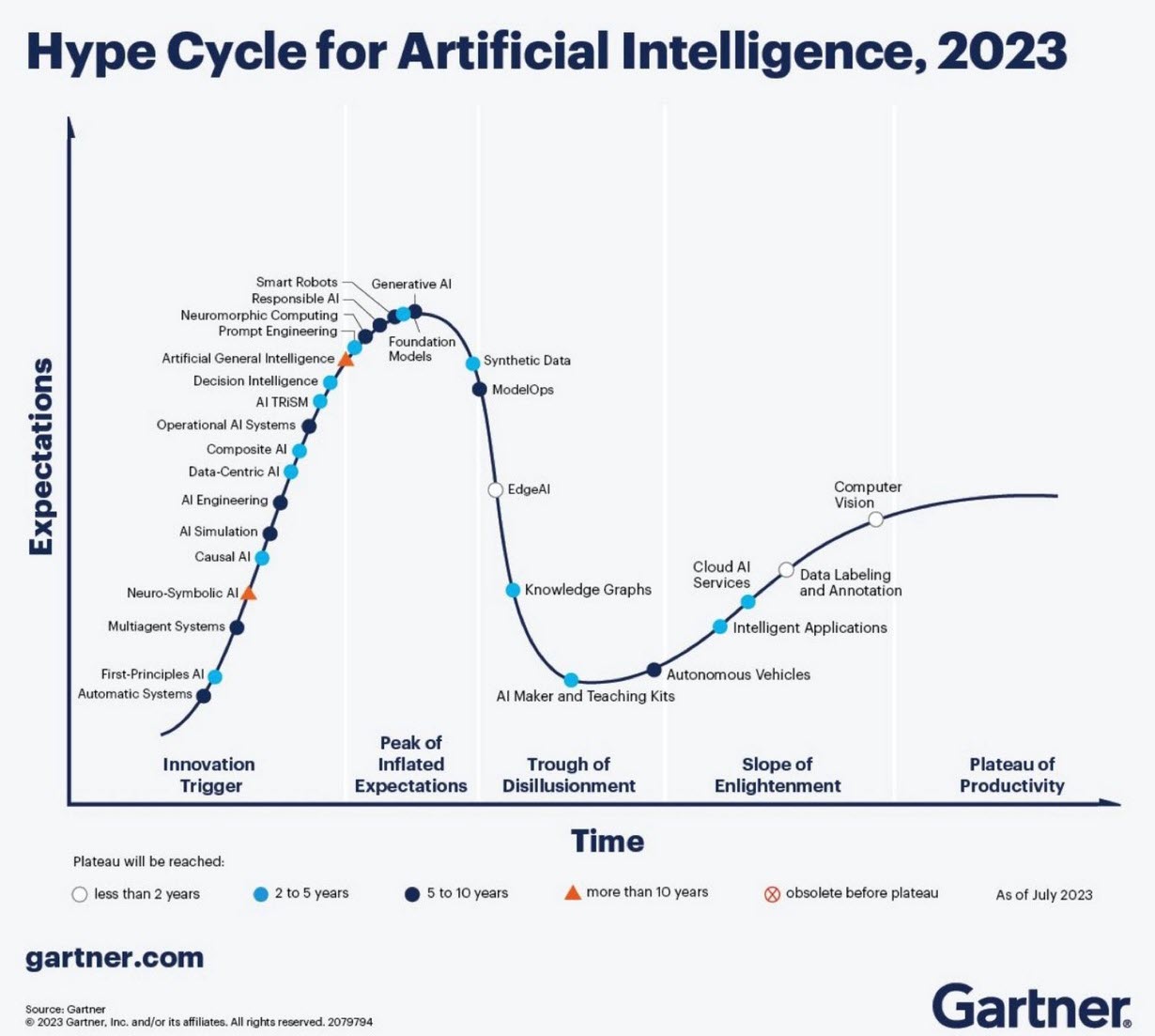
Where are you on the AI hype cycle ?
![]() In my first discussion with Rob Ferrone, the original Product Data PLuMber, we discussed the necessary foundation for implementing a Digital Thread or leveraging AI capabilities beyond the hype. This is important because all these concepts require data quality and data governance as essential elements.
In my first discussion with Rob Ferrone, the original Product Data PLuMber, we discussed the necessary foundation for implementing a Digital Thread or leveraging AI capabilities beyond the hype. This is important because all these concepts require data quality and data governance as essential elements.
If you missed part 1, here is the link: Data Quality and Data Governance – A hype?
 Rob, did you receive any feedback related to part 1? I spoke with a company that emphasized the importance of data quality; however, they were more interested in applying plasters, as they consider a broader approach too disruptive to their current business. Do you see similar situations?
Rob, did you receive any feedback related to part 1? I spoke with a company that emphasized the importance of data quality; however, they were more interested in applying plasters, as they consider a broader approach too disruptive to their current business. Do you see similar situations?
 Honestly, not much feedback. Data Governance isn’t as sexy or exciting as discussions on Designing, Engineering, Manufacturing, or PLM Technology. HOWEVER, as the saying goes, all roads lead to Rome, and all Digital Engineering discussions ultimately lead to data.
Honestly, not much feedback. Data Governance isn’t as sexy or exciting as discussions on Designing, Engineering, Manufacturing, or PLM Technology. HOWEVER, as the saying goes, all roads lead to Rome, and all Digital Engineering discussions ultimately lead to data.
Cristina Jimenez Pavo’s comment illustrates that the question is in the air.:
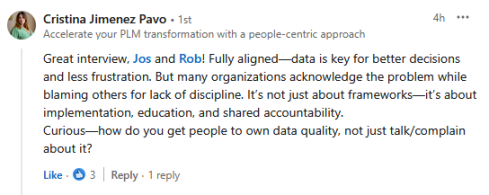
Everyone knows that it should be better; high-performing businesses have good data governance, but most people don’t know how to systematically and sustainably improve their data quality. It’s hard and not glamorous (for most), so people tend to focus on buying new systems, which they believe will magically resolve their underlying issues.
Data governance as a strategy
Thanks for the clarification. I imagine it is similar to Configuration Management, i.e., with different needs per industry. I have seen ISO 8000 in the aerospace industry, but it has not spread further to other businesses. What about data governance as a strategy, similar to CM?
That’s a great idea. Do you mind if I steal it?
If you ask any PLM or ERP vendor, they’ll claim to have a master product data governance template for every industry. While the core principles—ownership, control, quality, traceability, and change management, as in Configuration Management—are consistent, their application must vary based on the industry context, data types, and business priorities.
 Designing effective data governance involves tailoring foundational elements, including data stewardship, standards, lineage, metadata, glossaries, and quality rules. These elements must reflect the realities of operations, striking a balance between trade-offs such as speed versus rigor or openness versus control.
Designing effective data governance involves tailoring foundational elements, including data stewardship, standards, lineage, metadata, glossaries, and quality rules. These elements must reflect the realities of operations, striking a balance between trade-offs such as speed versus rigor or openness versus control.
The challenge is that both configuration management (CM) and data governance often suffer from a perception problem, being viewed as abstract or compliance-heavy. In truth, they must be practical, embedded in daily workflows, and treated as dynamic systems central to business operations, rather than static documents.
Think of it like the difference between stepping on a scale versus using a smartwatch that tracks your weight, heart rate, and activity, schedules workouts, suggests meals, and aligns with your goals.
![]() Governance should function the same way:
Governance should function the same way:
responsive, integrated, and outcome-driven.
Who is responsible for data quality?
I have seen companies simplifying data quality as an enhancement step for everyone in the organization, like a “You have to be more accurate” message, similar perhaps to configuration management. Here we touch people and organizational change. How do you make improving data quality happen beyond the wish?
In most companies, managing product data is a responsibility shared among all employees. But increasingly complex systems and processes are not designed around people, making the work challenging, unpleasant, and often poorly executed.
I like to quote Larry English – The Father of Information Quality:
“Information producers will create information only to the quality level for which they are trained, measured and held accountable.”
A common reaction is to add data “police” or transactional administrators, who unintentionally create more noise or burden those generating the data.
The real solution lies in embedding capable, proactive individuals throughout the product lifecycle who care about data quality as much as others care about the product itself – it was the topic I discussed at the 2025 Share PLM summit in Jerez – Rob Ferrone – Bill O-Materials also presented in part 1 of our discussion.
These data professionals collaborate closely with designers, engineers, procurement, manufacturing, supply chain, maintenance, and repair teams. They take ownership of data quality in systems, without relieving engineers of their responsibility for the accuracy of source data.

Some data, like component weight, is best owned by engineers, while others—such as BoM structure—may be better managed by system specialists. The emphasis should be on giving data professionals precise requirements and the authority to deliver.
They not only understand what good data looks like in their domain but also appreciate the needs of adjacent teams. This results in improved data quality across the business, not just within silos. They also work with IT and process teams to manage system changes and lead continuous improvement efforts.
![]() The real challenge is finding leaders with the vision and drive to implement this approach.
The real challenge is finding leaders with the vision and drive to implement this approach.

The costs or benefits associated with good or poor data quality
At the peak of interest in being data-driven, large consulting firms published numerous studies and analyses, proving that data-driven companies achieve better results than their data-averse competitors. Have you seen situations where the business case for improving “product data” quality has led to noticeable business benefits, and if so, in what range? Double digit, single digit?
Improving data quality in isolation delivers limited value. Data quality is a means to an end. To realise real benefits, you must not only know how to improve it, but also how to utilise high-quality data in conjunction with other levers to drive improved business outcomes.
I built a company whose premise was that good-quality product data flowing efficiently throughout the business delivered dividends due to improved business performance. We grew because we delivered results that outweighed our fees.

Last year’s turnover was €35M, so even with a conservatively estimated average in-year ROI of 3:1, the company delivered over € 100 M of cost savings or additional revenue per year to clients, with the majority of these benefits being sustainable.
There is also the potential to unlock new value and business models through data-driven innovation.
 For example, connecting disparate product data sources into a unified view and taking steps to sustainably improve data quality enables faster, more accurate, and easier collaboration between OEMs, fleet operators, spare parts providers, workshops, and product users, which leads to a new value proposition around minimizing painful operational downtime.
For example, connecting disparate product data sources into a unified view and taking steps to sustainably improve data quality enables faster, more accurate, and easier collaboration between OEMs, fleet operators, spare parts providers, workshops, and product users, which leads to a new value proposition around minimizing painful operational downtime.
AI and Data Quality
Currently, we are seeing numerous concepts emerge where AI, particularly AI agents, can be highly valuable for PLM. However, we also know that in legacy environments, the overall quality of data is poor. How do you envision AI supporting PLM processes, and where should you start? Or has it already started?
It’s like mining for rare elements—sifting through massive amounts of legacy data to find the diamonds. Is it worth the effort, especially when diamonds can now be manufactured? AI certainly makes the task faster and easier. Interestingly, Elon Musk recently announced plans to use AI to rewrite legacy data and create a new, high-quality knowledge base. This suggests a potential market for trusted, validated, and industry-specific legacy training data.
Will OEMs sell it as valuable IP, or will it be made open source like Tesla’s patents?
 AI also offers enormous potential for data quality and governance. From live monitoring to proactive guidance, adopting this approach will become a much easier business strategy. One can imagine AI forming the core of a company’s Digital Thread—no longer requiring rigidly hardwired systems and data flows, but instead intelligently comparing team data and flagging misalignments.
AI also offers enormous potential for data quality and governance. From live monitoring to proactive guidance, adopting this approach will become a much easier business strategy. One can imagine AI forming the core of a company’s Digital Thread—no longer requiring rigidly hardwired systems and data flows, but instead intelligently comparing team data and flagging misalignments.
That said, data alignment remains complex, as discrepancies can be valid depending on context.
A practical starting point?
Data Quality as a Service. My former company, Quick Release, is piloting an AI-enabled service focused on EBoM to MBoM alignment. It combines a data quality platform with expert knowledge, collecting metadata from PLM, ERP, MES, and other systems to map engineering data models.
 Experts define quality rules (completeness, consistency, relationship integrity), and AI enables automated anomaly detection. Initially, humans triage issues, but over time, as trust in AI grows, more of the process can be automated. Eventually, no oversight may be needed; alerts could be sent directly to those empowered to act, whether human or AI.
Experts define quality rules (completeness, consistency, relationship integrity), and AI enables automated anomaly detection. Initially, humans triage issues, but over time, as trust in AI grows, more of the process can be automated. Eventually, no oversight may be needed; alerts could be sent directly to those empowered to act, whether human or AI.
Summary
We hope the discussions in parts 1 and 2 helped you understand where to begin. It doesn’t need to stay theoretical or feel unachievable.
- The first step is simple: recognise product data as an asset that powers performance, not just admin.
Then treat it accordingly. - You don’t need a 5-year roadmap or a board-approved strategy before you begin. Start by identifying the product data that supports your most critical workflows, the stuff that breaks things when it’s wrong or missing. Work out what “good enough” looks like for that data at each phase of the lifecycle.
Then look around your business: who owns it, who touches it, and who cares when it fails? - From there, establish the roles, rules, and routines that help this data improve over time, even if it’s manual and messy to begin with. Add tooling where it helps.
- Use quality KPIs that reflect the business, not the system. Focus your governance efforts where there’s friction, waste, or rework.
- And where are you already getting value? Lock it in. Scale what works.
Conclusion
It’s not about perfection or policies; it’s about momentum and value. Data quality is a lever. Data governance is how you pull it.
Just start pulling- and then get serious with your AI applications!

Are you attending the PLM Roadmap/PDT Europe 2025 conference on
November 5th & 6th in Paris, La Defense?
There is an opportunity to discuss the future of PLM in a workshop before the event.
More information will be shared soon; please mark November 4th in the afternoon on your agenda.
The title of this post is chosen influenced by one of Jan Bosch’s daily reflections # 156: Hype-as-a-Service. You can read his full reflection here.

His post reminded me of a topic that I frequently mention when discussing modern PLM concepts with companies and peers in my network. Data Quality and Data Governance, sometimes, in the context of the connected digital thread, and more recently, about the application of AI in the PLM domain.
I’ve noticed that when I emphasize the importance of data quality and data governance, there is always a lot of agreement from the audience. However, when discussing these topics with companies, the details become vague.
Yes, there is a desire to improve data quality, and yes, we push our people to improve the quality processes of the information they produce. Still, I was curious if there is an overall strategy for companies.
And who to best talk to? Rob Ferrone, well known as “The original Product Data PLuMber” – together, we will discuss the topic of data quality and governance in two posts. Here is part one – defining the playground.
The need for Product Data People
During the Share PLM Summit, I was inspired by Rob’s theatre play, “The Engineering Murder Mystery.” Thanks to the presence of Michael Finocchiaro, you might have seen the play already on LinkedIn – if you have 20 minutes, watch it now.
Rob’s ultimate plea was to add product data people to your company to make the data reliable and flow. So, for me, he is the person to understand what we mean by data quality and data governance in reality – or is it still hype?
What is data?
Hi Rob, thank you for having this conversation. Before discussing quality and governance, could you share with us what you consider ‘data’ within our PLM scope? Is it all the data we can imagine?
I propose that relevant PLM data encompasses all product-related information across the lifecycle, from conception to retirement. Core data includes part or item details, usage, function, revision/version, effectivity, suppliers, attributes (e.g., cost, weight, material), specifications, lifecycle state, configuration, and serial number.
Secondary data supports lifecycle stages and includes requirements, structure, simulation results, release dates, orders, delivery tracking, validation reports, documentation, change history, inventory, and repair data.
Tertiary data, such as customer information, can provide valuable support for marketing or design insights. HR data is generally outside the scope, although it may be referenced when evaluating the impact of PLM on engineering resources.
What is data quality?
Now that we have a data scope in mind, I can imagine that there is also some nuance in the term’ data quality’. Do we strive for 100% correct data, and is the term “100 % correct” perhaps too ambitious? How would you define and address data quality?
You shouldn’t just want data quality for data quality’s sake. You should want it because your business processes depend on it. As for 100%, not all data needs to be accurate and available simultaneously. It’s about having the proper maturity of data at the right time.
For example, when you begin designing a component, you may not need to have a nominated supplier, and estimated costs may be sufficient. However, missing supplier nomination or estimated costs would count against data quality when it is time to order parts.
And these deliverable timings will vary across components, so 100% quality might only be achieved when the last standard part has been identified and ordered.
It is more important to know when you have reached the required data quality objective for the top-priority content. The image below explains the data quality dimensions:
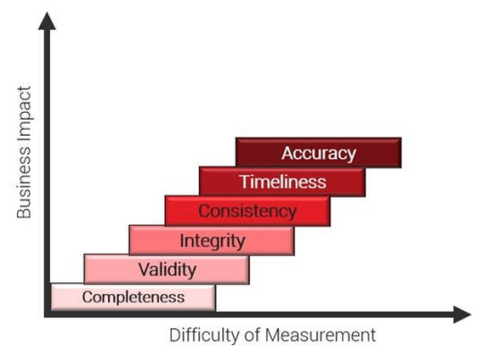
- Completeness (Are all required fields filled in?)
KPI Example: % of product records that include all mandatory fields (e.g., part number, description, lifecycle status, unit of measure)
- Validity (Do values conform to expected formats, rules, or domains?)
KPI Example: % of customer addresses that conform to ISO 3166 country codes and contain no invalid characters
- Integrity (Do relationships between data records hold?)
KPI Example: % of BOM records where all child parts exist in the Parts Master and are not marked obsolete
- Consistency (Is data consistent across systems or domains?)
KPI Example: % of product IDs with matching descriptions and units across PLM and ERP systems
- Timeliness (Is data available and updated when needed?)
KPI Example: % of change records updated within 24 hours of approval or effective date
- Accuracy (Does the data reflect real-world truth?)
KPI Example: % of asset location records that match actual GPS coordinates from service technician visits
Define data quality KPIs based on business process needs, ensuring they drive meaningful actions aligned with project goals.
 While defining quality is one challenge, detecting issues is another. Data quality problems vary in severity and detection difficulty, and their importance can shift depending on the development stage. It’s vital not to prioritize one measure over others, e.g., having timely data doesn’t guarantee that it has been validated.
While defining quality is one challenge, detecting issues is another. Data quality problems vary in severity and detection difficulty, and their importance can shift depending on the development stage. It’s vital not to prioritize one measure over others, e.g., having timely data doesn’t guarantee that it has been validated.
Like the VUCA framework, effective data quality management begins by understanding the nature of the issue: is it volatile, uncertain, complex, or ambiguous?
Not all “bad” data is flawed, some may be valid estimates, changes, or system-driven anomalies. Each scenario requires a tailored response; treating all issues the same can lead to wasted effort or overlooked insights.
Furthermore, data quality goes beyond the data itself—it also depends on clear definitions, ownership, monitoring, maintenance, and governance. A holistic approach ensures more accurate insights and better decision-making throughout the product lifecycle.
KPIs?
In many (smaller) companies KPI do not exist; they adjust their business based on experience and financial results. Are companies ready for these KPIs, or do they need to establish a data governance baseline first?
Many companies already use data to run parts of their business, often with little or no data governance. They may track program progress, but rarely systematically monitor data quality. Attention tends to focus on specific data types during certain project phases, often employing audits or spot checks without establishing baselines or implementing continuous monitoring.
This reactive approach means issues are only addressed once they cause visible problems.
When data problems emerge, trust in the system declines. Teams revert to offline analysis, build parallel reports, and generate conflicting data versions. A lack of trust worsens data quality and wastes time resolving discrepancies, making it difficult to restore confidence. Leaders begin to question whether the data can be trusted at all.
 Data governance typically evolves; it’s challenging to implement from the start. Organizations must understand their operations before they can govern data effectively.
Data governance typically evolves; it’s challenging to implement from the start. Organizations must understand their operations before they can govern data effectively.
In start-ups, governance is challenging. While they benefit from a clean slate, their fast-paced, prototype-driven environment prioritizes innovation over stable governance. Unlike established OEMs with mature processes, start-ups focus on agility and innovation, making it challenging to implement structured governance in the early stages.
Data governance is a business strategy, similar to Product Lifecycle Management.
Before they go on the journey of creating data management capabilities, companies must first understand:
- The cost of not doing it.
- The value of doing it.
- The cost of doing it.
What is the cost associated with not doing data quality and governance?
Similar to configuration management, companies might find it a bureaucratic overhead that is hard to justify. As long as things are going well (enough) and the company’s revenue or reputation is not at risk, why add this extra work?
Product data quality is either a tax or a dividend. In Part 2, I will discuss the benefits. In Part 1, this discussion, I will focus on the cost of not doing it.
Every business has stories of costly failures caused by incorrect part orders, uncommunicated changes, or outdated service catalogs. It’s a systematic disease in modern, complex organisations. It’s part of our day-to-day working lives: multiple files with slightly different file names, important data hidden in lengthy email chains, and various sources for the same information (where the value differs across sources), among other challenges.

Above image from Susan Lauda’s presentation at the PLMx 2018 conference in Hamburg, where she shared the hidden costs of poor data. Please read about it in my blog post: The weekend after PLMx Hamburg.
Poor product data can impact more than most teams realize. It wastes time—people chase missing info, duplicate work, and rerun reports. It delays builds, decisions, and delivery, hurting timelines and eroding trust. Quality drops due to incorrect specifications, resulting in rework and field issues. Financial costs manifest as scrap, excess inventory, freight, warranty claims, and lost revenue.
Worse, poor data leads to poor decisions, wrong platforms, bad supplier calls, and unrealistic timelines. It also creates compliance risks and traceability gaps that can trigger legal trouble. When supply chain visibility is lost, the consequences aren’t just internal, they become public.
For example, in Tony’s Chocolonely’s case, despite their ethical positioning, they were removed from the Slave Free Chocolate list after 1,700 child labour cases were discovered in their supplier network.
The good news is that most of the unwanted costs are preventable. There are often very early indicators that something was going to be a problem. They are just not being looked at.
Better data governance equals better decision-making power.
Visibility prevents the inevitable.
Conclusion of part 1
Thanks to Rob’s answers, I am confident that you now have a better understanding of what Data Quality and Data Governance mean in the context of your business. In addition, we discussed the cost of doing nothing. In Part 2, we will explore how to implement it in your company, and Rob will share some examples of the benefits.
Feel free to post your questions for the original Product Data PLuMber in the comments.
Four years ago, during the COVID-19 pandemic, we discussed the critical role of a data plumber.

Interesting reflection, Jos. In my experience, the situation you describe is very recognizable. At the company where I work, sustainability…
[…] (The following post from PLM Green Global Alliance cofounder Jos Voskuil first appeared in his European PLM-focused blog HERE.) […]
[…] recent discussions in the PLM ecosystem, including PSC Transition Technologies (EcoPLM), CIMPA PLM services (LCA), and the Design for…
Jos, all interesting and relevant. There are additional elements to be mentioned and Ontologies seem to be one of the…
Jos, as usual, you've provided a buffet of "food for thought". Where do you see AI being trained by a…